 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Estimation in RIS-Enabled mmWave Wireless Systems: A Variational Inference Approach
Aug 25, 2023



We propose a variational inference (VI)-based channel state information (CSI) estimation approach in a fully-passive reconfigurable intelligent surface (RIS)-aided mmWave single-user single-input multiple-output (SIMO) communication system. Specifically, we first propose a VI-based joint channel estimation method to estimate the user-equipment (UE) to RIS (UE-RIS) and RIS to base station (RIS-BS) channels using uplink training signals in a passive RIS setup. However, updating the phase-shifts based on the instantaneous CSI (I-CSI) leads to a high signaling overhead especially due to the short coherence block of the UE-RIS channel. Therefore, to reduce the signaling complexity, we propose a VI-based method to estimate the RIS-BS channel along with the covariance matrix of the UE-RIS channel that remains quasi-static for a longer period than the instantaneous UE-RIS channel. In the VI framework, we approximate the posterior of the channel gains/covariance matrix with convenient distributions given the received uplink training signals. Then, the learned distributions, which are close to the true posterior distributions in terms of Kullback-Leibler divergence, are leveraged to obtain the maximum a posteriori (MAP) estimation of the considered CSI. The simulation results demonstrate that MAP channel estimation using approximated posteriors yields a capacity that is close to the one achieved with true posteriors, thus demonstrating the effectiveness of the proposed methods. Furthermore, our results show that estimating the channel covariance matrix improves the spectral efficiency by reducing the pilot signaling required to obtain the phase-shifts for the RIS elements in a channel-varying environment.
Distributed Uplink Beamforming in Cell-Free Networks Using Deep Reinforcement Learning
Jun 26, 2020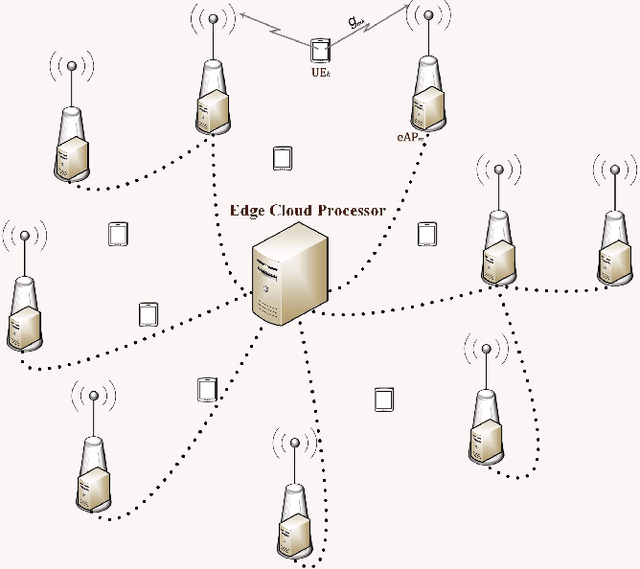
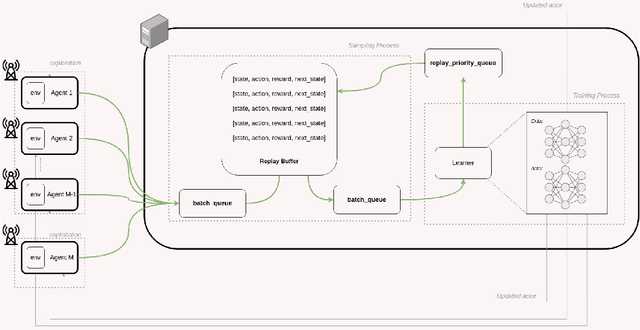
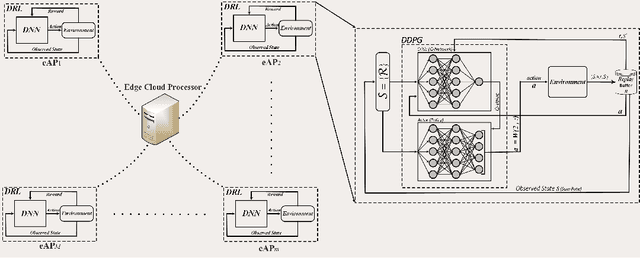
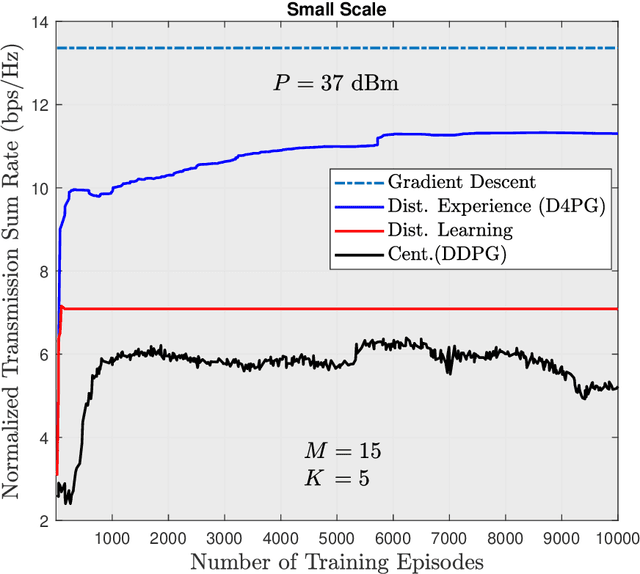
The emergence of new wireless technologies together with the requirement of massive connectivity results in several technical issues such as excessive interference, high computational demand for signal processing, and lengthy processing delays. In this work, we propose several beamforming techniques for an uplink cell-free network with centralized, semi-distributed, and fully distributed processing, all based on deep reinforcement learning (DRL). First, we propose a fully centralized beamforming method that uses the deep deterministic policy gradient algorithm (DDPG) with continuous space. We then enhance this method by enabling distributed experience at access points (AP). Indeed, we develop a beamforming scheme that uses the distributed distributional deterministic policy gradients algorithm (D4PG) with the APs representing the distributed agents. Finally, to decrease the computational complexity, we propose a fully distributed beamforming scheme that divides the beamforming computations among APs. The results show that the D4PG scheme with distributed experience achieves the best performance irrespective of the network size. Furthermore, the proposed distributed beamforming technique performs better than the DDPG algorithm with centralized learning only for small-scale networks. The performance superiority of the DDPG model becomes more evident as the number of APs and/or users increases. Moreover, during the operation stage, all DRL models demonstrate a significantly shorter processing time than that of the conventional gradient descent (GD) solution.