 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Forecasting of Deep Learning Performance on GPUs
Jul 18, 2024Deep learning kernels exhibit predictable memory accesses and compute patterns, making GPUs' parallel architecture well-suited for their execution. Software and runtime systems for GPUs are optimized to better utilize the stream multiprocessors, on-chip cache, and off-chip high-bandwidth memory. As deep learning models and GPUs evolve, access to newer GPUs is often limited, raising questions about the performance of new model architectures on existing GPUs, existing models on new GPUs, and new model architectures on new GPUs. To address these questions, we introduce NeuSight, a framework to predict the performance of various deep learning models, for both training and inference, on unseen GPUs without requiring actual execution. The framework leverages both GPU hardware behavior and software library optimizations to estimate end-to-end performance. Previous work uses regression models that capture linear trends or multilayer perceptrons to predict the overall latency of deep learning kernels on GPUs. These approaches suffer from higher error percentages when forecasting performance on unseen models and new GPUs. Instead, NeuSight decomposes the prediction problem into smaller problems, bounding the prediction through fundamental performance laws. NeuSight decomposes a single deep learning kernel prediction into smaller working sets called tiles, which are executed independently on the GPU. Tile-granularity predictions are determined using a machine learning approach and aggregated to estimate end-to-end latency. NeuSight outperforms prior work across various deep learning workloads and the latest GPUs. It reduces the percentage error from 198% and 19.7% to 3.8% in predicting the latency of GPT3 model for training and inference on H100, compared to state-of-the-art prior works, where both GPT3 and H100 were not used to train the framework.
Integrated Hardware Architecture and Device Placement Search
Jul 18, 2024



Distributed execution of deep learning training involves a dynamic interplay between hardware accelerator architecture and device placement strategy. This is the first work to explore the co-optimization of determining the optimal architecture and device placement strategy through novel algorithms, improving the balance of computational resources, memory usage, and data distribution. Our architecture search leverages tensor and vector units, determining their quantity and dimensionality, and on-chip and off-chip memory configurations. It also determines the microbatch size and decides whether to recompute or stash activations, balancing the memory footprint of training and storage size. For each explored architecture configuration, we use an Integer Linear Program (ILP) to find the optimal schedule for executing operators on the accelerator. The ILP results then integrate with a dynamic programming solution to identify the most effective device placement strategy, combining data, pipeline, and tensor model parallelism across multiple accelerators. Our approach achieves higher throughput on large language models compared to the state-of-the-art TPUv4 and the Spotlight accelerator search framework. The entire source code of PHAZE is available at https://github.com/msr-fiddle/phaze.
Packrat: Automatic Reconfiguration for Latency Minimization in CPU-based DNN Serving
Nov 30, 2023



In this paper, we investigate how to push the performance limits of serving Deep Neural Network (DNN) models on CPU-based servers. Specifically, we observe that while intra-operator parallelism across multiple threads is an effective way to reduce inference latency, it provides diminishing returns. Our primary insight is that instead of running a single instance of a model with all available threads on a server, running multiple instances each with smaller batch sizes and fewer threads for intra-op parallelism can provide lower inference latency. However, the right configuration is hard to determine manually since it is workload- (DNN model and batch size used by the serving system) and deployment-dependent (number of CPU cores on server). We present Packrat, a new serving system for online inference that given a model and batch size ($B$) algorithmically picks the optimal number of instances ($i$), the number of threads each should be allocated ($t$), and the batch sizes each should operate on ($b$) that minimizes latency. Packrat is built as an extension to TorchServe and supports online reconfigurations to avoid serving downtime. Averaged across a range of batch sizes, Packrat improves inference latency by 1.43$\times$ to 1.83$\times$ on a range of commonly used DNNs.
A Study on the Intersection of GPU Utilization and CNN Inference
Dec 15, 2022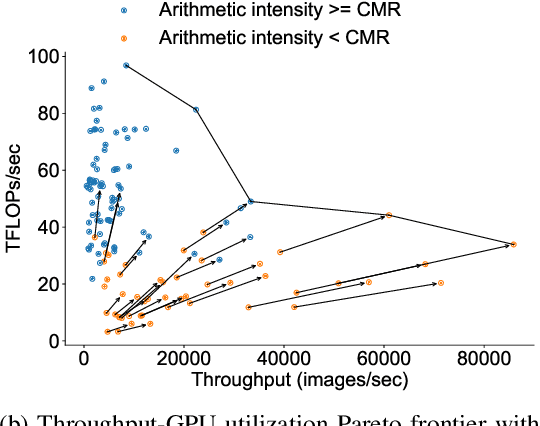
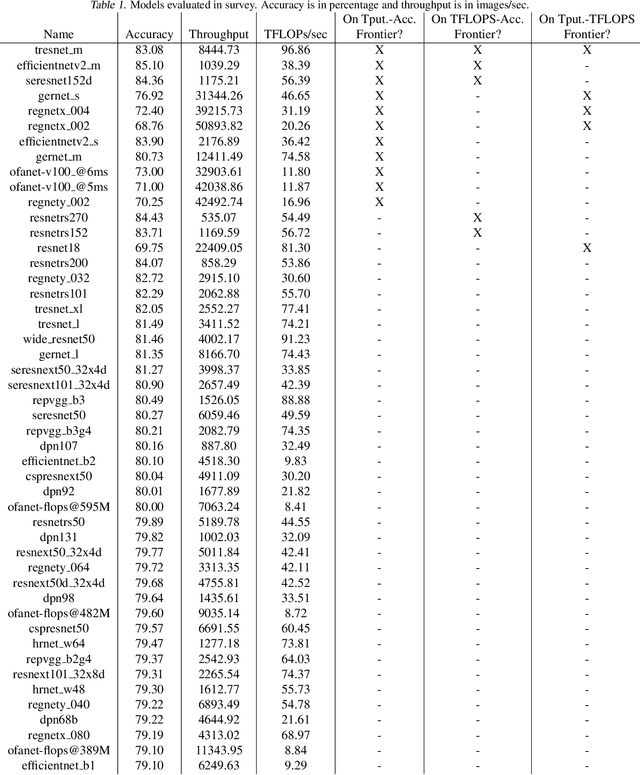
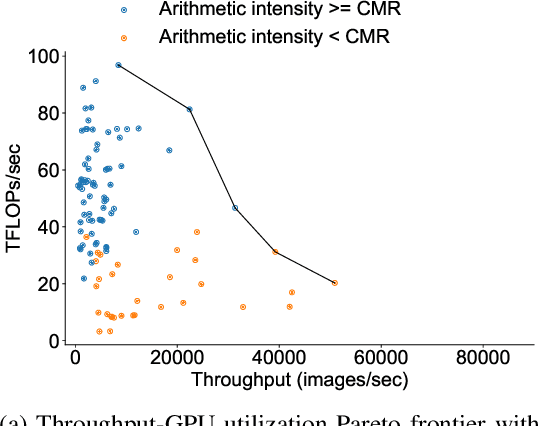
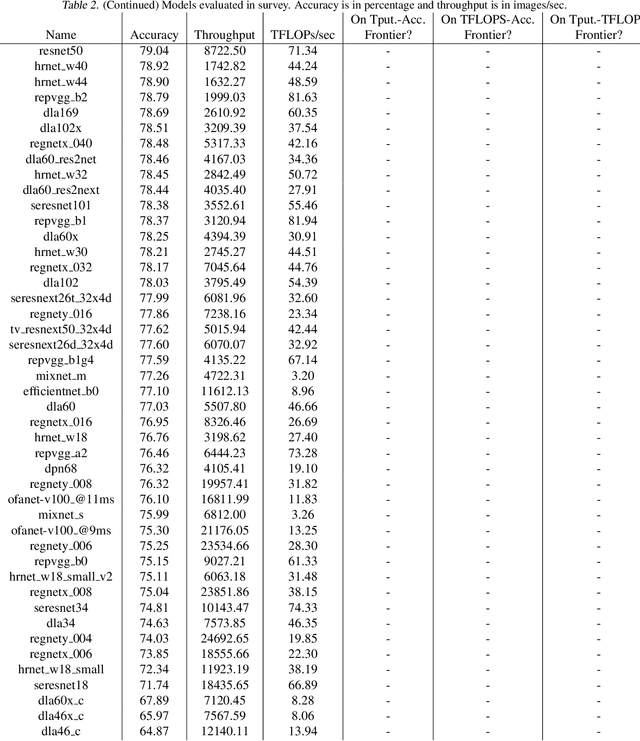
There has been significant progress in developing neural network architectures that both achieve high predictive performance and that also achieve high application-level inference throughput (e.g., frames per second). Another metric of increasing importance is GPU utilization during inference: the measurement of how well a deployed neural network uses the computational capabilities of the GPU on which it runs. Achieving high GPU utilization is critical to increasing application-level throughput and ensuring a good return on investment for deploying GPUs. This paper analyzes the GPU utilization of convolutional neural network (CNN) inference. We first survey the GPU utilization of CNNs to show that there is room to improve the GPU utilization of many of these CNNs. We then investigate the GPU utilization of networks within a neural architecture search (NAS) search space, and explore how using GPU utilization as a metric could potentially be used to accelerate NAS itself. Our study makes the case that there is room to improve the inference-time GPU utilization of CNNs and that knowledge of GPU utilization has the potential to benefit even applications that do not target utilization itself. We hope that the results of this study will spur future innovation in designing GPU-efficient neural networks.
Harmony: Overcoming the hurdles of GPU memory capacity to train massive DNN models on commodity servers
Feb 02, 2022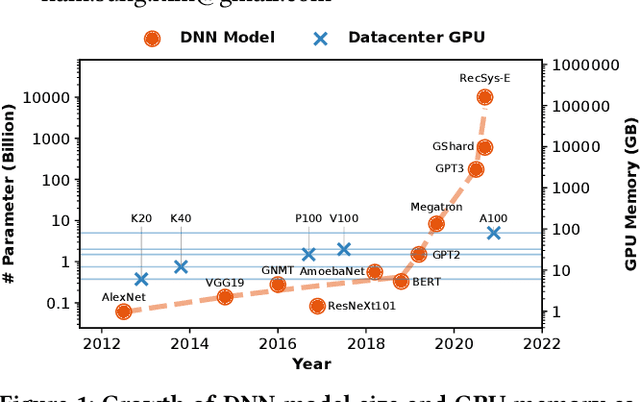
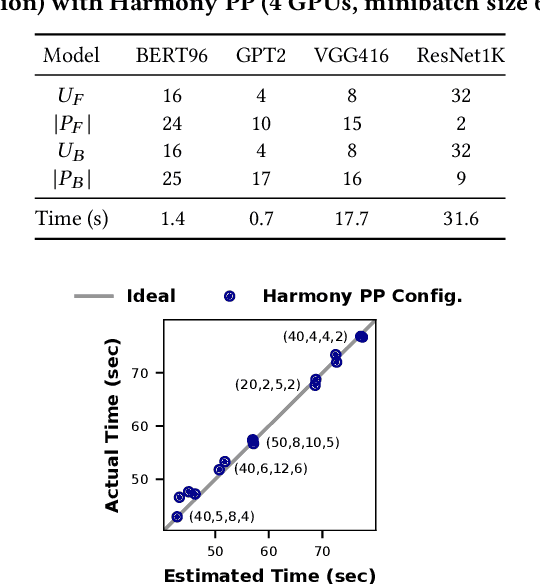
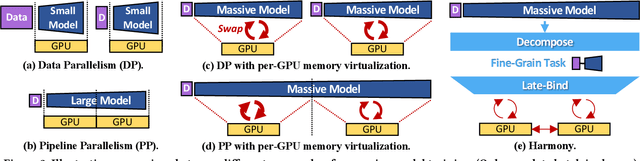
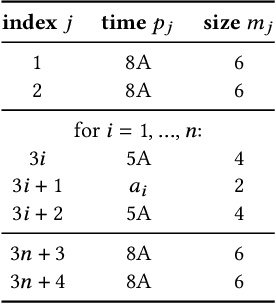
Deep neural networks (DNNs) have grown exponentially in complexity and size over the past decade, leaving only those who have access to massive datacenter-based resources with the ability to develop and train such models. One of the main challenges for the long tail of researchers who might have access to only limited resources (e.g., a single multi-GPU server) is limited GPU memory capacity compared to model size. The problem is so acute that the memory requirement of training large DNN models can often exceed the aggregate capacity of all available GPUs on commodity servers; this problem only gets worse with the trend of ever-growing model sizes. Current solutions that rely on virtualizing GPU memory (by swapping to/from CPU memory) incur excessive swapping overhead. In this paper, we present a new training framework, Harmony, and advocate rethinking how DNN frameworks schedule computation and move data to push the boundaries of training large models efficiently on modest multi-GPU deployments. Across many large DNN models, Harmony is able to reduce swap load by up to two orders of magnitude and obtain a training throughput speedup of up to 7.6x over highly optimized baselines with virtualized memory.
Synergy: Resource Sensitive DNN Scheduling in Multi-Tenant Clusters
Oct 12, 2021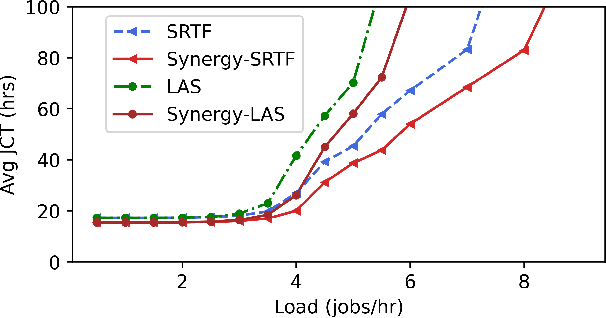
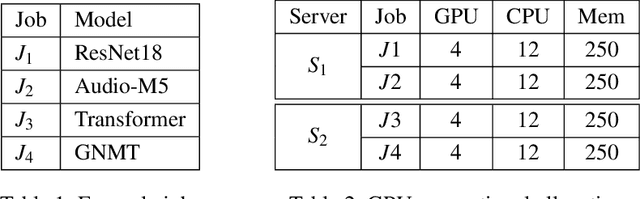
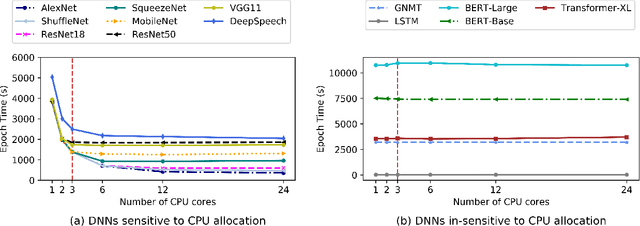
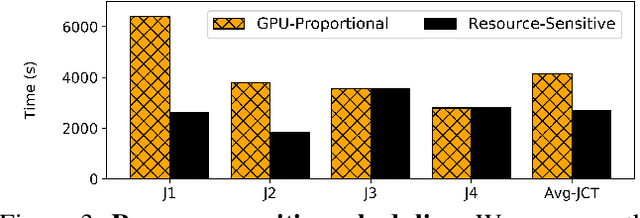
Training Deep Neural Networks (DNNs) is a widely popular workload in both enterprises and cloud data centers. Existing schedulers for DNN training consider GPU as the dominant resource, and allocate other resources such as CPU and memory proportional to the number of GPUs requested by the job. Unfortunately, these schedulers do not consider the impact of a job's sensitivity to allocation of CPU, memory, and storage resources. In this work, we propose Synergy, a resource-sensitive scheduler for shared GPU clusters. Synergy infers the sensitivity of DNNs to different resources using optimistic profiling; some jobs might benefit from more than the GPU-proportional allocation and some jobs might not be affected by less than GPU-proportional allocation. Synergy performs such multi-resource workload-aware assignments across a set of jobs scheduled on shared multi-tenant clusters using a new near-optimal online algorithm. Our experiments show that workload-aware CPU and memory allocations can improve average JCT up to 3.4x when compared to traditional GPU-proportional scheduling.
Efficient Large-Scale Language Model Training on GPU Clusters
Apr 09, 2021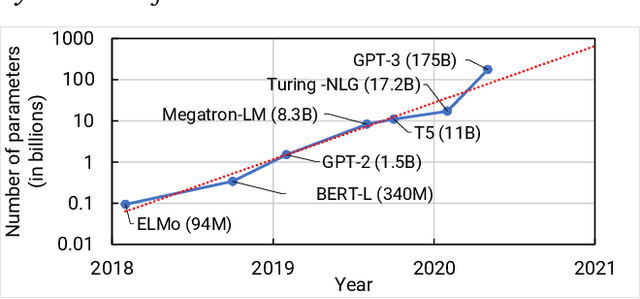
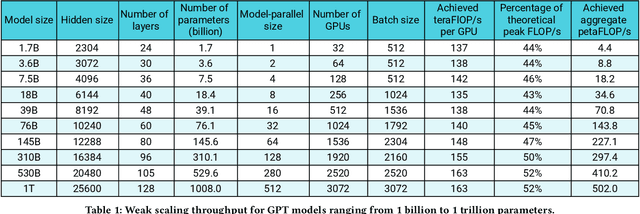
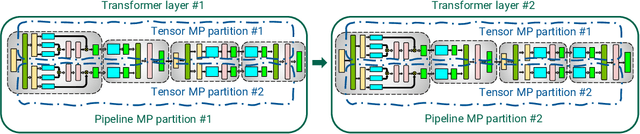
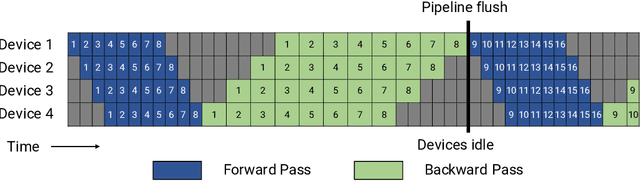
Large language models have led to state-of-the-art accuracies across a range of tasks. However, training these large models efficiently is challenging for two reasons: a) GPU memory capacity is limited, making it impossible to fit large models on a single GPU or even on a multi-GPU server; and b) the number of compute operations required to train these models can result in unrealistically long training times. New methods of model parallelism such as tensor and pipeline parallelism have been proposed to address these challenges; unfortunately, naive usage leads to fundamental scaling issues at thousands of GPUs due to various reasons, e.g., expensive cross-node communication or idle periods waiting on other devices. In this work, we show how to compose different types of parallelism methods (tensor, pipeline, and data paralleism) to scale to thousands of GPUs, achieving a two-order-of-magnitude increase in the sizes of models we can efficiently train compared to existing systems. We discuss various implementations of pipeline parallelism and propose a novel schedule that can improve throughput by more than 10% with comparable memory footprint compared to previously-proposed approaches. We quantitatively study the trade-offs between tensor, pipeline, and data parallelism, and provide intuition as to how to configure distributed training of a large model. The composition of these techniques allows us to perform training iterations on a model with 1 trillion parameters at 502 petaFLOP/s on 3072 GPUs with achieved per-GPU throughput of 52% of peak; previous efforts to train similar-sized models achieve much lower throughput (36% of theoretical peak). Our code has been open-sourced at https://github.com/nvidia/megatron-lm.
Analyzing and Mitigating Data Stalls in DNN Training
Jul 14, 2020
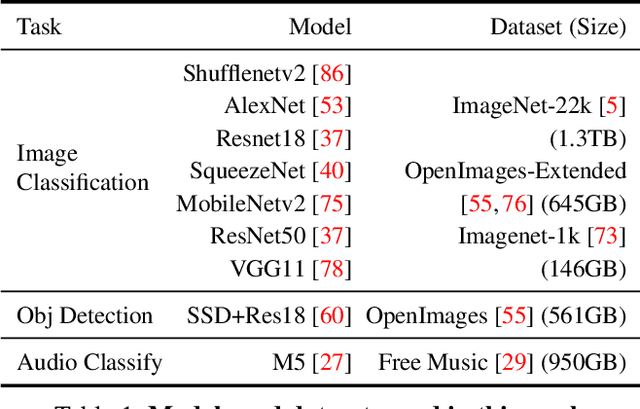
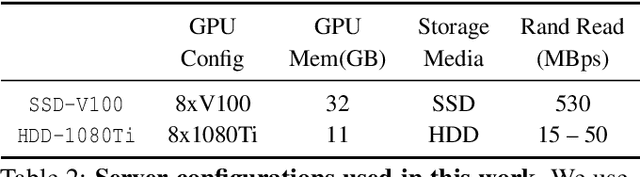
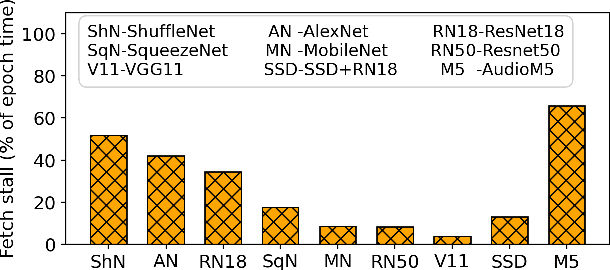
We present the first comprehensive analysis of how the data pipeline affects the training of the widely used Deep Neural Networks (DNNs). We analyze nine models and four datasets while varying factors such as the amount of memory, number of CPU threads, etc. We find that in many cases, DNN training time is dominated by data stall time: time spent waiting for data to be fetched from storage and pre-processed. Based on our insights, we build CoorDL, a novel data-loading library that accelerates DNN training by minimizing data stalls. CoorDL introduces three core techniques: coordinated pre-processing, partitioned caching, and DNN-aware software caching policy (MinIO). CoorDL does not affect training accuracy, and does not require special hardware support. CoorDL accelerates multiple aspects of DNN training: hyperparameter search, single-server training, and multi-server training. Our experiments on a range of DNN tasks, models, datasets, and hardware configurations show that CoorDL accelerates hyperparameter search by upto 5.7x, single-server training by upto 2x, and multi-server training by upto 15x compared to the state-of-the-art data loading library DALI on PyTorch.
Efficient Algorithms for Device Placement of DNN Graph Operators
Jun 29, 2020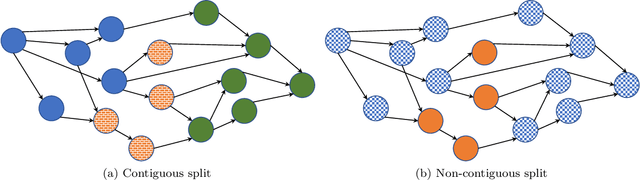
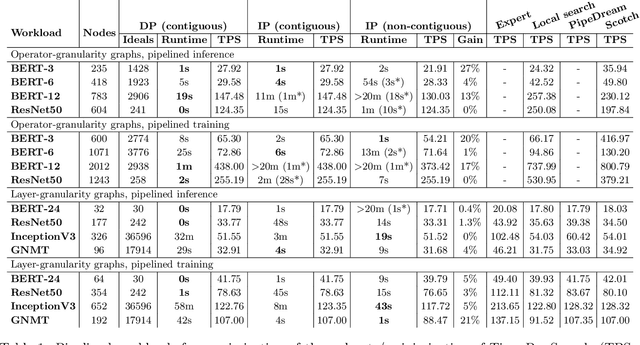

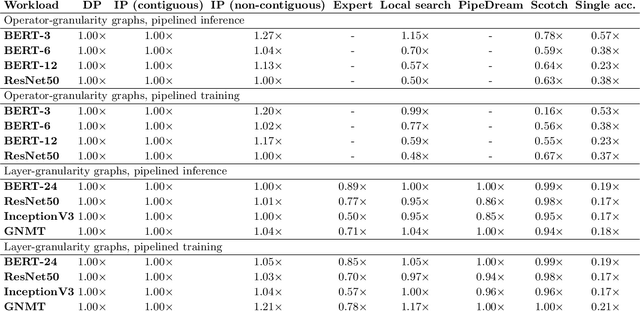
Modern machine learning workloads use large models, with complex structures, that are very expensive to execute. The devices that execute complex models are becoming increasingly heterogeneous as we see a flourishing of domain-specific accelerators being offered as hardware accelerators in addition to CPUs. These trends necessitate distributing the workload across multiple devices. Recent work has shown that significant gains can be obtained with model parallelism, i.e, partitioning a neural network's computational graph onto multiple devices. In particular, this form of parallelism assumes a pipeline of devices, which is fed a stream of samples and yields high throughput for training and inference of DNNs. However, for such settings (large models and multiple heterogeneous devices), we require automated algorithms and toolchains that can partition the ML workload across devices. In this paper, we identify and isolate the structured optimization problem at the core of device placement of DNN operators, for both inference and training, especially in modern pipelined settings. We then provide algorithms that solve this problem to optimality. We demonstrate the applicability and efficiency of our approaches using several contemporary DNN computation graphs.
Memory-Efficient Pipeline-Parallel DNN Training
Jun 16, 2020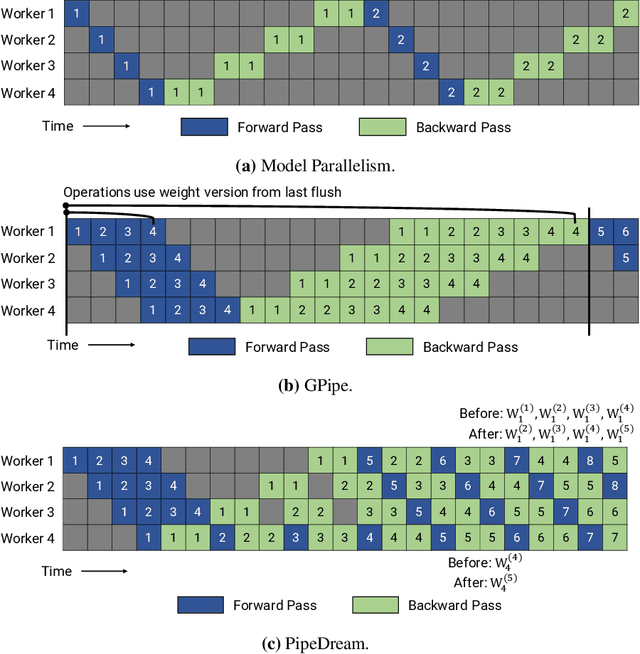
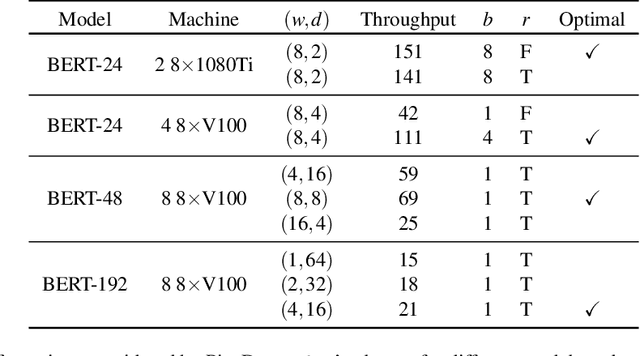
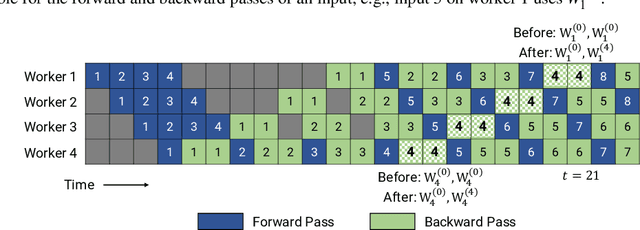
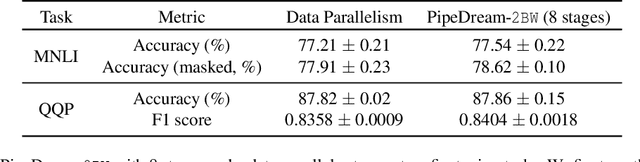
Many state-of-the-art results in domains such as NLP and computer vision have been obtained by scaling up the number of parameters in existing models. However, the weight parameters and intermediate outputs of these large models often do not fit in the main memory of a single accelerator device; this means that it is necessary to use multiple accelerators to train large models, which is challenging to do in a time-efficient way. In this work, we propose PipeDream-2BW, a system that performs memory-efficient pipeline parallelism, a hybrid form of parallelism that combines data and model parallelism with input pipelining. Our system uses a novel pipelining and weight gradient coalescing strategy, combined with the double buffering of weights, to ensure high throughput, low memory footprint, and weight update semantics similar to data parallelism. In addition, PipeDream-2BW automatically partitions the model over the available hardware resources, while being cognizant of constraints such as compute capabilities, memory capacities, and interconnect topologies, and determines when to employ existing memory-savings techniques, such as activation recomputation, that trade off extra computation for lower memory footprint. PipeDream-2BW is able to accelerate the training of large language models with up to 2.5 billion parameters by up to 6.9x compared to optimized baselines.