 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeveScale-FSDP: Flexible and High-Performance FSDP at Scale
Feb 25, 2026Fully Sharded Data Parallel (FSDP), also known as ZeRO, is widely used for training large-scale models, featuring its flexibility and minimal intrusion on model code. However, current FSDP systems struggle with structure-aware training methods (e.g., block-wise quantized training) and with non-element-wise optimizers (e.g., Shampoo and Muon) used in cutting-edge models (e.g., Gemini, Kimi K2). FSDP's fixed element- or row-wise sharding formats conflict with the block-structured computations. In addition, today's implementations fall short in communication and memory efficiency, limiting scaling to tens of thousands of GPUs. We introduce veScale-FSDP, a redesigned FSDP system that couples a flexible sharding format, RaggedShard, with a structure-aware planning algorithm to deliver both flexibility and performance at scale. veScale-FSDP natively supports efficient data placement required by FSDP, empowering block-wise quantization and non-element-wise optimizers. As a result, veScale-FSDP achieves 5~66% higher throughput and 16~30% lower memory usage than existing FSDP systems, while scaling efficiently to tens of thousands of GPUs.
BNS-GCN: Efficient Full-Graph Training of Graph Convolutional Networks with Partition-Parallelism and Random Boundary Node Sampling
Mar 26, 2022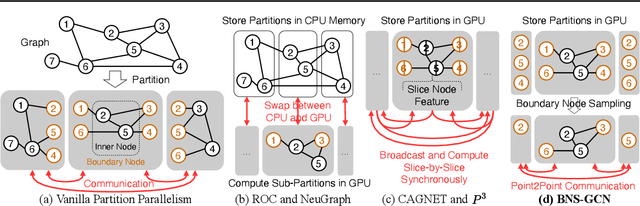

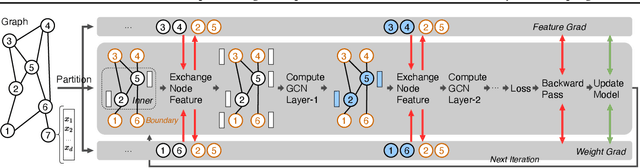

Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art method for graph-based learning tasks. However, training GCNs at scale is still challenging, hindering both the exploration of more sophisticated GCN architectures and their applications to real-world large graphs. While it might be natural to consider graph partition and distributed training for tackling this challenge, this direction has only been slightly scratched the surface in the previous works due to the limitations of existing designs. In this work, we first analyze why distributed GCN training is ineffective and identify the underlying cause to be the excessive number of boundary nodes of each partitioned subgraph, which easily explodes the memory and communication costs for GCN training. Furthermore, we propose a simple yet effective method dubbed BNS-GCN that adopts random Boundary-Node-Sampling to enable efficient and scalable distributed GCN training. Experiments and ablation studies consistently validate the effectiveness of BNS-GCN, e.g., boosting the throughput by up to 16.2x and reducing the memory usage by up to 58%, while maintaining a full-graph accuracy. Furthermore, both theoretical and empirical analysis show that BNS-GCN enjoys a better convergence than existing sampling-based methods. We believe that our BNS-GCN has opened up a new paradigm for enabling GCN training at scale. The code is available at https://github.com/RICE-EIC/BNS-GCN.
PipeGCN: Efficient Full-Graph Training of Graph Convolutional Networks with Pipelined Feature Communication
Mar 20, 2022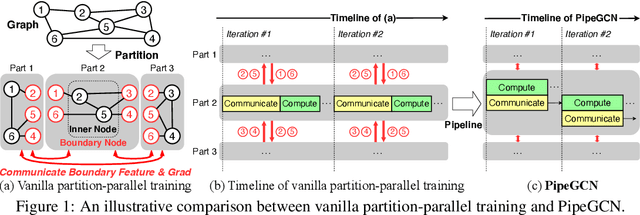

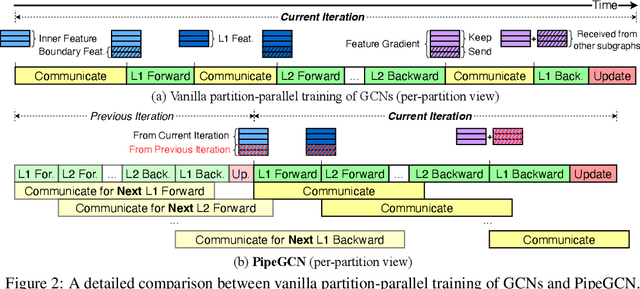

Graph Convolutional Networks (GCNs) is the state-of-the-art method for learning graph-structured data, and training large-scale GCNs requires distributed training across multiple accelerators such that each accelerator is able to hold a partitioned subgraph. However, distributed GCN training incurs prohibitive overhead of communicating node features and feature gradients among partitions for every GCN layer during each training iteration, limiting the achievable training efficiency and model scalability. To this end, we propose PipeGCN, a simple yet effective scheme that hides the communication overhead by pipelining inter-partition communication with intra-partition computation. It is non-trivial to pipeline for efficient GCN training, as communicated node features/gradients will become stale and thus can harm the convergence, negating the pipeline benefit. Notably, little is known regarding the convergence rate of GCN training with both stale features and stale feature gradients. This work not only provides a theoretical convergence analysis but also finds the convergence rate of PipeGCN to be close to that of the vanilla distributed GCN training without any staleness. Furthermore, we develop a smoothing method to further improve PipeGCN's convergence. Extensive experiments show that PipeGCN can largely boost the training throughput (1.7x~28.5x) while achieving the same accuracy as its vanilla counterpart and existing full-graph training methods. The code is available at https://github.com/RICE-EIC/PipeGCN.
Harmony: Overcoming the hurdles of GPU memory capacity to train massive DNN models on commodity servers
Feb 02, 2022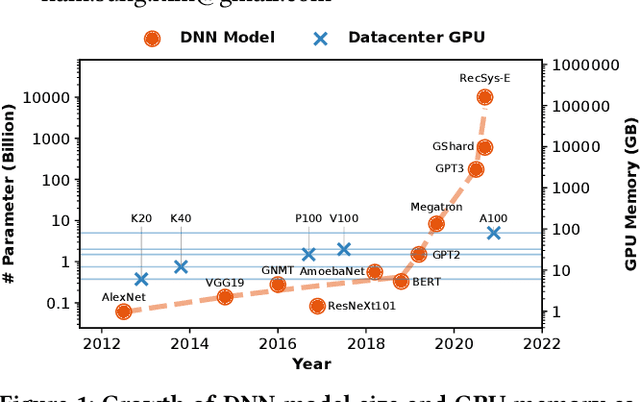
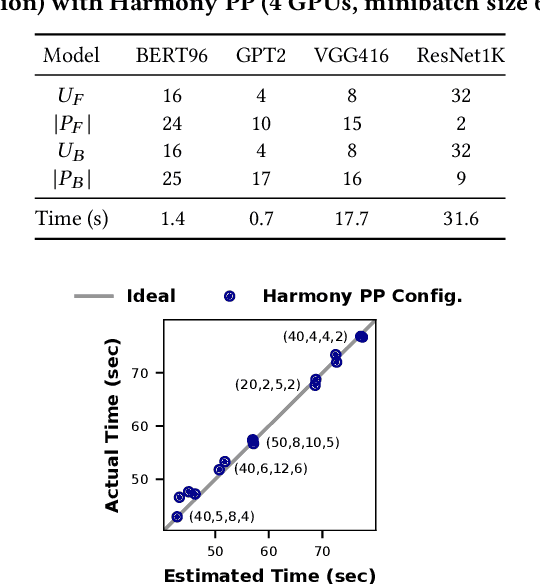
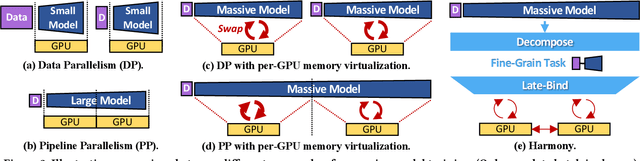
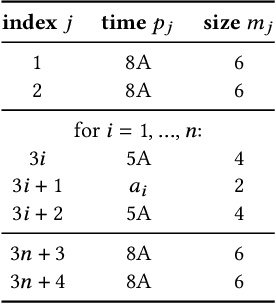
Deep neural networks (DNNs) have grown exponentially in complexity and size over the past decade, leaving only those who have access to massive datacenter-based resources with the ability to develop and train such models. One of the main challenges for the long tail of researchers who might have access to only limited resources (e.g., a single multi-GPU server) is limited GPU memory capacity compared to model size. The problem is so acute that the memory requirement of training large DNN models can often exceed the aggregate capacity of all available GPUs on commodity servers; this problem only gets worse with the trend of ever-growing model sizes. Current solutions that rely on virtualizing GPU memory (by swapping to/from CPU memory) incur excessive swapping overhead. In this paper, we present a new training framework, Harmony, and advocate rethinking how DNN frameworks schedule computation and move data to push the boundaries of training large models efficiently on modest multi-GPU deployments. Across many large DNN models, Harmony is able to reduce swap load by up to two orders of magnitude and obtain a training throughput speedup of up to 7.6x over highly optimized baselines with virtualized memory.
Pipe-SGD: A Decentralized Pipelined SGD Framework for Distributed Deep Net Training
Nov 08, 2018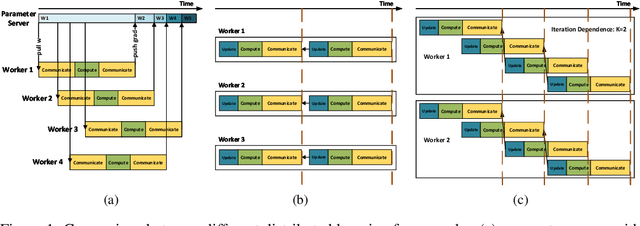
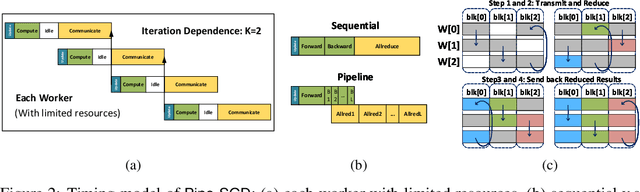
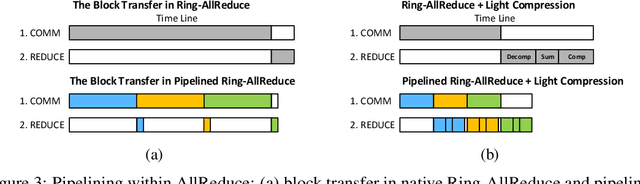
Distributed training of deep nets is an important technique to address some of the present day computing challenges like memory consumption and computational demands. Classical distributed approaches, synchronous or asynchronous, are based on the parameter server architecture, i.e., worker nodes compute gradients which are communicated to the parameter server while updated parameters are returned. Recently, distributed training with AllReduce operations gained popularity as well. While many of those operations seem appealing, little is reported about wall-clock training time improvements. In this paper, we carefully analyze the AllReduce based setup, propose timing models which include network latency, bandwidth, cluster size and compute time, and demonstrate that a pipelined training with a width of two combines the best of both synchronous and asynchronous training. Specifically, for a setup consisting of a four-node GPU cluster we show wall-clock time training improvements of up to 5.4x compared to conventional approaches.
GradiVeQ: Vector Quantization for Bandwidth-Efficient Gradient Aggregation in Distributed CNN Training
Nov 08, 2018

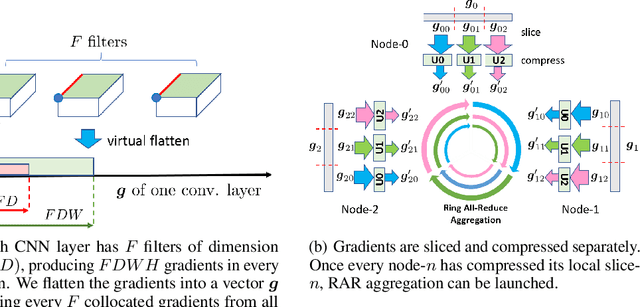
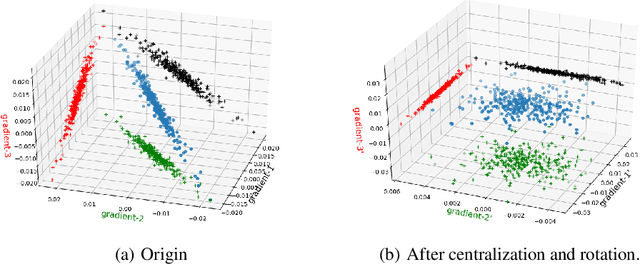
Data parallelism can boost the training speed of convolutional neural networks (CNN), but could suffer from significant communication costs caused by gradient aggregation. To alleviate this problem, several scalar quantization techniques have been developed to compress the gradients. But these techniques could perform poorly when used together with decentralized aggregation protocols like ring all-reduce (RAR), mainly due to their inability to directly aggregate compressed gradients. In this paper, we empirically demonstrate the strong linear correlations between CNN gradients, and propose a gradient vector quantization technique, named GradiVeQ, to exploit these correlations through principal component analysis (PCA) for substantial gradient dimension reduction. GradiVeQ enables direct aggregation of compressed gradients, hence allows us to build a distributed learning system that parallelizes GradiVeQ gradient compression and RAR communications. Extensive experiments on popular CNNs demonstrate that applying GradiVeQ slashes the wall-clock gradient aggregation time of the original RAR by more than 5X without noticeable accuracy loss, and reduces the end-to-end training time by almost 50%. The results also show that GradiVeQ is compatible with scalar quantization techniques such as QSGD (Quantized SGD), and achieves a much higher speed-up gain under the same compression ratio.