 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmony: Overcoming the hurdles of GPU memory capacity to train massive DNN models on commodity servers
Paper and Code
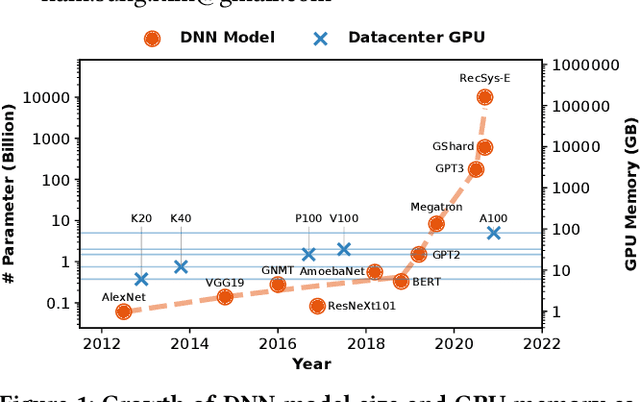
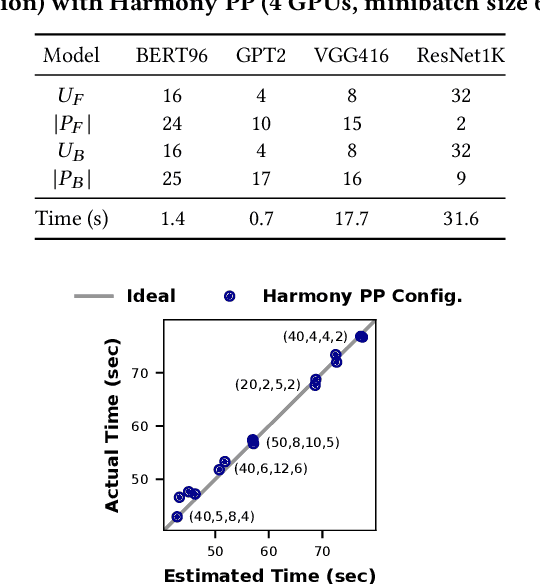
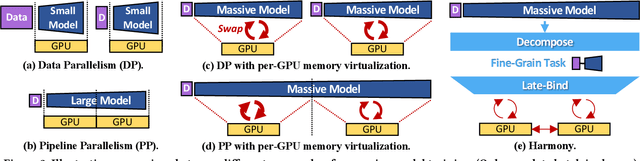
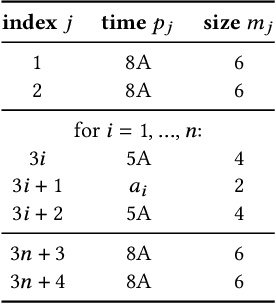
Deep neural networks (DNNs) have grown exponentially in complexity and size over the past decade, leaving only those who have access to massive datacenter-based resources with the ability to develop and train such models. One of the main challenges for the long tail of researchers who might have access to only limited resources (e.g., a single multi-GPU server) is limited GPU memory capacity compared to model size. The problem is so acute that the memory requirement of training large DNN models can often exceed the aggregate capacity of all available GPUs on commodity servers; this problem only gets worse with the trend of ever-growing model sizes. Current solutions that rely on virtualizing GPU memory (by swapping to/from CPU memory) incur excessive swapping overhead. In this paper, we present a new training framework, Harmony, and advocate rethinking how DNN frameworks schedule computation and move data to push the boundaries of training large models efficiently on modest multi-GPU deployments. Across many large DNN models, Harmony is able to reduce swap load by up to two orders of magnitude and obtain a training throughput speedup of up to 7.6x over highly optimized baselines with virtualized memory.