 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon Aware Transformers Through Joint Model-Hardware Optimization
May 02, 2025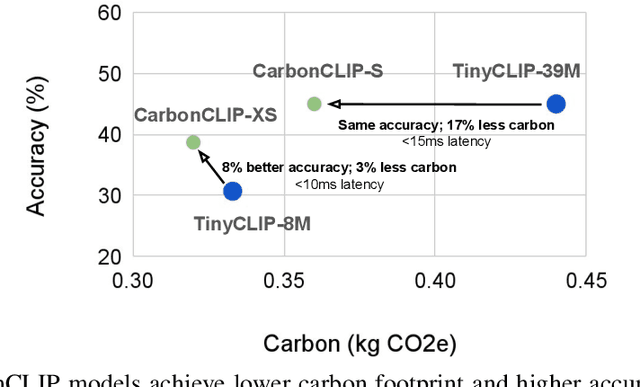
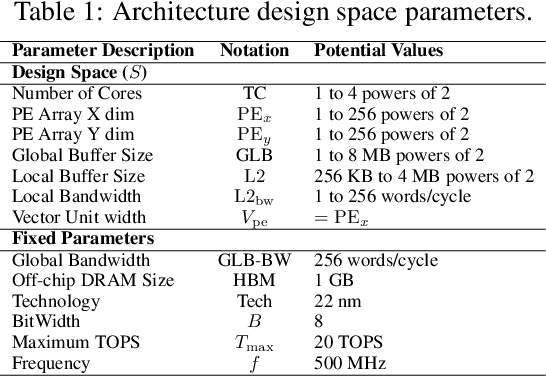
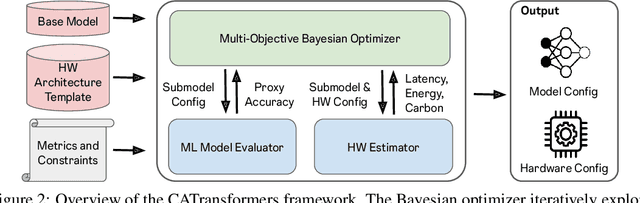
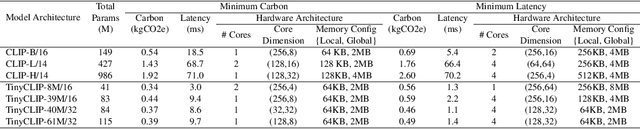
The rapid growth of machine learning (ML) systems necessitates a more comprehensive evaluation of their environmental impact, particularly their carbon footprint, which comprises operational carbon from training and inference execution and embodied carbon from hardware manufacturing and its entire life-cycle. Despite the increasing importance of embodied emissions, there is a lack of tools and frameworks to holistically quantify and optimize the total carbon footprint of ML systems. To address this, we propose CATransformers, a carbon-aware architecture search framework that enables sustainability-driven co-optimization of ML models and hardware architectures. By incorporating both operational and embodied carbon metrics into early design space exploration of domain-specific hardware accelerators, CATransformers demonstrates that optimizing for carbon yields design choices distinct from those optimized solely for latency or energy efficiency. We apply our framework to multi-modal CLIP-based models, producing CarbonCLIP, a family of CLIP models achieving up to 17% reduction in total carbon emissions while maintaining accuracy and latency compared to state-of-the-art edge small CLIP baselines. This work underscores the need for holistic optimization methods to design high-performance, environmentally sustainable AI systems.
Integrated Hardware Architecture and Device Placement Search
Jul 18, 2024



Distributed execution of deep learning training involves a dynamic interplay between hardware accelerator architecture and device placement strategy. This is the first work to explore the co-optimization of determining the optimal architecture and device placement strategy through novel algorithms, improving the balance of computational resources, memory usage, and data distribution. Our architecture search leverages tensor and vector units, determining their quantity and dimensionality, and on-chip and off-chip memory configurations. It also determines the microbatch size and decides whether to recompute or stash activations, balancing the memory footprint of training and storage size. For each explored architecture configuration, we use an Integer Linear Program (ILP) to find the optimal schedule for executing operators on the accelerator. The ILP results then integrate with a dynamic programming solution to identify the most effective device placement strategy, combining data, pipeline, and tensor model parallelism across multiple accelerators. Our approach achieves higher throughput on large language models compared to the state-of-the-art TPUv4 and the Spotlight accelerator search framework. The entire source code of PHAZE is available at https://github.com/msr-fiddle/phaze.
FLuID: Mitigating Stragglers in Federated Learning using Invariant Dropout
Jul 10, 2023Federated Learning (FL) allows machine learning models to train locally on individual mobile devices, synchronizing model updates via a shared server. This approach safeguards user privacy; however, it also generates a heterogeneous training environment due to the varying performance capabilities across devices. As a result, straggler devices with lower performance often dictate the overall training time in FL. In this work, we aim to alleviate this performance bottleneck due to stragglers by dynamically balancing the training load across the system. We introduce Invariant Dropout, a method that extracts a sub-model based on the weight update threshold, thereby minimizing potential impacts on accuracy. Building on this dropout technique, we develop an adaptive training framework, Federated Learning using Invariant Dropout (FLuID). FLuID offers a lightweight sub-model extraction to regulate computational intensity, thereby reducing the load on straggler devices without affecting model quality. Our method leverages neuron updates from non-straggler devices to construct a tailored sub-model for each straggler based on client performance profiling. Furthermore, FLuID can dynamically adapt to changes in stragglers as runtime conditions shift. We evaluate FLuID using five real-world mobile clients. The evaluations show that Invariant Dropout maintains baseline model efficiency while alleviating the performance bottleneck of stragglers through a dynamic, runtime approach.
Reducing Impacts of System Heterogeneity in Federated Learning using Weight Update Magnitudes
Aug 30, 2022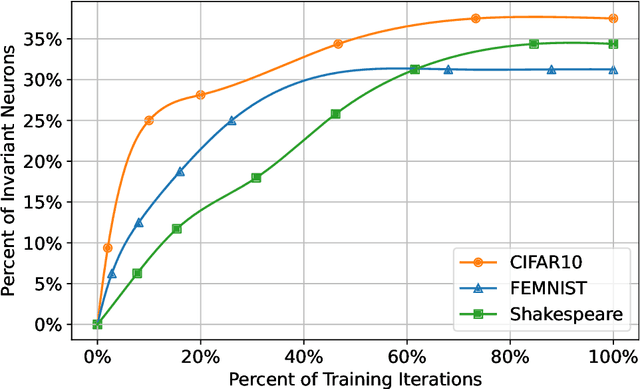
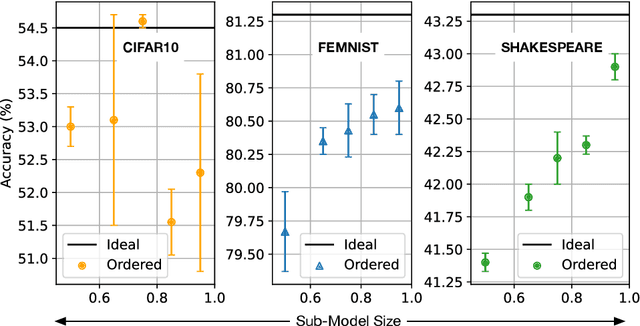
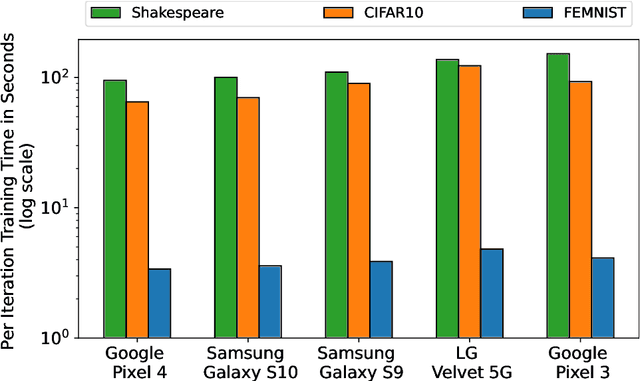
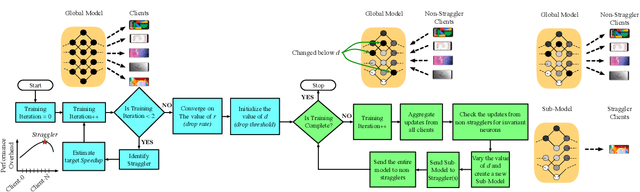
The widespread adoption of handheld devices have fueled rapid growth in new applications. Several of these new applications employ machine learning models to train on user data that is typically private and sensitive. Federated Learning enables machine learning models to train locally on each handheld device while only synchronizing their neuron updates with a server. While this enables user privacy, technology scaling and software advancements have resulted in handheld devices with varying performance capabilities. This results in the training time of federated learning tasks to be dictated by a few low-performance straggler devices, essentially becoming a bottleneck to the entire training process. In this work, we aim to mitigate the performance bottleneck of federated learning by dynamically forming sub-models for stragglers based on their performance and accuracy feedback. To this end, we offer the Invariant Dropout, a dynamic technique that forms a sub-model based on the neuron update threshold. Invariant Dropout uses neuron updates from the non-straggler clients to develop a tailored sub-models for each straggler during each training iteration. All corresponding weights which have a magnitude less than the threshold are dropped for the iteration. We evaluate Invariant Dropout using five real-world mobile clients. Our evaluations show that Invariant Dropout obtains a maximum accuracy gain of 1.4% points over state-of-the-art Ordered Dropout while mitigating performance bottlenecks of stragglers.