 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleAcross Explorer: Exploring Communication Optimization for Scale-Across AI Model Training
May 23, 2026The rapid scaling of large language model training requires distributing GPU resources across multiple data center buildings and regions. We refer to such paradigm as "scale-across" training. As infrastructure expands, the system design space becomes increasingly intricate, encompassing new model architectures, hardware heterogeneity, and evolving communication patterns. Drawing from Meta's production experience, we highlight the complexities of deploying training jobs across a few data centers housing hundreds of thousands of GPUs. To accelerate exploration of the large design space and to enable efficient training for frontier model development, we conduct in-depth characterization of three key design dimensions: parallelism placement, parallelism scheduling, and network layer technologies. We then propose ScaleAcross Explorer, an optimizer that considers the interplay of design dimensions and holistically optimizes scale-across training. Testbed experiments and simulations demonstrate up to 64.62% training speedups over production configuration and up to 37.59% training speedups over the state-of-the-art baseline across a wide range of design points.
KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
Dec 30, 2025Making deep learning recommendation model (DLRM) training and inference fast and efficient is important. However, this presents three key system challenges - model architecture diversity, kernel primitive diversity, and hardware generation and architecture heterogeneity. This paper presents KernelEvolve-an agentic kernel coding framework-to tackle heterogeneity at-scale for DLRM. KernelEvolve is designed to take kernel specifications as input and automate the process of kernel generation and optimization for recommendation model across heterogeneous hardware architectures. KernelEvolve does so by operating at multiple programming abstractions, from Triton and CuTe DSL to low-level hardware agnostic languages, spanning the full hardware-software optimization stack. The kernel optimization process is described as graph-based search with selection policy, universal operator, fitness function, and termination rule, dynamically adapts to runtime execution context through retrieval-augmented prompt synthesis. We designed, implemented, and deployed KernelEvolve to optimize a wide variety of production recommendation models across generations of NVIDIA and AMD GPUs, as well as Meta's AI accelerators. We validate KernelEvolve on the publicly-available KernelBench suite, achieving 100% pass rate on all 250 problems across three difficulty levels, and 160 PyTorch ATen operators across three heterogeneous hardware platforms, demonstrating 100% correctness. KernelEvolve reduces development time from weeks to hours and achieves substantial performance improvements over PyTorch baselines across diverse production use cases and for heterogeneous AI systems at-scale. Beyond performance efficiency improvements, KernelEvolve significantly mitigates the programmability barrier for new AI hardware by enabling automated kernel generation for in-house developed AI hardware.
Carbon Aware Transformers Through Joint Model-Hardware Optimization
May 02, 2025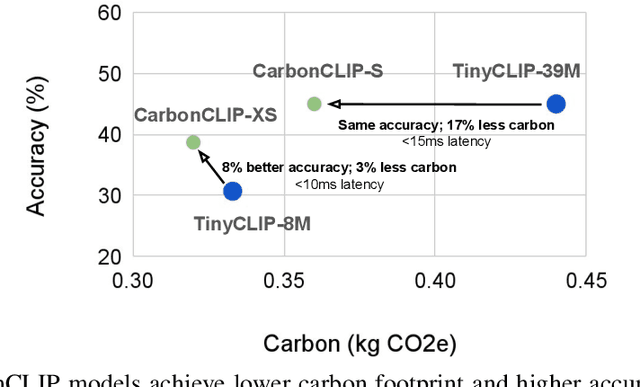
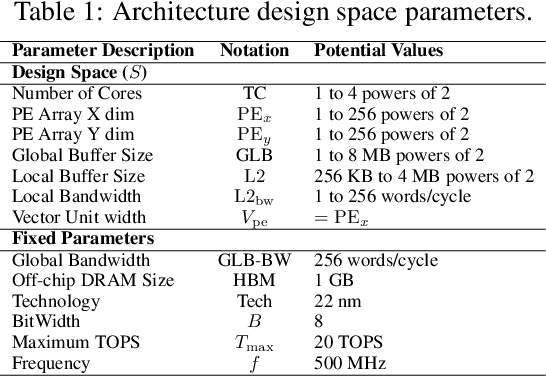
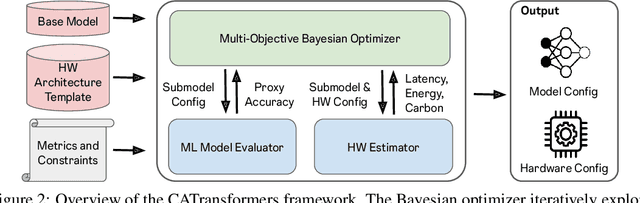
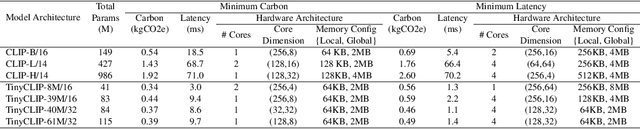
The rapid growth of machine learning (ML) systems necessitates a more comprehensive evaluation of their environmental impact, particularly their carbon footprint, which comprises operational carbon from training and inference execution and embodied carbon from hardware manufacturing and its entire life-cycle. Despite the increasing importance of embodied emissions, there is a lack of tools and frameworks to holistically quantify and optimize the total carbon footprint of ML systems. To address this, we propose CATransformers, a carbon-aware architecture search framework that enables sustainability-driven co-optimization of ML models and hardware architectures. By incorporating both operational and embodied carbon metrics into early design space exploration of domain-specific hardware accelerators, CATransformers demonstrates that optimizing for carbon yields design choices distinct from those optimized solely for latency or energy efficiency. We apply our framework to multi-modal CLIP-based models, producing CarbonCLIP, a family of CLIP models achieving up to 17% reduction in total carbon emissions while maintaining accuracy and latency compared to state-of-the-art edge small CLIP baselines. This work underscores the need for holistic optimization methods to design high-performance, environmentally sustainable AI systems.
Is Flash Attention Stable?
May 05, 2024



Training large-scale machine learning models poses distinct system challenges, given both the size and complexity of today's workloads. Recently, many organizations training state-of-the-art Generative AI models have reported cases of instability during training, often taking the form of loss spikes. Numeric deviation has emerged as a potential cause of this training instability, although quantifying this is especially challenging given the costly nature of training runs. In this work, we develop a principled approach to understanding the effects of numeric deviation, and construct proxies to put observations into context when downstream effects are difficult to quantify. As a case study, we apply this framework to analyze the widely-adopted Flash Attention optimization. We find that Flash Attention sees roughly an order of magnitude more numeric deviation as compared to Baseline Attention at BF16 when measured during an isolated forward pass. We then use a data-driven analysis based on the Wasserstein Distance to provide upper bounds on how this numeric deviation impacts model weights during training, finding that the numerical deviation present in Flash Attention is 2-5 times less significant than low-precision training.
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Dec 22, 2023



As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems
Oct 18, 2023Training and deploying large machine learning (ML) models is time-consuming and requires significant distributed computing infrastructures. Based on real-world large model training on datacenter-scale infrastructures, we show 14~32% of all GPU hours are spent on communication with no overlapping computation. To minimize the outstanding communication latency, in this work, we develop an agile performance modeling framework to guide parallelization and hardware-software co-design strategies. Using the suite of real-world large ML models on state-of-the-art GPU training hardware, we demonstrate 2.24x and 5.27x throughput improvement potential for pre-training and inference scenarios, respectively.
MP-Rec: Hardware-Software Co-Design to Enable Multi-Path Recommendation
Feb 21, 2023


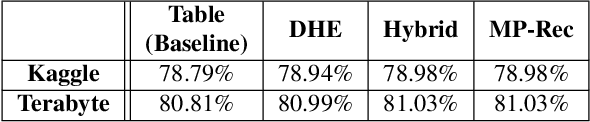
Deep learning recommendation systems serve personalized content under diverse tail-latency targets and input-query loads. In order to do so, state-of-the-art recommendation models rely on terabyte-scale embedding tables to learn user preferences over large bodies of contents. The reliance on a fixed embedding representation of embedding tables not only imposes significant memory capacity and bandwidth requirements but also limits the scope of compatible system solutions. This paper challenges the assumption of fixed embedding representations by showing how synergies between embedding representations and hardware platforms can lead to improvements in both algorithmic- and system performance. Based on our characterization of various embedding representations, we propose a hybrid embedding representation that achieves higher quality embeddings at the cost of increased memory and compute requirements. To address the system performance challenges of the hybrid representation, we propose MP-Rec -- a co-design technique that exploits heterogeneity and dynamic selection of embedding representations and underlying hardware platforms. On real system hardware, we demonstrate how matching custom accelerators, i.e., GPUs, TPUs, and IPUs, with compatible embedding representations can lead to 16.65x performance speedup. Additionally, in query-serving scenarios, MP-Rec achieves 2.49x and 3.76x higher correct prediction throughput and 0.19% and 0.22% better model quality on a CPU-GPU system for the Kaggle and Terabyte datasets, respectively.
RecPipe: Co-designing Models and Hardware to Jointly Optimize Recommendation Quality and Performance
May 22, 2021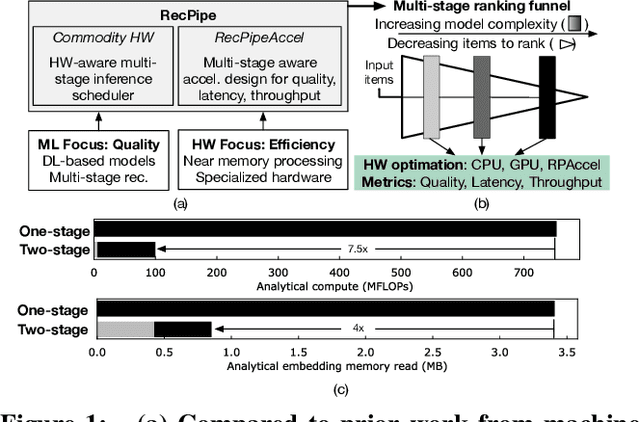

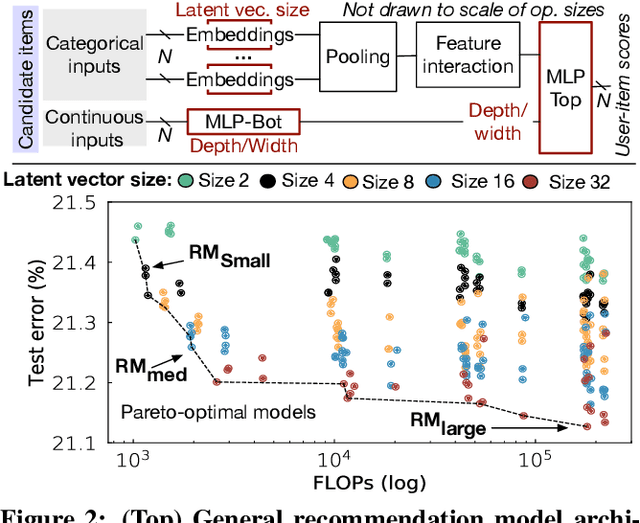
Deep learning recommendation systems must provide high quality, personalized content under strict tail-latency targets and high system loads. This paper presents RecPipe, a system to jointly optimize recommendation quality and inference performance. Central to RecPipe is decomposing recommendation models into multi-stage pipelines to maintain quality while reducing compute complexity and exposing distinct parallelism opportunities. RecPipe implements an inference scheduler to map multi-stage recommendation engines onto commodity, heterogeneous platforms (e.g., CPUs, GPUs).While the hardware-aware scheduling improves ranking efficiency, the commodity platforms suffer from many limitations requiring specialized hardware. Thus, we design RecPipeAccel (RPAccel), a custom accelerator that jointly optimizes quality, tail-latency, and system throughput. RPAc-cel is designed specifically to exploit the distinct design space opened via RecPipe. In particular, RPAccel processes queries in sub-batches to pipeline recommendation stages, implements dual static and dynamic embedding caches, a set of top-k filtering units, and a reconfigurable systolic array. Com-pared to prior-art and at iso-quality, we demonstrate that RPAccel improves latency and throughput by 3x and 6x.
RecSSD: Near Data Processing for Solid State Drive Based Recommendation Inference
Jan 29, 2021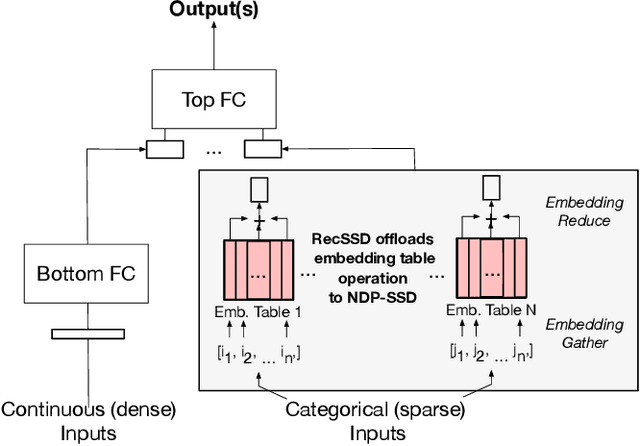
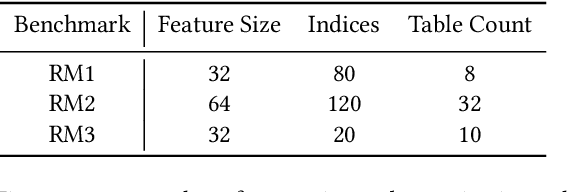
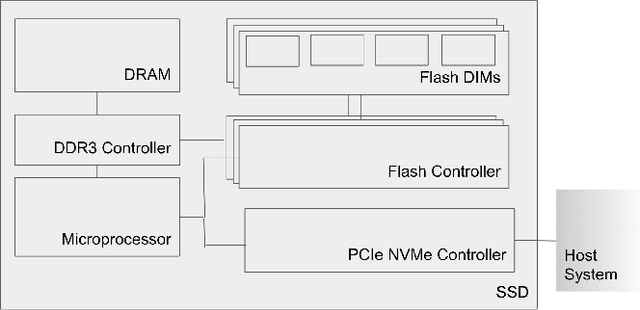
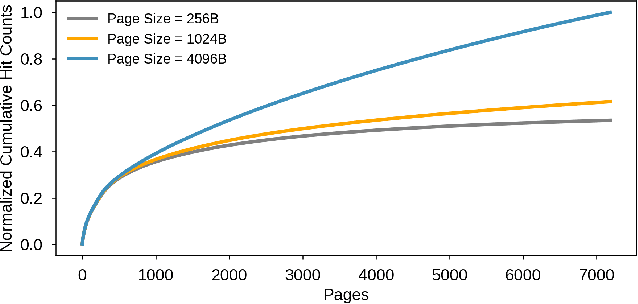
Neural personalized recommendation models are used across a wide variety of datacenter applications including search, social media, and entertainment. State-of-the-art models comprise large embedding tables that have billions of parameters requiring large memory capacities. Unfortunately, large and fast DRAM-based memories levy high infrastructure costs. Conventional SSD-based storage solutions offer an order of magnitude larger capacity, but have worse read latency and bandwidth, degrading inference performance. RecSSD is a near data processing based SSD memory system customized for neural recommendation inference that reduces end-to-end model inference latency by 2X compared to using COTS SSDs across eight industry-representative models.