 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMP-Rec: Hardware-Software Co-Design to Enable Multi-Path Recommendation
Paper and Code



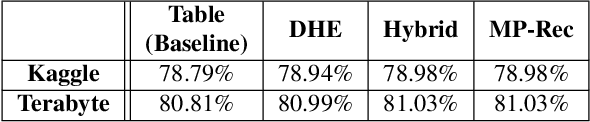
Deep learning recommendation systems serve personalized content under diverse tail-latency targets and input-query loads. In order to do so, state-of-the-art recommendation models rely on terabyte-scale embedding tables to learn user preferences over large bodies of contents. The reliance on a fixed embedding representation of embedding tables not only imposes significant memory capacity and bandwidth requirements but also limits the scope of compatible system solutions. This paper challenges the assumption of fixed embedding representations by showing how synergies between embedding representations and hardware platforms can lead to improvements in both algorithmic- and system performance. Based on our characterization of various embedding representations, we propose a hybrid embedding representation that achieves higher quality embeddings at the cost of increased memory and compute requirements. To address the system performance challenges of the hybrid representation, we propose MP-Rec -- a co-design technique that exploits heterogeneity and dynamic selection of embedding representations and underlying hardware platforms. On real system hardware, we demonstrate how matching custom accelerators, i.e., GPUs, TPUs, and IPUs, with compatible embedding representations can lead to 16.65x performance speedup. Additionally, in query-serving scenarios, MP-Rec achieves 2.49x and 3.76x higher correct prediction throughput and 0.19% and 0.22% better model quality on a CPU-GPU system for the Kaggle and Terabyte datasets, respectively.