 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMP-Rec: Hardware-Software Co-Design to Enable Multi-Path Recommendation
Feb 21, 2023


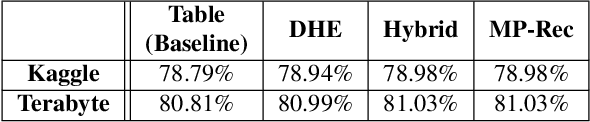
Deep learning recommendation systems serve personalized content under diverse tail-latency targets and input-query loads. In order to do so, state-of-the-art recommendation models rely on terabyte-scale embedding tables to learn user preferences over large bodies of contents. The reliance on a fixed embedding representation of embedding tables not only imposes significant memory capacity and bandwidth requirements but also limits the scope of compatible system solutions. This paper challenges the assumption of fixed embedding representations by showing how synergies between embedding representations and hardware platforms can lead to improvements in both algorithmic- and system performance. Based on our characterization of various embedding representations, we propose a hybrid embedding representation that achieves higher quality embeddings at the cost of increased memory and compute requirements. To address the system performance challenges of the hybrid representation, we propose MP-Rec -- a co-design technique that exploits heterogeneity and dynamic selection of embedding representations and underlying hardware platforms. On real system hardware, we demonstrate how matching custom accelerators, i.e., GPUs, TPUs, and IPUs, with compatible embedding representations can lead to 16.65x performance speedup. Additionally, in query-serving scenarios, MP-Rec achieves 2.49x and 3.76x higher correct prediction throughput and 0.19% and 0.22% better model quality on a CPU-GPU system for the Kaggle and Terabyte datasets, respectively.
PINE: Universal Deep Embedding for Graph Nodes via Partial Permutation Invariant Set Functions
Sep 25, 2019
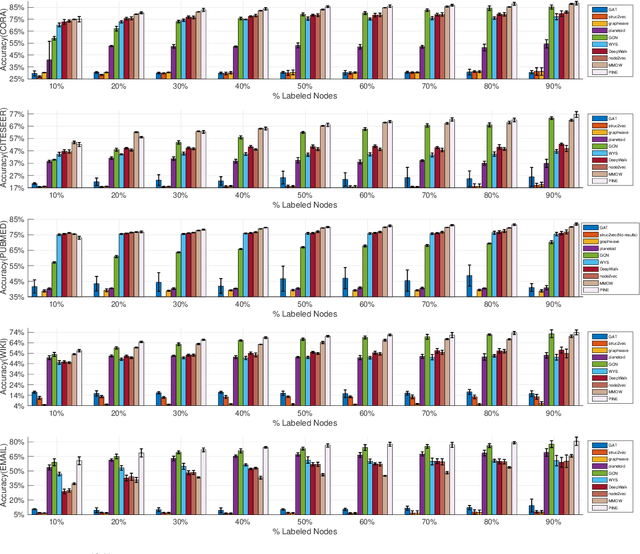
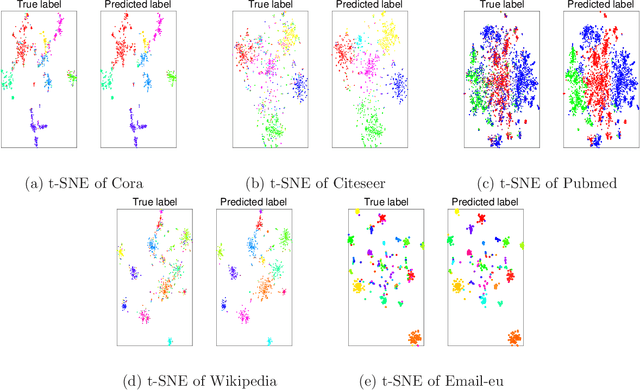

Graph node embedding aims at learning a vector representation for all nodes given a graph. It is a central problem in many machine learning tasks (e.g., node classification, recommendation, community detection). The key problem in graph node embedding lies in how to define the dependence to neighbors. Existing approaches specify (either explicitly or implicitly) certain dependencies on neighbors, which may lead to loss of subtle but important structural information within the graph and other dependencies among neighbors. This intrigues us to ask the question: can we design a model to give the maximal flexibility of dependencies to each node's neighborhood. In this paper, we propose a novel graph node embedding (named PINE) via a novel notion of partial permutation invariant set function, to capture any possible dependence. Our method 1) can learn an arbitrary form of the representation function from the neighborhood, withour losing any potential dependence structures, and 2) is applicable to both homogeneous and heterogeneous graph embedding, the latter of which is challenged by the diversity of node types. Furthermore, we provide theoretical guarantee for the representation capability of our method for general homogeneous and heterogeneous graphs. Empirical evaluation results on benchmark data sets show that our proposed PINE method outperforms the state-of-the-art approaches on producing node vectors for various learning tasks of both homogeneous and heterogeneous graphs.