 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Mitigating Data Stalls in DNN Training
Jul 14, 2020
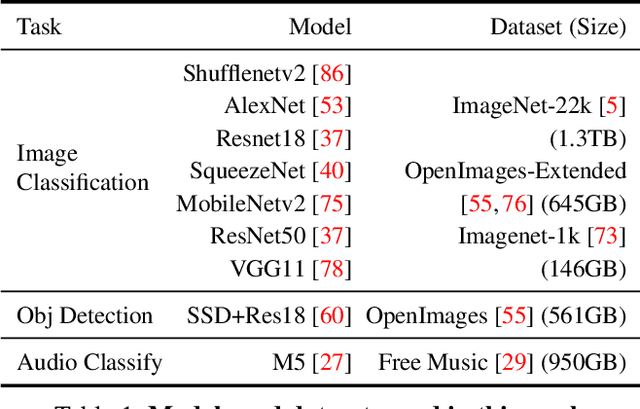
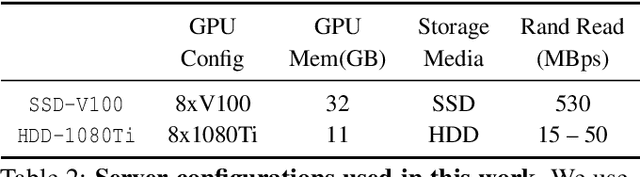
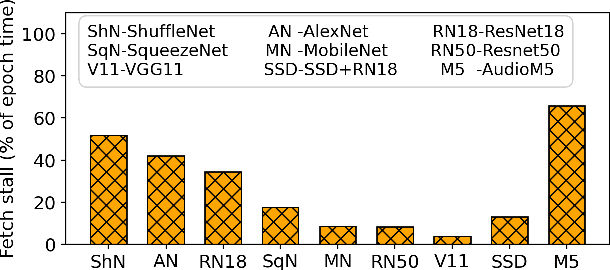
We present the first comprehensive analysis of how the data pipeline affects the training of the widely used Deep Neural Networks (DNNs). We analyze nine models and four datasets while varying factors such as the amount of memory, number of CPU threads, etc. We find that in many cases, DNN training time is dominated by data stall time: time spent waiting for data to be fetched from storage and pre-processed. Based on our insights, we build CoorDL, a novel data-loading library that accelerates DNN training by minimizing data stalls. CoorDL introduces three core techniques: coordinated pre-processing, partitioned caching, and DNN-aware software caching policy (MinIO). CoorDL does not affect training accuracy, and does not require special hardware support. CoorDL accelerates multiple aspects of DNN training: hyperparameter search, single-server training, and multi-server training. Our experiments on a range of DNN tasks, models, datasets, and hardware configurations show that CoorDL accelerates hyperparameter search by upto 5.7x, single-server training by upto 2x, and multi-server training by upto 15x compared to the state-of-the-art data loading library DALI on PyTorch.