 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD-DPE: Dual-Prompt Expert Network based on Convolutional Dictionary Feature Decoupling for Multi-Contrast MRI Super-Resolution
Nov 18, 2025Multi-contrast magnetic resonance imaging (MRI) super-resolution intends to reconstruct high-resolution (HR) images from low-resolution (LR) scans by leveraging structural information present in HR reference images acquired with different contrasts. This technique enhances anatomical detail and soft tissue differentiation, which is vital for early diagnosis and clinical decision-making. However, inherent contrasts disparities between modalities pose fundamental challenges in effectively utilizing reference image textures to guide target image reconstruction, often resulting in suboptimal feature integration. To address this issue, we propose a dual-prompt expert network based on a convolutional dictionary feature decoupling (CD-DPE) strategy for multi-contrast MRI super-resolution. Specifically, we introduce an iterative convolutional dictionary feature decoupling module (CD-FDM) to separate features into cross-contrast and intra-contrast components, thereby reducing redundancy and interference. To fully integrate these features, a novel dual-prompt feature fusion expert module (DP-FFEM) is proposed. This module uses a frequency prompt to guide the selection of relevant reference features for incorporation into the target image, while an adaptive routing prompt determines the optimal method for fusing reference and target features to enhance reconstruction quality. Extensive experiments on public multi-contrast MRI datasets demonstrate that CD-DPE outperforms state-of-the-art methods in reconstructing fine details. Additionally, experiments on unseen datasets demonstrated that CD-DPE exhibits strong generalization capabilities.
VISTAR:A User-Centric and Role-Driven Benchmark for Text-to-Image Evaluation
Aug 08, 2025We present VISTAR, a user-centric, multi-dimensional benchmark for text-to-image (T2I) evaluation that addresses the limitations of existing metrics. VISTAR introduces a two-tier hybrid paradigm: it employs deterministic, scriptable metrics for physically quantifiable attributes (e.g., text rendering, lighting) and a novel Hierarchical Weighted P/N Questioning (HWPQ) scheme that uses constrained vision-language models to assess abstract semantics (e.g., style fusion, cultural fidelity). Grounded in a Delphi study with 120 experts, we defined seven user roles and nine evaluation angles to construct the benchmark, which comprises 2,845 prompts validated by over 15,000 human pairwise comparisons. Our metrics achieve high human alignment (>75%), with the HWPQ scheme reaching 85.9% accuracy on abstract semantics, significantly outperforming VQA baselines. Comprehensive evaluation of state-of-the-art models reveals no universal champion, as role-weighted scores reorder rankings and provide actionable guidance for domain-specific deployment. All resources are publicly released to foster reproducible T2I assessment.
A No-Reference Medical Image Quality Assessment Method Based on Automated Distortion Recognition Technology: Application to Preprocessing in MRI-guided Radiotherapy
Dec 10, 2024



Objective:To develop a no-reference image quality assessment method using automated distortion recognition to boost MRI-guided radiotherapy precision.Methods:We analyzed 106,000 MR images from 10 patients with liver metastasis,captured with the Elekta Unity MR-LINAC.Our No-Reference Quality Assessment Model includes:1)image preprocessing to enhance visibility of key diagnostic features;2)feature extraction and directional analysis using MSCN coefficients across four directions to capture textural attributes and gradients,vital for identifying image features and potential distortions;3)integrative Quality Index(QI)calculation,which integrates features via AGGD parameter estimation and K-means clustering.The QI,based on a weighted MAD computation of directional scores,provides a comprehensive image quality measure,robust against outliers.LOO-CV assessed model generalizability and performance.Tumor tracking algorithm performance was compared with and without preprocessing to verify tracking accuracy enhancements.Results:Preprocessing significantly improved image quality,with the QI showing substantial positive changes and surpassing other metrics.After normalization,the QI's average value was 79.6 times higher than CNR,indicating improved image definition and contrast.It also showed higher sensitivity in detail recognition with average values 6.5 times and 1.7 times higher than Tenengrad gradient and entropy.The tumor tracking algorithm confirmed significant tracking accuracy improvements with preprocessed images,validating preprocessing effectiveness.Conclusions:This study introduces a novel no-reference image quality evaluation method based on automated distortion recognition,offering a new quality control tool for MRIgRT tumor tracking.It enhances clinical application accuracy and facilitates medical image quality assessment standardization, with significant clinical and research value.
A Novel Automatic Real-time Motion Tracking Method for Magnetic Resonance Imaging-guided Radiotherapy: Leveraging the Enhanced Tracking-Learning-Detection Framework with Automatic Segmentation
Nov 12, 2024



Objective: Ensuring the precision in motion tracking for MRI-guided Radiotherapy (MRIgRT) is crucial for the delivery of effective treatments. This study refined the motion tracking accuracy in MRIgRT through the innovation of an automatic real-time tracking method, leveraging an enhanced Tracking-Learning-Detection (ETLD) framework coupled with automatic segmentation. Methods: We developed a novel MRIgRT motion tracking method by integrating two primary methods: the ETLD framework and an improved Chan-Vese model (ICV), named ETLD+ICV. The TLD framework was upgraded to suit real-time cine MRI, including advanced image preprocessing, no-reference image quality assessment, an enhanced median-flow tracker, and a refined detector with dynamic search region adjustments. Additionally, ICV was combined for precise coverage of the target volume, which refined the segmented region frame by frame using tracking results, with key parameters optimized. Tested on 3.5D MRI scans from 10 patients with liver metastases, our method ensures precise tracking and accurate segmentation vital for MRIgRT. Results: An evaluation of 106,000 frames across 77 treatment fractions revealed sub-millimeter tracking errors of less than 0.8mm, with over 99% precision and 98% recall for all subjects, underscoring the robustness and efficacy of the ETLD. Moreover, the ETLD+ICV yielded a dice global score of more than 82% for all subjects, demonstrating the proposed method's extensibility and precise target volume coverage. Conclusions: This study successfully developed an automatic real-time motion tracking method for MRIgRT that markedly surpasses current methods. The novel method not only delivers exceptional precision in tracking and segmentation but also demonstrates enhanced adaptability to clinical demands, positioning it as an indispensable asset in the quest to augment the efficacy of radiotherapy treatments.
On the Trade-off between Flatness and Optimization in Distributed Learning
Jun 28, 2024



This paper proposes a theoretical framework to evaluate and compare the performance of gradient-descent algorithms for distributed learning in relation to their behavior around local minima in nonconvex environments. Previous works have noticed that convergence toward flat local minima tend to enhance the generalization ability of learning algorithms. This work discovers two interesting results. First, it shows that decentralized learning strategies are able to escape faster away from local minimizers and favor convergence toward flatter minima relative to the centralized solution in the large-batch training regime. Second, and importantly, the ultimate classification accuracy is not solely dependent on the flatness of the local minimizer but also on how well a learning algorithm can approach that minimum. In other words, the classification accuracy is a function of both flatness and optimization performance. The paper examines the interplay between the two measures of flatness and optimization error closely. One important conclusion is that decentralized strategies of the diffusion type deliver enhanced classification accuracy because it strikes a more favorable balance between flatness and optimization performance.
Hierarchical Fashion Design with Multi-stage Diffusion Models
Jan 20, 2024

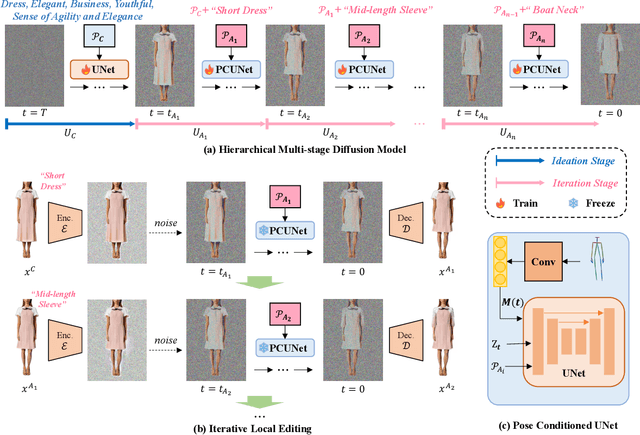

Cross-modal fashion synthesis and editing offer intelligent support to fashion designers by enabling the automatic generation and local modification of design drafts.While current diffusion models demonstrate commendable stability and controllability in image synthesis,they still face significant challenges in generating fashion design from abstract design elements and fine-grained editing.Abstract sensory expressions, \eg office, business, and party, form the high-level design concepts, while measurable aspects like sleeve length, collar type, and pant length are considered the low-level attributes of clothing.Controlling and editing fashion images using lengthy text descriptions poses a difficulty.In this paper, we propose HieraFashDiff,a novel fashion design method using the shared multi-stage diffusion model encompassing high-level design concepts and low-level clothing attributes in a hierarchical structure.Specifically, we categorized the input text into different levels and fed them in different time step to the diffusion model according to the criteria of professional clothing designers.HieraFashDiff allows designers to add low-level attributes after high-level prompts for interactive editing incrementally.In addition, we design a differentiable loss function in the sampling process with a mask to keep non-edit areas.Comprehensive experiments performed on our newly conducted Hierarchical fashion dataset,demonstrate that our proposed method outperforms other state-of-the-art competitors.
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 24, 2023



Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy.
Decentralized Adversarial Training over Graphs
Mar 23, 2023



The vulnerability of machine learning models to adversarial attacks has been attracting considerable attention in recent years. Most existing studies focus on the behavior of stand-alone single-agent learners. In comparison, this work studies adversarial training over graphs, where individual agents are subjected to perturbations of varied strength levels across space. It is expected that interactions by linked agents, and the heterogeneity of the attack models that are possible over the graph, can help enhance robustness in view of the coordination power of the group. Using a min-max formulation of diffusion learning, we develop a decentralized adversarial training framework for multi-agent systems. We analyze the convergence properties of the proposed scheme for both convex and non-convex environments, and illustrate the enhanced robustness to adversarial attacks.
Multi-Agent Adversarial Training Using Diffusion Learning
Mar 03, 2023



This work focuses on adversarial learning over graphs. We propose a general adversarial training framework for multi-agent systems using diffusion learning. We analyze the convergence properties of the proposed scheme for convex optimization problems, and illustrate its enhanced robustness to adversarial attacks.
Boosting Neural Networks to Decompile Optimized Binaries
Jan 03, 2023
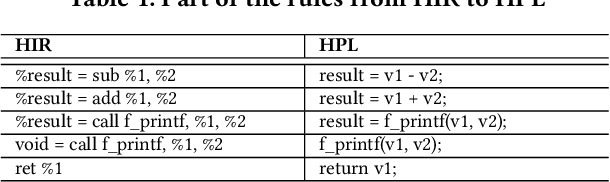
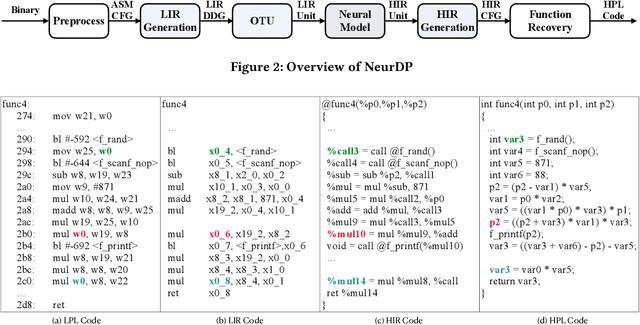
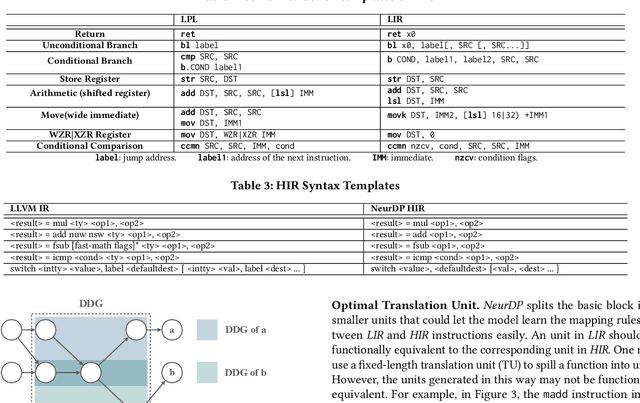
Decompilation aims to transform a low-level program language (LPL) (eg., binary file) into its functionally-equivalent high-level program language (HPL) (e.g., C/C++). It is a core technology in software security, especially in vulnerability discovery and malware analysis. In recent years, with the successful application of neural machine translation (NMT) models in natural language processing (NLP), researchers have tried to build neural decompilers by borrowing the idea of NMT. They formulate the decompilation process as a translation problem between LPL and HPL, aiming to reduce the human cost required to develop decompilation tools and improve their generalizability. However, state-of-the-art learning-based decompilers do not cope well with compiler-optimized binaries. Since real-world binaries are mostly compiler-optimized, decompilers that do not consider optimized binaries have limited practical significance. In this paper, we propose a novel learning-based approach named NeurDP, that targets compiler-optimized binaries. NeurDP uses a graph neural network (GNN) model to convert LPL to an intermediate representation (IR), which bridges the gap between source code and optimized binary. We also design an Optimized Translation Unit (OTU) to split functions into smaller code fragments for better translation performance. Evaluation results on datasets containing various types of statements show that NeurDP can decompile optimized binaries with 45.21% higher accuracy than state-of-the-art neural decompilation frameworks.