 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCMind-2.1-Kaiyuan-2B Technical Report
Dec 08, 2025The rapid advancement of Large Language Models (LLMs) has resulted in a significant knowledge gap between the open-source community and industry, primarily because the latter relies on closed-source, high-quality data and training recipes. To address this, we introduce PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter model focused on improving training efficiency and effectiveness under resource constraints. Our methodology includes three key innovations: a Quantile Data Benchmarking method for systematically comparing heterogeneous open-source datasets and providing insights on data mixing strategies; a Strategic Selective Repetition scheme within a multi-phase paradigm to effectively leverage sparse, high-quality data; and a Multi-Domain Curriculum Training policy that orders samples by quality. Supported by a highly optimized data preprocessing pipeline and architectural modifications for FP16 stability, Kaiyuan-2B achieves performance competitive with state-of-the-art fully open-source models, demonstrating practical and scalable solutions for resource-limited pretraining. We release all assets (including model weights, data, and code) under Apache 2.0 license at https://huggingface.co/thu-pacman/PCMind-2.1-Kaiyuan-2B.
MS-YOLO: A Multi-Scale Model for Accurate and Efficient Blood Cell Detection
Jun 04, 2025Complete blood cell detection holds significant value in clinical diagnostics. Conventional manual microscopy methods suffer from time inefficiency and diagnostic inaccuracies. Existing automated detection approaches remain constrained by high deployment costs and suboptimal accuracy. While deep learning has introduced powerful paradigms to this field, persistent challenges in detecting overlapping cells and multi-scale objects hinder practical deployment. This study proposes the multi-scale YOLO (MS-YOLO), a blood cell detection model based on the YOLOv11 framework, incorporating three key architectural innovations to enhance detection performance. Specifically, the multi-scale dilated residual module (MS-DRM) replaces the original C3K2 modules to improve multi-scale discriminability; the dynamic cross-path feature enhancement module (DCFEM) enables the fusion of hierarchical features from the backbone with aggregated features from the neck to enhance feature representations; and the light adaptive-weight downsampling module (LADS) improves feature downsampling through adaptive spatial weighting while reducing computational complexity. Experimental results on the CBC benchmark demonstrate that MS-YOLO achieves precise detection of overlapping cells and multi-scale objects, particularly small targets such as platelets, achieving an mAP@50 of 97.4% that outperforms existing models. Further validation on the supplementary WBCDD dataset confirms its robust generalization capability. Additionally, with a lightweight architecture and real-time inference efficiency, MS-YOLO meets clinical deployment requirements, providing reliable technical support for standardized blood pathology assessment.
A No-Reference Medical Image Quality Assessment Method Based on Automated Distortion Recognition Technology: Application to Preprocessing in MRI-guided Radiotherapy
Dec 10, 2024



Objective:To develop a no-reference image quality assessment method using automated distortion recognition to boost MRI-guided radiotherapy precision.Methods:We analyzed 106,000 MR images from 10 patients with liver metastasis,captured with the Elekta Unity MR-LINAC.Our No-Reference Quality Assessment Model includes:1)image preprocessing to enhance visibility of key diagnostic features;2)feature extraction and directional analysis using MSCN coefficients across four directions to capture textural attributes and gradients,vital for identifying image features and potential distortions;3)integrative Quality Index(QI)calculation,which integrates features via AGGD parameter estimation and K-means clustering.The QI,based on a weighted MAD computation of directional scores,provides a comprehensive image quality measure,robust against outliers.LOO-CV assessed model generalizability and performance.Tumor tracking algorithm performance was compared with and without preprocessing to verify tracking accuracy enhancements.Results:Preprocessing significantly improved image quality,with the QI showing substantial positive changes and surpassing other metrics.After normalization,the QI's average value was 79.6 times higher than CNR,indicating improved image definition and contrast.It also showed higher sensitivity in detail recognition with average values 6.5 times and 1.7 times higher than Tenengrad gradient and entropy.The tumor tracking algorithm confirmed significant tracking accuracy improvements with preprocessed images,validating preprocessing effectiveness.Conclusions:This study introduces a novel no-reference image quality evaluation method based on automated distortion recognition,offering a new quality control tool for MRIgRT tumor tracking.It enhances clinical application accuracy and facilitates medical image quality assessment standardization, with significant clinical and research value.
A Novel Automatic Real-time Motion Tracking Method for Magnetic Resonance Imaging-guided Radiotherapy: Leveraging the Enhanced Tracking-Learning-Detection Framework with Automatic Segmentation
Nov 12, 2024



Objective: Ensuring the precision in motion tracking for MRI-guided Radiotherapy (MRIgRT) is crucial for the delivery of effective treatments. This study refined the motion tracking accuracy in MRIgRT through the innovation of an automatic real-time tracking method, leveraging an enhanced Tracking-Learning-Detection (ETLD) framework coupled with automatic segmentation. Methods: We developed a novel MRIgRT motion tracking method by integrating two primary methods: the ETLD framework and an improved Chan-Vese model (ICV), named ETLD+ICV. The TLD framework was upgraded to suit real-time cine MRI, including advanced image preprocessing, no-reference image quality assessment, an enhanced median-flow tracker, and a refined detector with dynamic search region adjustments. Additionally, ICV was combined for precise coverage of the target volume, which refined the segmented region frame by frame using tracking results, with key parameters optimized. Tested on 3.5D MRI scans from 10 patients with liver metastases, our method ensures precise tracking and accurate segmentation vital for MRIgRT. Results: An evaluation of 106,000 frames across 77 treatment fractions revealed sub-millimeter tracking errors of less than 0.8mm, with over 99% precision and 98% recall for all subjects, underscoring the robustness and efficacy of the ETLD. Moreover, the ETLD+ICV yielded a dice global score of more than 82% for all subjects, demonstrating the proposed method's extensibility and precise target volume coverage. Conclusions: This study successfully developed an automatic real-time motion tracking method for MRIgRT that markedly surpasses current methods. The novel method not only delivers exceptional precision in tracking and segmentation but also demonstrates enhanced adaptability to clinical demands, positioning it as an indispensable asset in the quest to augment the efficacy of radiotherapy treatments.
CPM-2: Large-scale Cost-effective Pre-trained Language Models
Jun 24, 2021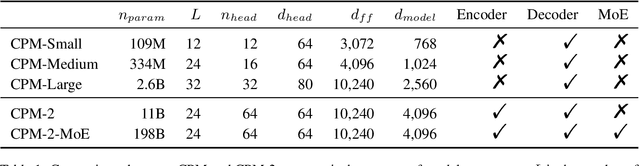

In recent years, the size of pre-trained language models (PLMs) has grown by leaps and bounds. However, efficiency issues of these large-scale PLMs limit their utilization in real-world scenarios. We present a suite of cost-effective techniques for the use of PLMs to deal with the efficiency issues of pre-training, fine-tuning, and inference. (1) We introduce knowledge inheritance to accelerate the pre-training process by exploiting existing PLMs instead of training models from scratch. (2) We explore the best practice of prompt tuning with large-scale PLMs. Compared with conventional fine-tuning, prompt tuning significantly reduces the number of task-specific parameters. (3) We implement a new inference toolkit, namely InfMoE, for using large-scale PLMs with limited computational resources. Based on our cost-effective pipeline, we pre-train two models: an encoder-decoder bilingual model with 11 billion parameters (CPM-2) and its corresponding MoE version with 198 billion parameters. In our experiments, we compare CPM-2 with mT5 on downstream tasks. Experimental results show that CPM-2 has excellent general language intelligence. Moreover, we validate the efficiency of InfMoE when conducting inference of large-scale models having tens of billions of parameters on a single GPU. All source code and model parameters are available at https://github.com/TsinghuaAI/CPM.
CPM: A Large-scale Generative Chinese Pre-trained Language Model
Dec 01, 2020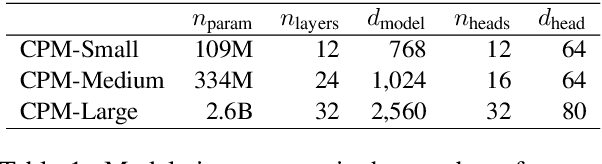

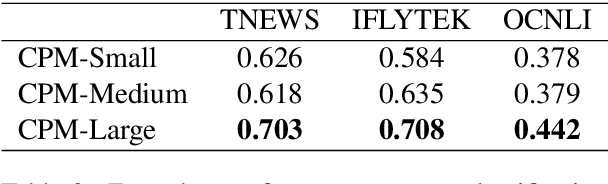
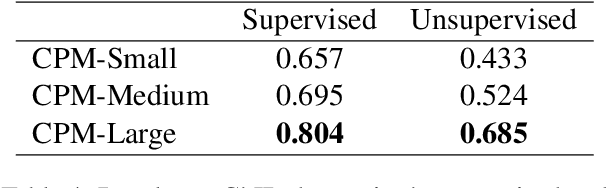
Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3, with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation, cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many NLP tasks in the settings of few-shot (even zero-shot) learning. The code and parameters are available at https://github.com/TsinghuaAI/CPM-Generate.
Corrective feedback, emphatic speech synthesis, visual-speech exaggeration, pronunciation learning
Sep 12, 2020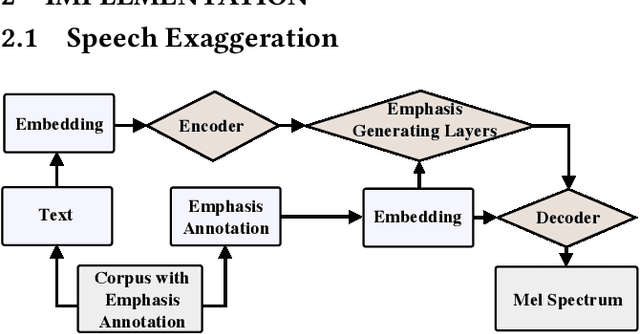
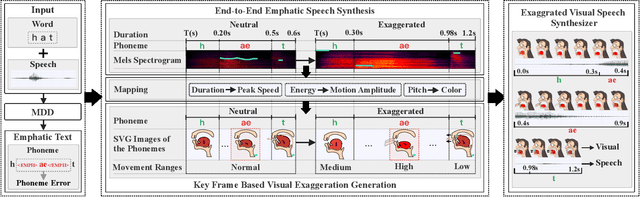
To provide more discriminative feedback for the second language (L2) learners to better identify their mispronunciation, we propose a method for exaggerated visual-speech feedback in computer-assisted pronunciation training (CAPT). The speech exaggeration is realized by an emphatic speech generation neural network based on Tacotron, while the visual exaggeration is accomplished by ADC Viseme Blending, namely increasing Amplitude of movement, extending the phone's Duration and enhancing the color Contrast. User studies show that exaggerated feedback outperforms non-exaggerated version on helping learners with pronunciation identification and pronunciation improvement.