 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient and Exact Optimization of Language Model Alignment
Feb 02, 2024



The alignment of language models with human preferences is vital for their application in real-world tasks. The problem is formulated as optimizing the model's policy to maximize the expected reward that reflects human preferences with minimal deviation from the initial policy. While considered as a straightforward solution, reinforcement learning (RL) suffers from high variance in policy updates, which impedes efficient policy improvement. Recently, direct preference optimization (DPO) was proposed to directly optimize the policy from preference data. Though simple to implement, DPO is derived based on the optimal policy that is not assured to be achieved in practice, which undermines its convergence to the intended solution. In this paper, we propose efficient exact optimization (EXO) of the alignment objective. We prove that EXO is guaranteed to optimize in the same direction as the RL algorithms asymptotically for arbitary parametrization of the policy, while enables efficient optimization by circumventing the complexities associated with RL algorithms. We compare our method to DPO with both theoretical and empirical analyses, and further demonstrate the advantages of our method over existing approaches on realistic human preference data.
Language Model Decoding as Direct Metrics Optimization
Oct 02, 2023



Despite the remarkable advances in language modeling, current mainstream decoding methods still struggle to generate texts that align with human texts across different aspects. In particular, sampling-based methods produce less-repetitive texts which are often disjunctive in discourse, while search-based methods maintain topic coherence at the cost of increased repetition. Overall, these methods fall short in achieving holistic alignment across a broad range of aspects. In this work, we frame decoding from a language model as an optimization problem with the goal of strictly matching the expected performance with human texts measured by multiple metrics of desired aspects simultaneously. The resulting decoding distribution enjoys an analytical solution that scales the input language model distribution via a sequence-level energy function defined by these metrics. And most importantly, we prove that this induced distribution is guaranteed to improve the perplexity on human texts, which suggests a better approximation to the underlying distribution of human texts. To facilitate tractable sampling from this globally normalized distribution, we adopt the Sampling-Importance-Resampling technique. Experiments on various domains and model scales demonstrate the superiority of our method in metrics alignment with human texts and human evaluation over strong baselines.
Tailoring Language Generation Models under Total Variation Distance
Feb 26, 2023



The standard paradigm of neural language generation adopts maximum likelihood estimation (MLE) as the optimizing method. From a distributional view, MLE in fact minimizes the Kullback-Leibler divergence (KLD) between the distribution of the real data and that of the model. However, this approach forces the model to distribute non-zero (sometimes large) probability mass to all training samples regardless of their quality. Moreover, in the attempt to cover the low-probability regions in the data distribution, the model systematically overestimates the probability of corrupted text sequences, which we conjecture is one of the main reasons for text degeneration during autoregressive decoding. To remedy this problem, we leverage the total variation distance (TVD) with its robustness to outliers, and develop practical bounds to apply it to language generation. Then, we introduce the TaiLr objective that balances the tradeoff of estimating TVD. Intuitively, TaiLr downweights real data samples that have low model probabilities with tunable penalization intensity. Experimental results show that our method alleviates the overestimation of degenerated sequences without sacrificing diversity and improves generation quality on a wide range of text generation tasks.
* Published in ICLR 2023 (notable-top-5%)
Curriculum-Based Self-Training Makes Better Few-Shot Learners for Data-to-Text Generation
Jun 06, 2022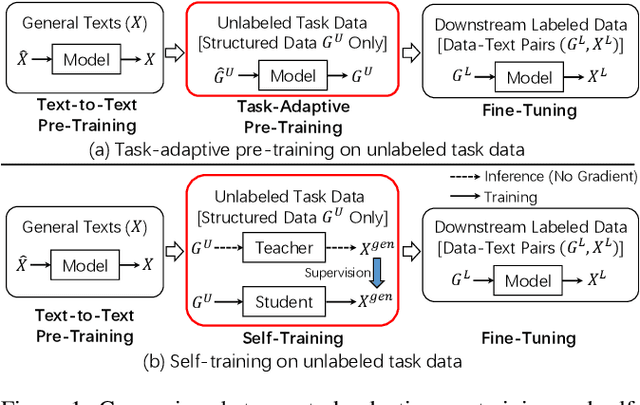


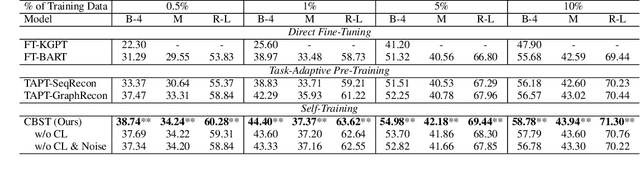
Despite the success of text-to-text pre-trained models in various natural language generation (NLG) tasks, the generation performance is largely restricted by the number of labeled data in downstream tasks, particularly in data-to-text generation tasks. Existing works mostly utilize abundant unlabeled structured data to conduct unsupervised pre-training for task adaption, which fail to model the complex relationship between source structured data and target texts. Thus, we introduce self-training as a better few-shot learner than task-adaptive pre-training, which explicitly captures this relationship via pseudo-labeled data generated by the pre-trained model. To alleviate the side-effect of low-quality pseudo-labeled data during self-training, we propose a novel method called Curriculum-Based Self-Training (CBST) to effectively leverage unlabeled data in a rearranged order determined by the difficulty of text generation. Experimental results show that our method can outperform fine-tuning and task-adaptive pre-training methods, and achieve state-of-the-art performance in the few-shot setting of data-to-text generation.
LaMemo: Language Modeling with Look-Ahead Memory
Apr 26, 2022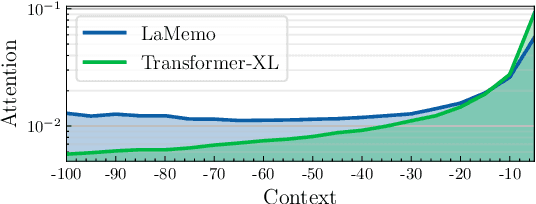



Although Transformers with fully connected self-attentions are powerful to model long-term dependencies, they are struggling to scale to long texts with thousands of words in language modeling. One of the solutions is to equip the model with a recurrence memory. However, existing approaches directly reuse hidden states from the previous segment that encodes contexts in a uni-directional way. As a result, this prohibits the memory to dynamically interact with the current context that provides up-to-date information for token prediction. To remedy this issue, we propose Look-Ahead Memory (LaMemo) that enhances the recurrence memory by incrementally attending to the right-side tokens, and interpolating with the old memory states to maintain long-term information in the history. LaMemo embraces bi-directional attention and segment recurrence with an additional computation overhead only linearly proportional to the memory length. Experiments on widely used language modeling benchmarks demonstrate its superiority over the baselines equipped with different types of memory.
DiscoDVT: Generating Long Text with Discourse-Aware Discrete Variational Transformer
Oct 12, 2021
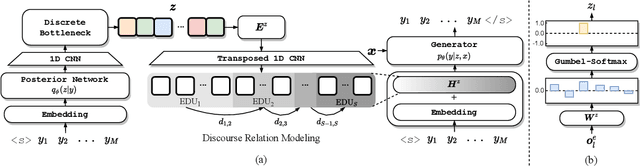

Despite the recent advances in applying pre-trained language models to generate high-quality texts, generating long passages that maintain long-range coherence is yet challenging for these models. In this paper, we propose DiscoDVT, a discourse-aware discrete variational Transformer to tackle the incoherence issue. DiscoDVT learns a discrete variable sequence that summarizes the global structure of the text and then applies it to guide the generation process at each decoding step. To further embed discourse-aware information into the discrete latent representations, we introduce an auxiliary objective to model the discourse relations within the text. We conduct extensive experiments on two open story generation datasets and demonstrate that the latent codes learn meaningful correspondence to the discourse structures that guide the model to generate long texts with better long-range coherence.
JointGT: Graph-Text Joint Representation Learning for Text Generation from Knowledge Graphs
Jun 19, 2021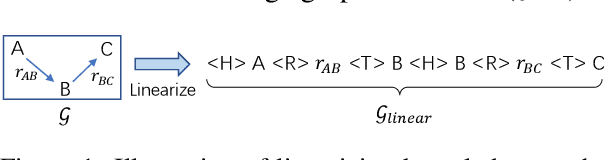

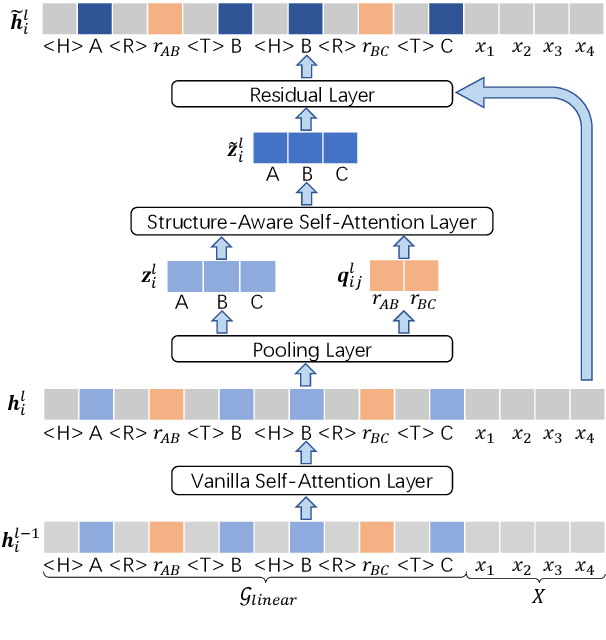
Existing pre-trained models for knowledge-graph-to-text (KG-to-text) generation simply fine-tune text-to-text pre-trained models such as BART or T5 on KG-to-text datasets, which largely ignore the graph structure during encoding and lack elaborate pre-training tasks to explicitly model graph-text alignments. To tackle these problems, we propose a graph-text joint representation learning model called JointGT. During encoding, we devise a structure-aware semantic aggregation module which is plugged into each Transformer layer to preserve the graph structure. Furthermore, we propose three new pre-training tasks to explicitly enhance the graph-text alignment including respective text / graph reconstruction, and graph-text alignment in the embedding space via Optimal Transport. Experiments show that JointGT obtains new state-of-the-art performance on various KG-to-text datasets.
CPM: A Large-scale Generative Chinese Pre-trained Language Model
Dec 01, 2020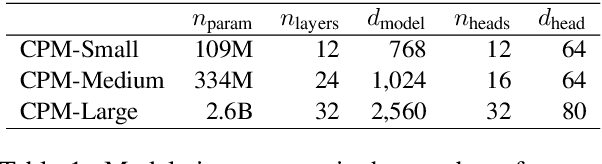

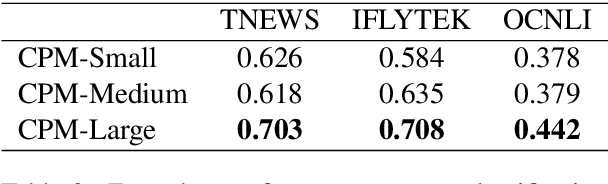
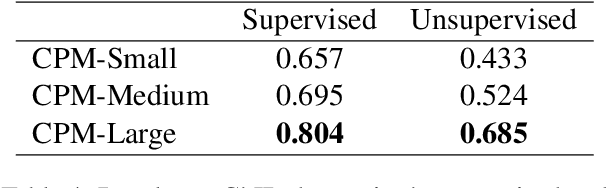
Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3, with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation, cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many NLP tasks in the settings of few-shot (even zero-shot) learning. The code and parameters are available at https://github.com/TsinghuaAI/CPM-Generate.
Generating Commonsense Explanation by Extracting Bridge Concepts from Reasoning Paths
Sep 24, 2020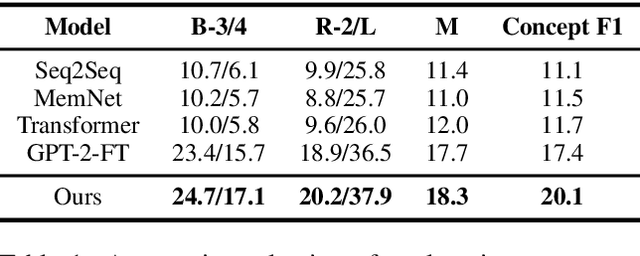
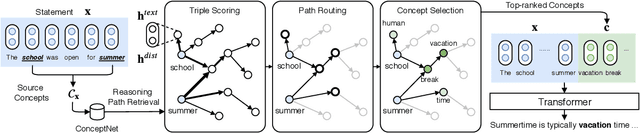


Commonsense explanation generation aims to empower the machine's sense-making capability by generating plausible explanations to statements against commonsense. While this task is easy to human, the machine still struggles to generate reasonable and informative explanations. In this work, we propose a method that first extracts the underlying concepts which are served as \textit{bridges} in the reasoning chain and then integrates these concepts to generate the final explanation. To facilitate the reasoning process, we utilize external commonsense knowledge to build the connection between a statement and the bridge concepts by extracting and pruning multi-hop paths to build a subgraph. We design a bridge concept extraction model that first scores the triples, routes the paths in the subgraph, and further selects bridge concepts with weak supervision at both the triple level and the concept level. We conduct experiments on the commonsense explanation generation task and our model outperforms the state-of-the-art baselines in both automatic and human evaluation.
Language Generation with Multi-Hop Reasoning on Commonsense Knowledge Graph
Sep 24, 2020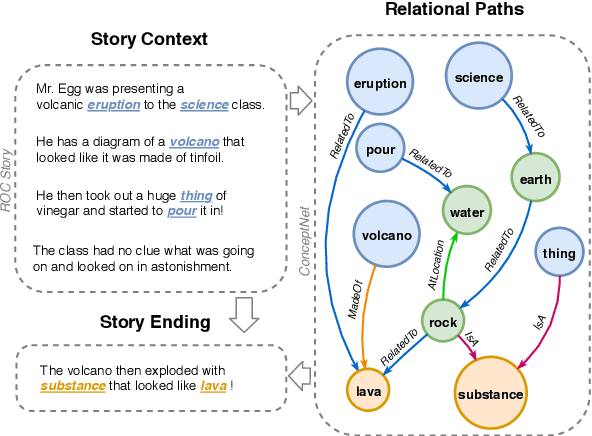
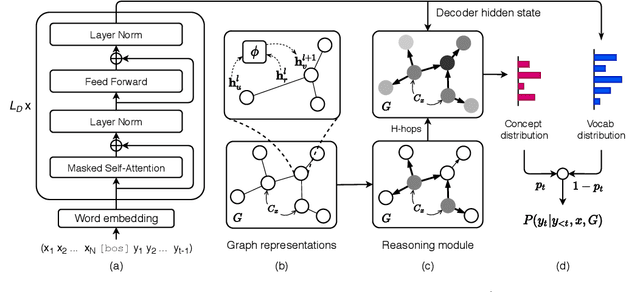

Despite the success of generative pre-trained language models on a series of text generation tasks, they still suffer in cases where reasoning over underlying commonsense knowledge is required during generation. Existing approaches that integrate commonsense knowledge into generative pre-trained language models simply transfer relational knowledge by post-training on individual knowledge triples while ignoring rich connections within the knowledge graph. We argue that exploiting both the structural and semantic information of the knowledge graph facilitates commonsense-aware text generation. In this paper, we propose Generation with Multi-Hop Reasoning Flow (GRF) that enables pre-trained models with dynamic multi-hop reasoning on multi-relational paths extracted from the external commonsense knowledge graph. We empirically show that our model outperforms existing baselines on three text generation tasks that require reasoning over commonsense knowledge. We also demonstrate the effectiveness of the dynamic multi-hop reasoning module with reasoning paths inferred by the model that provide rationale to the generation.