 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: A Multi-Agent System for Autonomous Physical Reasoning in Seismological Science
Mar 22, 2026Inferring the physical mechanisms that govern earthquake sequences from indirect geophysical observations remains difficult, particularly across tectonically distinct environments where similar seismic patterns can reflect different underlying processes. Current interpretations rely heavily on the expert synthesis of catalogs, spatiotemporal statistics, and candidate physical models, limiting reproducibility and the systematic transfer of insight across settings. Here we present TRACE (Trans-perspective Reasoning and Automated Comprehensive Evaluator), a multi-agent system that combines large language model planning with formal seismological constraints to derive auditable, physically grounded mechanistic inference from raw observations. Applied to the 2019 Ridgecrest sequence, TRACE autonomously identifies stress-perturbation-induced delayed triggering, resolving the cascading interaction between the Mw 6.4 and Mw 7.1 mainshocks; in the Santorini-Kolumbo case, the system identifies a structurally guided intrusion model, distinguishing fault-channeled episodic migration from the continuous propagation expected in homogeneous crustal failure. By providing a generalizable logical infrastructure for interpreting heterogeneous seismic phenomena, TRACE advances the field from expert-dependent analysis toward knowledge-guided autonomous discovery in Earth sciences.
JointGT: Graph-Text Joint Representation Learning for Text Generation from Knowledge Graphs
Jun 19, 2021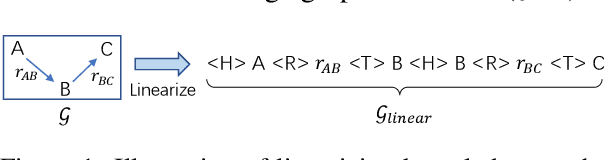

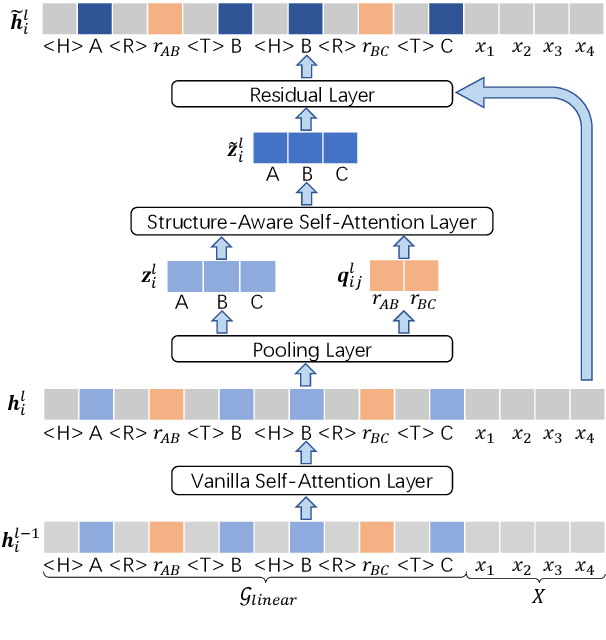
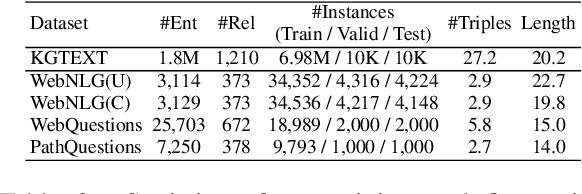
Existing pre-trained models for knowledge-graph-to-text (KG-to-text) generation simply fine-tune text-to-text pre-trained models such as BART or T5 on KG-to-text datasets, which largely ignore the graph structure during encoding and lack elaborate pre-training tasks to explicitly model graph-text alignments. To tackle these problems, we propose a graph-text joint representation learning model called JointGT. During encoding, we devise a structure-aware semantic aggregation module which is plugged into each Transformer layer to preserve the graph structure. Furthermore, we propose three new pre-training tasks to explicitly enhance the graph-text alignment including respective text / graph reconstruction, and graph-text alignment in the embedding space via Optimal Transport. Experiments show that JointGT obtains new state-of-the-art performance on various KG-to-text datasets.
Shapley Interpretation and Activation in Neural Networks
Sep 17, 2019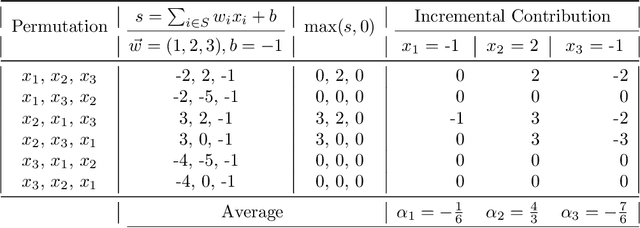
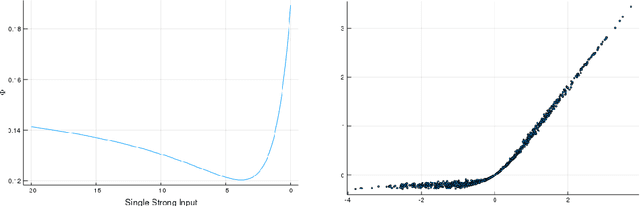
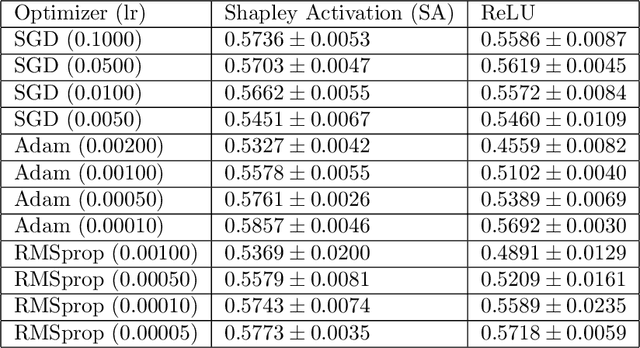
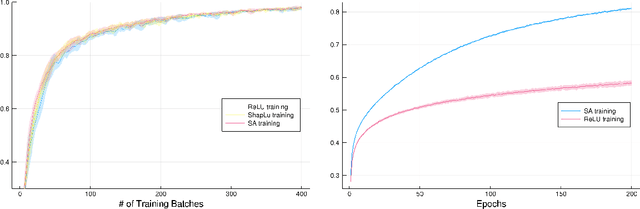
We propose a novel Shapley value approach to help address neural networks' interpretability and "vanishing gradient" problems. Our method is based on an accurate analytical approximation to the Shapley value of a neuron with ReLU activation. This analytical approximation admits a linear propagation of relevance across neural network layers, resulting in a simple, fast and sensible interpretation of neural networks' decision making process. We then derived a globally continuous and non-vanishing Shapley gradient, which can replace the conventional gradient in training neural network layers with ReLU activation, and leading to better training performance. We further derived a Shapley Activation (SA) function, which is a close approximation to ReLU but features the Shapley gradient. The SA is easy to implement in existing machine learning frameworks. Numerical tests show that SA consistently outperforms ReLU in training convergence, accuracy and stability.