 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play Knowledge Injection for Pre-trained Language Models
May 28, 2023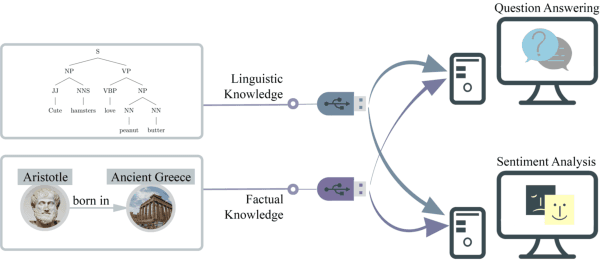
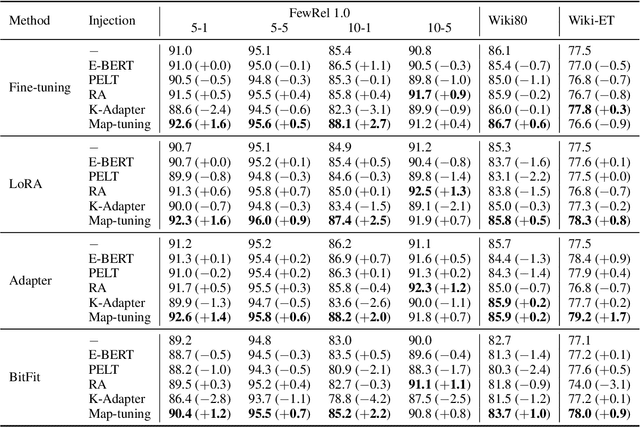
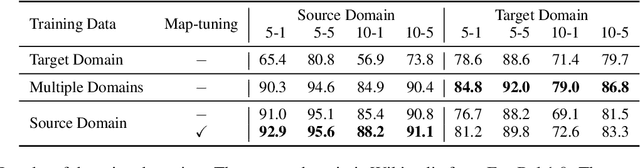
Injecting external knowledge can improve the performance of pre-trained language models (PLMs) on various downstream NLP tasks. However, massive retraining is required to deploy new knowledge injection methods or knowledge bases for downstream tasks. In this work, we are the first to study how to improve the flexibility and efficiency of knowledge injection by reusing existing downstream models. To this end, we explore a new paradigm plug-and-play knowledge injection, where knowledge bases are injected into frozen existing downstream models by a knowledge plugin. Correspondingly, we propose a plug-and-play injection method map-tuning, which trains a mapping of knowledge embeddings to enrich model inputs with mapped embeddings while keeping model parameters frozen. Experimental results on three knowledge-driven NLP tasks show that existing injection methods are not suitable for the new paradigm, while map-tuning effectively improves the performance of downstream models. Moreover, we show that a frozen downstream model can be well adapted to different domains with different mapping networks of domain knowledge. Our code and models are available at https://github.com/THUNLP/Knowledge-Plugin.
UNTER: A Unified Knowledge Interface for Enhancing Pre-trained Language Models
May 05, 2023Recent research demonstrates that external knowledge injection can advance pre-trained language models (PLMs) in a variety of downstream NLP tasks. However, existing knowledge injection methods are either applicable to structured knowledge or unstructured knowledge, lacking a unified usage. In this paper, we propose a UNified knowledge inTERface, UNTER, to provide a unified perspective to exploit both structured knowledge and unstructured knowledge. In UNTER, we adopt the decoder as a unified knowledge interface, aligning span representations obtained from the encoder with their corresponding knowledge. This approach enables the encoder to uniformly invoke span-related knowledge from its parameters for downstream applications. Experimental results show that, with both forms of knowledge injected, UNTER gains continuous improvements on a series of knowledge-driven NLP tasks, including entity typing, named entity recognition and relation extraction, especially in low-resource scenarios.
A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models
Mar 23, 2022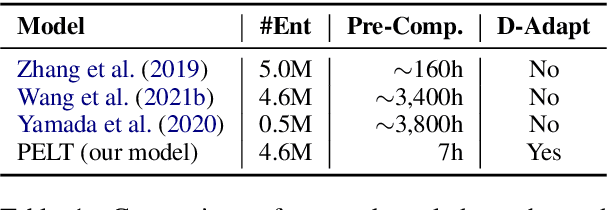
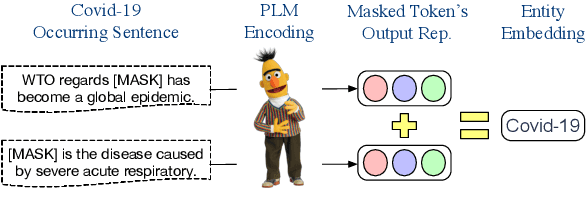
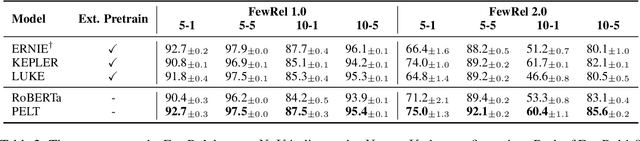

Pre-trained language models (PLMs) cannot well recall rich factual knowledge of entities exhibited in large-scale corpora, especially those rare entities. In this paper, we propose to build a simple but effective Pluggable Entity Lookup Table (PELT) on demand by aggregating the entity's output representations of multiple occurrences in the corpora. PELT can be compatibly plugged as inputs to infuse supplemental entity knowledge into PLMs. Compared to previous knowledge-enhanced PLMs, PELT only requires 0.2%-5% pre-computation with capability of acquiring knowledge from out-of-domain corpora for domain adaptation scenario. The experiments on knowledge-related tasks demonstrate that our method, PELT, can flexibly and effectively transfer entity knowledge from related corpora into PLMs with different architectures.
Pack Together: Entity and Relation Extraction with Levitated Marker
Sep 13, 2021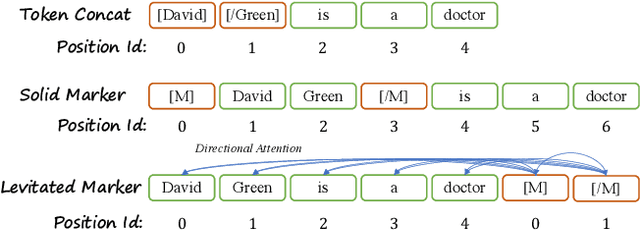
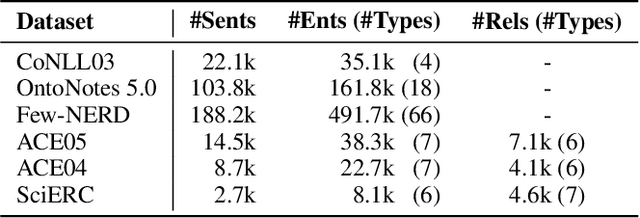
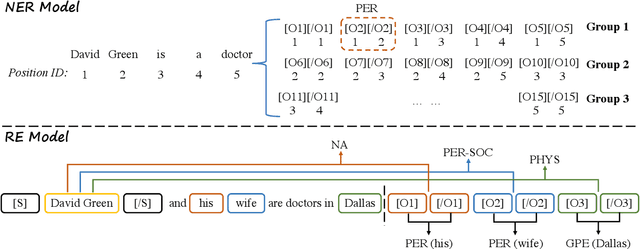
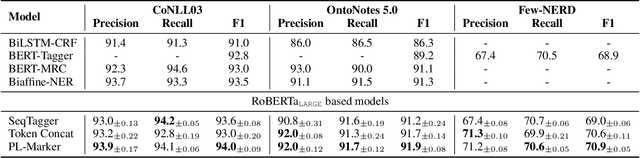
Named Entity Recognition (NER) and Relation Extraction (RE) are the core sub-tasks for information extraction. Many recent works formulate these two tasks as the span (pair) classification problem, and thus focus on investigating how to obtain a better span representation from the pre-trained encoder. However, a major limitation of existing works is that they ignore the dependencies between spans (pairs). In this work, we propose a novel span representation approach, named Packed Levitated Markers, to consider the dependencies between the spans (pairs) by strategically packing the markers in the encoder. In particular, we propose a group packing strategy to enable our model to process massive spans together to consider their dependencies with limited resources. Furthermore, for those more complicated span pair classification tasks, we design a subject-oriented packing strategy, which packs each subject and all its objects into an instance to model the dependencies between the same-subject span pairs. Our experiments show that our model with packed levitated markers outperforms the sequence labeling model by 0.4%-1.9% F1 on three flat NER tasks, beats the token concat model on six NER benchmarks, and obtains a 3.5%-3.6% strict relation F1 improvement with higher speed over previous SOTA models on ACE04 and ACE05. Code and models are publicly available at https://github.com/thunlp/PL-Marker.
TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference
May 25, 2021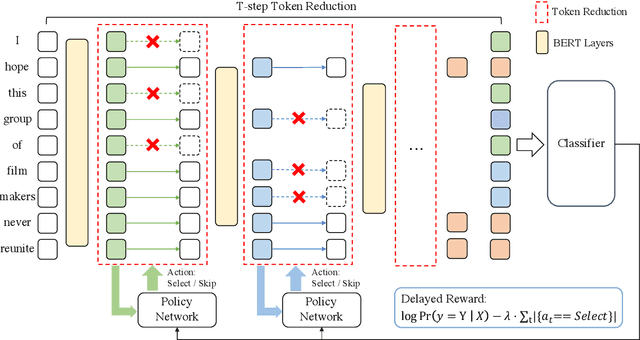

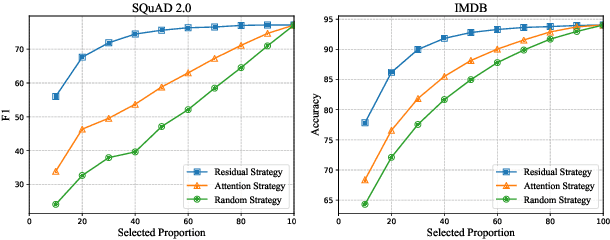
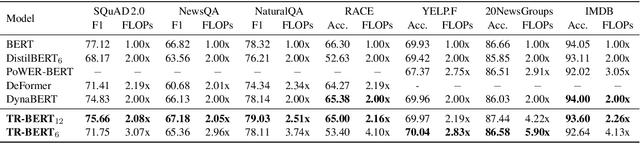
Existing pre-trained language models (PLMs) are often computationally expensive in inference, making them impractical in various resource-limited real-world applications. To address this issue, we propose a dynamic token reduction approach to accelerate PLMs' inference, named TR-BERT, which could flexibly adapt the layer number of each token in inference to avoid redundant calculation. Specially, TR-BERT formulates the token reduction process as a multi-step token selection problem and automatically learns the selection strategy via reinforcement learning. The experimental results on several downstream NLP tasks show that TR-BERT is able to speed up BERT by 2-5 times to satisfy various performance demands. Moreover, TR-BERT can also achieve better performance with less computation in a suite of long-text tasks since its token-level layer number adaption greatly accelerates the self-attention operation in PLMs. The source code and experiment details of this paper can be obtained from https://github.com/thunlp/TR-BERT.
CPM: A Large-scale Generative Chinese Pre-trained Language Model
Dec 01, 2020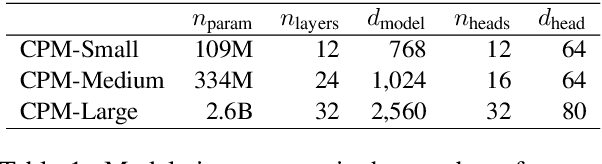

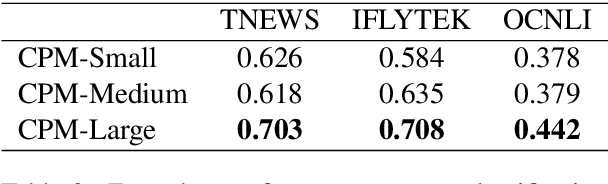
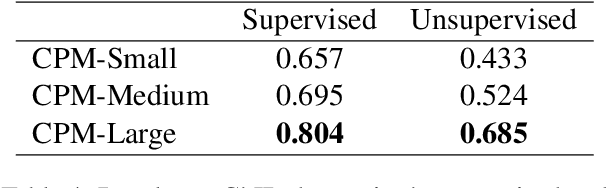
Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3, with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation, cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many NLP tasks in the settings of few-shot (even zero-shot) learning. The code and parameters are available at https://github.com/TsinghuaAI/CPM-Generate.
Coreferential Reasoning Learning for Language Representation
Apr 15, 2020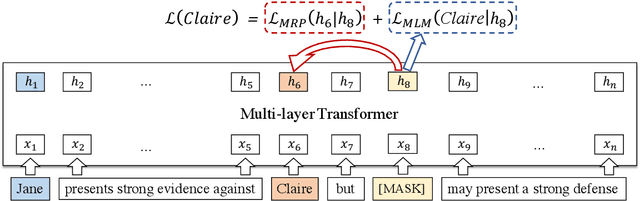

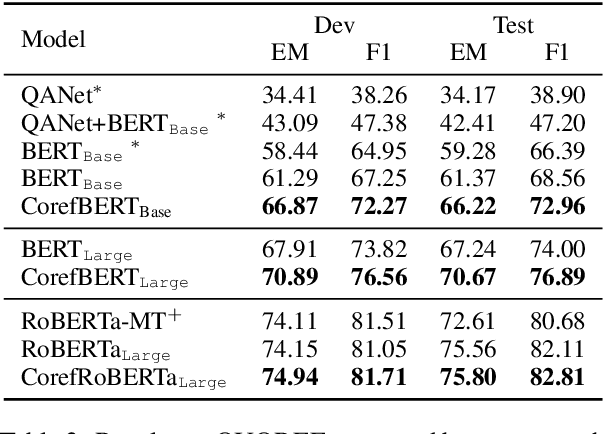
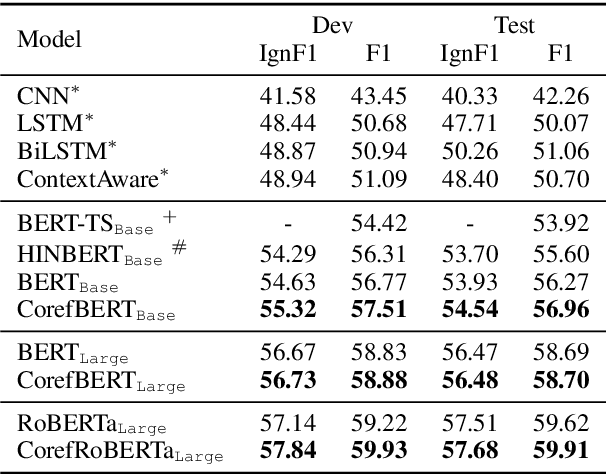
Language representation models such as BERT could effectively capture contextual semantic information from plain text, and have been proved to achieve promising results in lots of downstream NLP tasks with appropriate fine-tuning. However, existing language representation models seldom consider coreference explicitly, the relationship between noun phrases referring to the same entity, which is essential to a coherent understanding of the whole discourse. To address this issue, we present CorefBERT, a novel language representation model designed to capture the relations between noun phrases that co-refer to each other. According to the experimental results, compared with existing baseline models, the CorefBERT model has made significant progress on several downstream NLP tasks that require coreferential reasoning, while maintaining comparable performance to previous models on other common NLP tasks.
Multi-Paragraph Reasoning with Knowledge-enhanced Graph Neural Network
Nov 06, 2019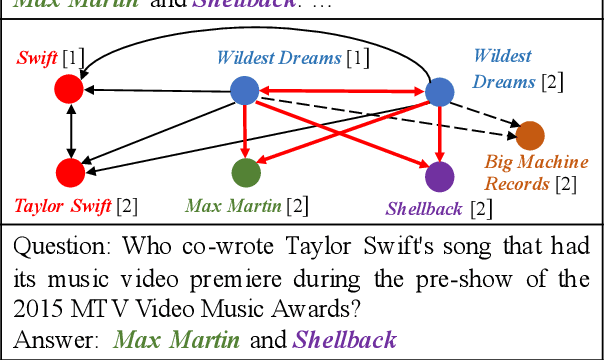
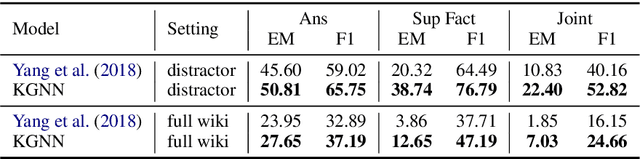
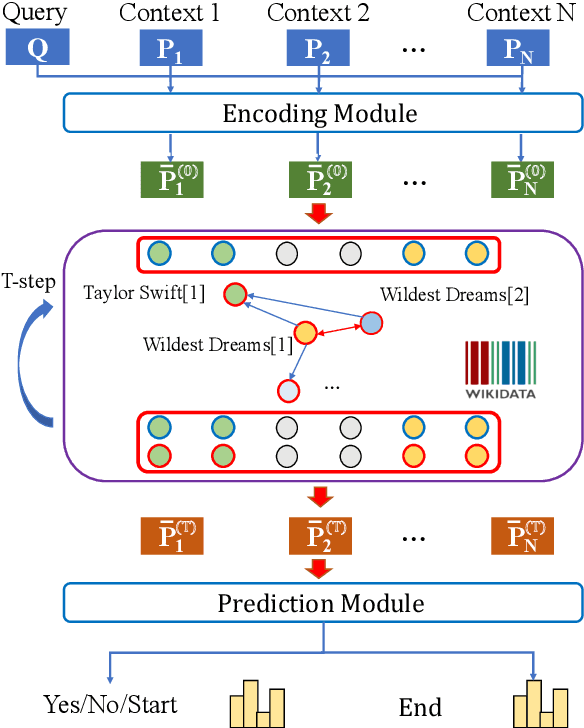
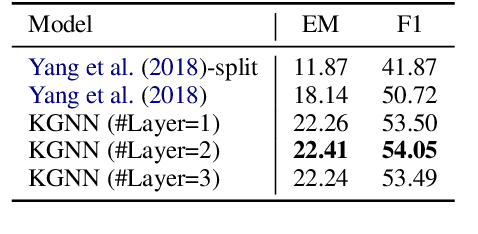
Multi-paragraph reasoning is indispensable for open-domain question answering (OpenQA), which receives less attention in the current OpenQA systems. In this work, we propose a knowledge-enhanced graph neural network (KGNN), which performs reasoning over multiple paragraphs with entities. To explicitly capture the entities' relatedness, KGNN utilizes relational facts in knowledge graph to build the entity graph. The experimental results show that KGNN outperforms in both distractor and full wiki settings than baselines methods on HotpotQA dataset. And our further analysis illustrates KGNN is effective and robust with more retrieved paragraphs.
DocRED: A Large-Scale Document-Level Relation Extraction Dataset
Jun 17, 2019
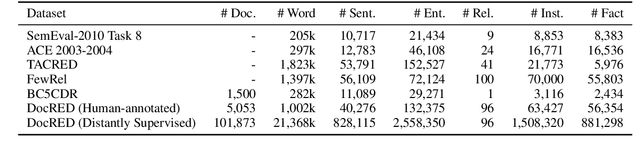

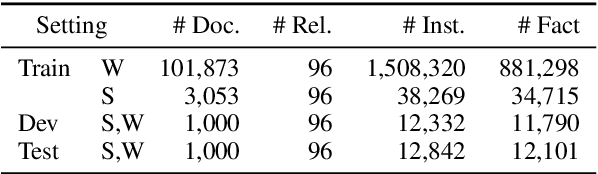
Multiple entities in a document generally exhibit complex inter-sentence relations, and cannot be well handled by existing relation extraction (RE) methods that typically focus on extracting intra-sentence relations for single entity pairs. In order to accelerate the research on document-level RE, we introduce DocRED, a new dataset constructed from Wikipedia and Wikidata with three features: (1) DocRED annotates both named entities and relations, and is the largest human-annotated dataset for document-level RE from plain text; (2) DocRED requires reading multiple sentences in a document to extract entities and infer their relations by synthesizing all information of the document; (3) along with the human-annotated data, we also offer large-scale distantly supervised data, which enables DocRED to be adopted for both supervised and weakly supervised scenarios. In order to verify the challenges of document-level RE, we implement recent state-of-the-art methods for RE and conduct a thorough evaluation of these methods on DocRED. Empirical results show that DocRED is challenging for existing RE methods, which indicates that document-level RE remains an open problem and requires further efforts. Based on the detailed analysis on the experiments, we discuss multiple promising directions for future research.
Rethinking the Form of Latent States in Image Captioning
Jul 26, 2018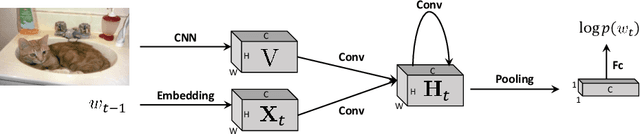
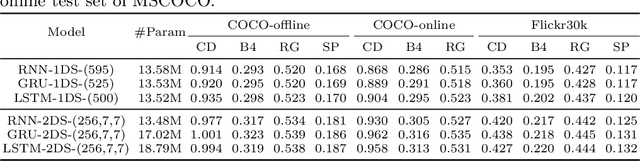


RNNs and their variants have been widely adopted for image captioning. In RNNs, the production of a caption is driven by a sequence of latent states. Existing captioning models usually represent latent states as vectors, taking this practice for granted. We rethink this choice and study an alternative formulation, namely using two-dimensional maps to encode latent states. This is motivated by the curiosity about a question: how the spatial structures in the latent states affect the resultant captions? Our study on MSCOCO and Flickr30k leads to two significant observations. First, the formulation with 2D states is generally more effective in captioning, consistently achieving higher performance with comparable parameter sizes. Second, 2D states preserve spatial locality. Taking advantage of this, we visually reveal the internal dynamics in the process of caption generation, as well as the connections between input visual domain and output linguistic domain.