 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoreferential Reasoning Learning for Language Representation
Apr 15, 2020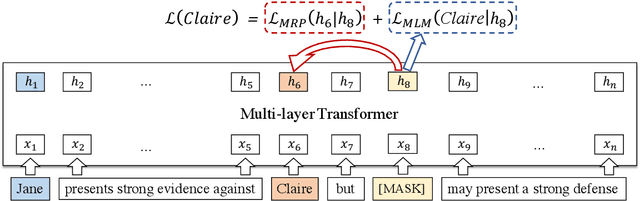

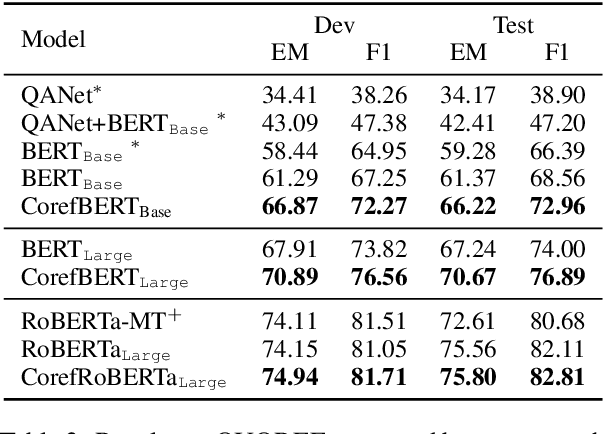
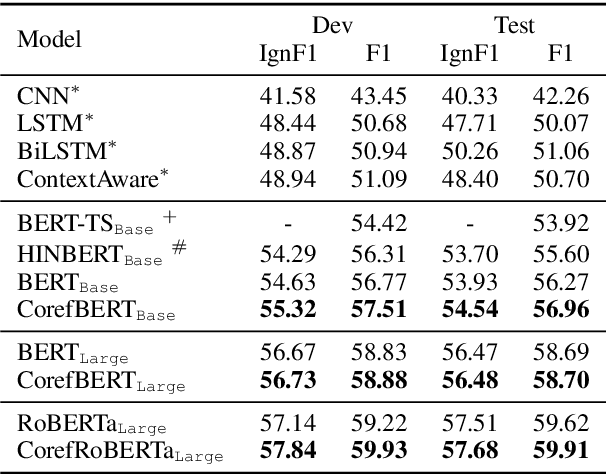
Language representation models such as BERT could effectively capture contextual semantic information from plain text, and have been proved to achieve promising results in lots of downstream NLP tasks with appropriate fine-tuning. However, existing language representation models seldom consider coreference explicitly, the relationship between noun phrases referring to the same entity, which is essential to a coherent understanding of the whole discourse. To address this issue, we present CorefBERT, a novel language representation model designed to capture the relations between noun phrases that co-refer to each other. According to the experimental results, compared with existing baseline models, the CorefBERT model has made significant progress on several downstream NLP tasks that require coreferential reasoning, while maintaining comparable performance to previous models on other common NLP tasks.
Lexical Sememe Prediction using Dictionary Definitions by Capturing Local Semantic Correspondence
Jan 16, 2020
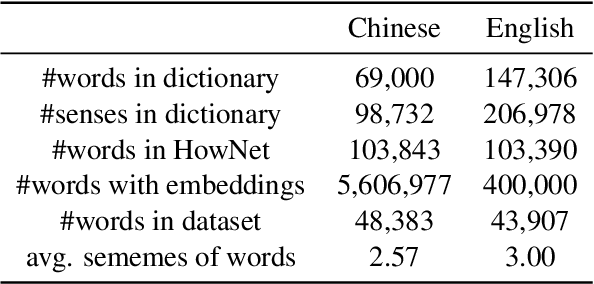


Sememes, defined as the minimum semantic units of human languages in linguistics, have been proven useful in many NLP tasks. Since manual construction and update of sememe knowledge bases (KBs) are costly, the task of automatic sememe prediction has been proposed to assist sememe annotation. In this paper, we explore the approach of applying dictionary definitions to predicting sememes for unannotated words. We find that sememes of each word are usually semantically matched to different words in its dictionary definition, and we name this matching relationship local semantic correspondence. Accordingly, we propose a Sememe Correspondence Pooling (SCorP) model, which is able to capture this kind of matching to predict sememes. We evaluate our model and baseline methods on a famous sememe KB HowNet and find that our model achieves state-of-the-art performance. Moreover, further quantitative analysis shows that our model can properly learn the local semantic correspondence between sememes and words in dictionary definitions, which explains the effectiveness of our model. The source codes of this paper can be obtained from https://github.com/thunlp/scorp.
Using BERT for Word Sense Disambiguation
Sep 18, 2019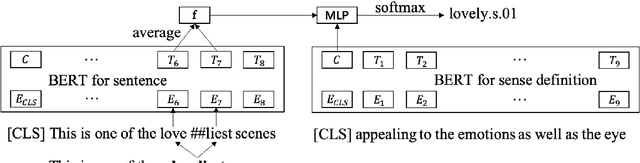

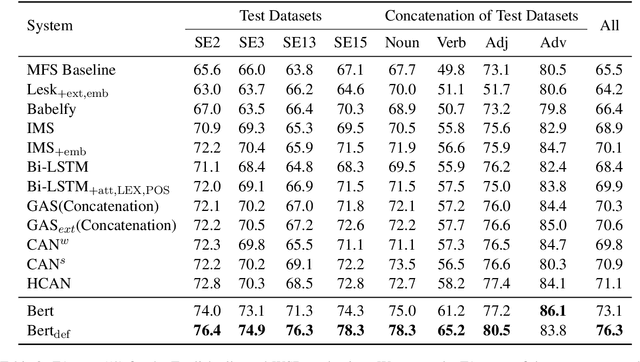
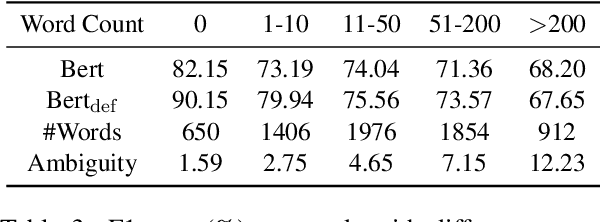
Word Sense Disambiguation (WSD), which aims to identify the correct sense of a given polyseme, is a long-standing problem in NLP. In this paper, we propose to use BERT to extract better polyseme representations for WSD and explore several ways of combining BERT and the classifier. We also utilize sense definitions to train a unified classifier for all words, which enables the model to disambiguate unseen polysemes. Experiments show that our model achieves the state-of-the-art results on the standard English All-word WSD evaluation.