 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Sememe Prediction using Dictionary Definitions by Capturing Local Semantic Correspondence
Paper and Code

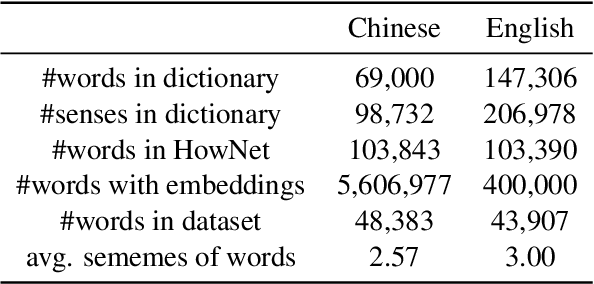


Sememes, defined as the minimum semantic units of human languages in linguistics, have been proven useful in many NLP tasks. Since manual construction and update of sememe knowledge bases (KBs) are costly, the task of automatic sememe prediction has been proposed to assist sememe annotation. In this paper, we explore the approach of applying dictionary definitions to predicting sememes for unannotated words. We find that sememes of each word are usually semantically matched to different words in its dictionary definition, and we name this matching relationship local semantic correspondence. Accordingly, we propose a Sememe Correspondence Pooling (SCorP) model, which is able to capture this kind of matching to predict sememes. We evaluate our model and baseline methods on a famous sememe KB HowNet and find that our model achieves state-of-the-art performance. Moreover, further quantitative analysis shows that our model can properly learn the local semantic correspondence between sememes and words in dictionary definitions, which explains the effectiveness of our model. The source codes of this paper can be obtained from https://github.com/thunlp/scorp.