 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoreoNet: Towards Music to Dance Synthesis with Choreographic Action Unit
Sep 16, 2020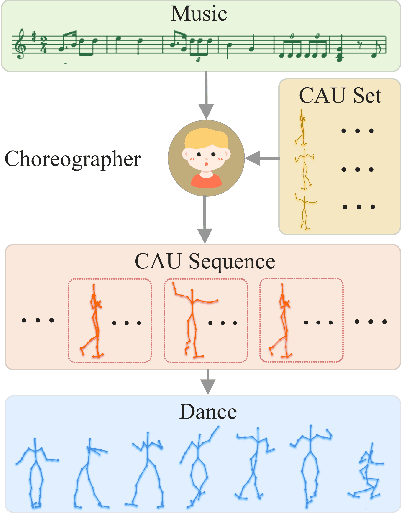

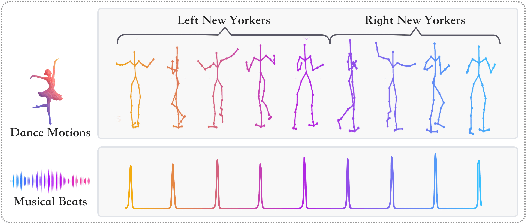
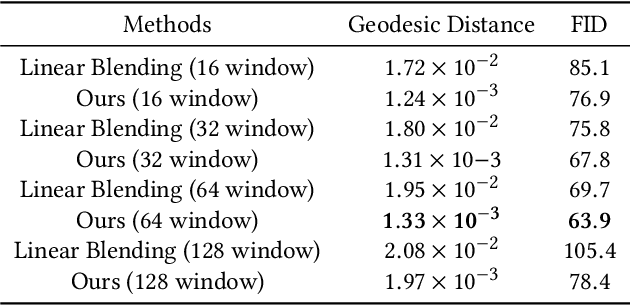
Dance and music are two highly correlated artistic forms. Synthesizing dance motions has attracted much attention recently. Most previous works conduct music-to-dance synthesis via directly music to human skeleton keypoints mapping. Meanwhile, human choreographers design dance motions from music in a two-stage manner: they firstly devise multiple choreographic dance units (CAUs), each with a series of dance motions, and then arrange the CAU sequence according to the rhythm, melody and emotion of the music. Inspired by these, we systematically study such two-stage choreography approach and construct a dataset to incorporate such choreography knowledge. Based on the constructed dataset, we design a two-stage music-to-dance synthesis framework ChoreoNet to imitate human choreography procedure. Our framework firstly devises a CAU prediction model to learn the mapping relationship between music and CAU sequences. Afterwards, we devise a spatial-temporal inpainting model to convert the CAU sequence into continuous dance motions. Experimental results demonstrate that the proposed ChoreoNet outperforms baseline methods (0.622 in terms of CAU BLEU score and 1.59 in terms of user study score).
Corrective feedback, emphatic speech synthesis, visual-speech exaggeration, pronunciation learning
Sep 12, 2020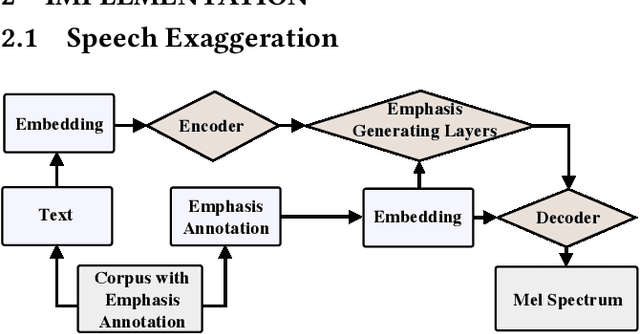
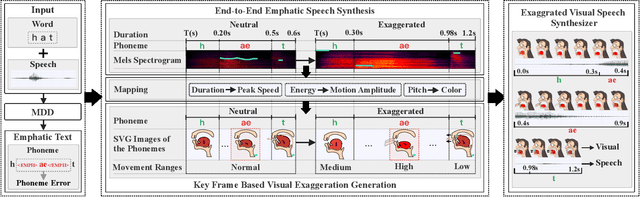
To provide more discriminative feedback for the second language (L2) learners to better identify their mispronunciation, we propose a method for exaggerated visual-speech feedback in computer-assisted pronunciation training (CAPT). The speech exaggeration is realized by an emphatic speech generation neural network based on Tacotron, while the visual exaggeration is accomplished by ADC Viseme Blending, namely increasing Amplitude of movement, extending the phone's Duration and enhancing the color Contrast. User studies show that exaggerated feedback outperforms non-exaggerated version on helping learners with pronunciation identification and pronunciation improvement.
Mining Unfollow Behavior in Large-Scale Online Social Networks via Spatial-Temporal Interaction
Nov 17, 2019
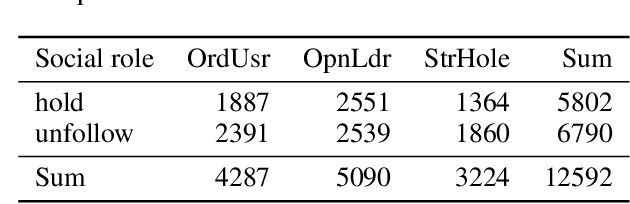
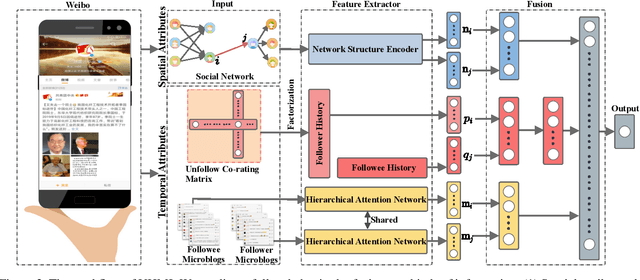
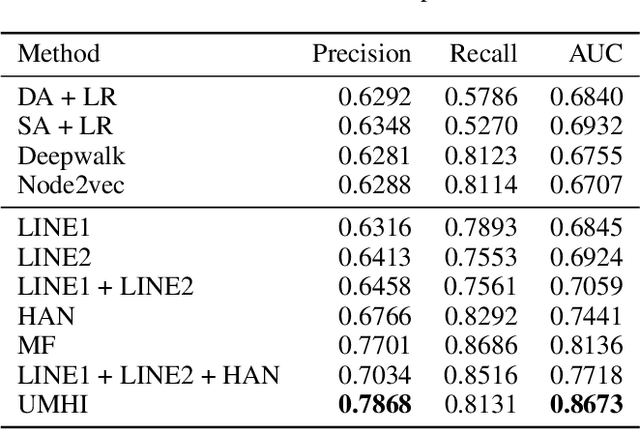
Online Social Networks (OSNs) evolve through two pervasive behaviors: follow and unfollow, which respectively signify relationship creation and relationship dissolution. Researches on social network evolution mainly focus on the follow behavior, while the unfollow behavior has largely been ignored. Mining unfollow behavior is challenging because user's decision on unfollow is not only affected by the simple combination of user's attributes like informativeness and reciprocity, but also affected by the complex interaction among them. Meanwhile, prior datasets seldom contain sufficient records for inferring such complex interaction. To address these issues, we first construct a large-scale real-world Weibo dataset, which records detailed post content and relationship dynamics of 1.8 million Chinese users. Next, we define user's attributes as two categories: spatial attributes (e.g., social role of user) and temporal attributes (e.g., post content of user). Leveraging the constructed dataset, we systematically study how the interaction effects between user's spatial and temporal attributes contribute to the unfollow behavior. Afterwards, we propose a novel unified model with heterogeneous information (UMHI) for unfollow prediction. Specifically, our UMHI model: 1) captures user's spatial attributes through social network structure; 2) infers user's temporal attributes through user-posted content and unfollow history; and 3) models the interaction between spatial and temporal attributes by the nonlinear MLP layers. Comprehensive evaluations on the constructed dataset demonstrate that the proposed UMHI model outperforms baseline methods by 16.44% on average in terms of precision. In addition, factor analyses verify that both spatial attributes and temporal attributes are essential for mining unfollow behavior.