 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusTrack: One-Stage Focus-and-Suppress Framework for 3D Point Cloud Object Tracking
Feb 27, 2026In 3D point cloud object tracking, the motion-centric methods have emerged as a promising avenue due to its superior performance in modeling inter-frame motion. However, existing two-stage motion-based approaches suffer from fundamental limitations: (1) error accumulation due to decoupled optimization caused by explicit foreground segmentation prior to motion estimation, and (2) computational bottlenecks from sequential processing. To address these challenges, we propose FocusTrack, a novel one-stage paradigms tracking framework that unifies motion-semantics co-modeling through two core innovations: Inter-frame Motion Modeling (IMM) and Focus-and-Suppress Attention. The IMM module employs a temp-oral-difference siamese encoder to capture global motion patterns between adjacent frames. The Focus-and-Suppress attention that enhance the foreground semantics via motion-salient feature gating and suppress the background noise based on the temporal-aware motion context from IMM without explicit segmentation. Based on above two designs, FocusTrack enables end-to-end training with compact one-stage pipeline. Extensive experiments on prominent 3D tracking benchmarks, such as KITTI, nuScenes, and Waymo, demonstrate that the FocusTrack achieves new SOTA performance while running at a high speed with 105 FPS.
CompTrack: Information Bottleneck-Guided Low-Rank Dynamic Token Compression for Point Cloud Tracking
Nov 19, 20253D single object tracking (SOT) in LiDAR point clouds is a critical task in computer vision and autonomous driving. Despite great success having been achieved, the inherent sparsity of point clouds introduces a dual-redundancy challenge that limits existing trackers: (1) vast spatial redundancy from background noise impairs accuracy, and (2) informational redundancy within the foreground hinders efficiency. To tackle these issues, we propose CompTrack, a novel end-to-end framework that systematically eliminates both forms of redundancy in point clouds. First, CompTrack incorporates a Spatial Foreground Predictor (SFP) module to filter out irrelevant background noise based on information entropy, addressing spatial redundancy. Subsequently, its core is an Information Bottleneck-guided Dynamic Token Compression (IB-DTC) module that eliminates the informational redundancy within the foreground. Theoretically grounded in low-rank approximation, this module leverages an online SVD analysis to adaptively compress the redundant foreground into a compact and highly informative set of proxy tokens. Extensive experiments on KITTI, nuScenes and Waymo datasets demonstrate that CompTrack achieves top-performing tracking performance with superior efficiency, running at a real-time 90 FPS on a single RTX 3090 GPU.
Multi-object Tracking by Detection and Query: an efficient end-to-end manner
Nov 09, 2024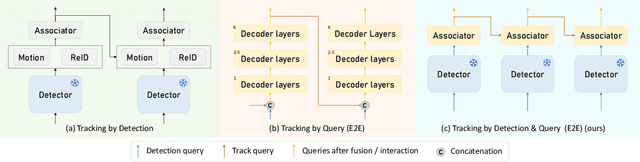
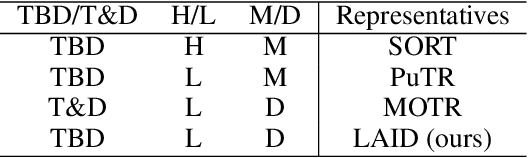
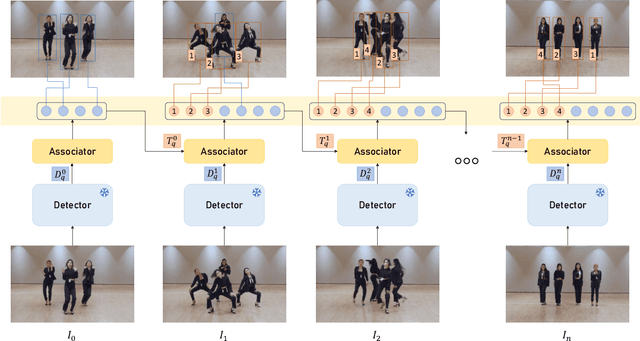
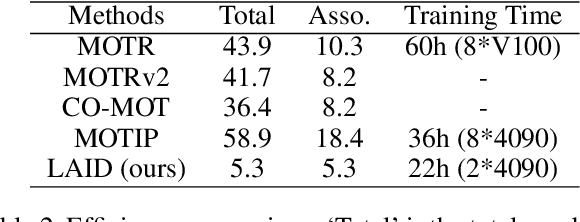
Multi-object tracking is advancing through two dominant paradigms: traditional tracking by detection and newly emerging tracking by query. In this work, we fuse them together and propose the tracking-by-detection-and-query paradigm, which is achieved by a Learnable Associator. Specifically, the basic information interaction module and the content-position alignment module are proposed for thorough information Interaction among object queries. Tracking results are directly Decoded from these queries. Hence, we name the method as LAID. Compared to tracking-by-query models, LAID achieves competitive tracking accuracy with notably higher training efficiency. With regard to tracking-by-detection methods, experimental results on DanceTrack show that LAID significantly surpasses the state-of-the-art heuristic method by 3.9% on HOTA metric and 6.1% on IDF1 metric. On SportsMOT, LAID also achieves the best score on HOTA metric. By holding low training cost, strong tracking capabilities, and an elegant end-to-end approach all at once, LAID presents a forward-looking direction for the field.
PillarHist: A Quantization-aware Pillar Feature Encoder based on Height-aware Histogram
May 29, 2024



Real-time and high-performance 3D object detection plays a critical role in autonomous driving and robotics. Recent pillar-based 3D object detectors have gained significant attention due to their compact representation and low computational overhead, making them suitable for onboard deployment and quantization. However, existing pillar-based detectors still suffer from information loss along height dimension and large numerical distribution difference during pillar feature encoding (PFE), which severely limits their performance and quantization potential. To address above issue, we first unveil the importance of different input information during PFE and identify the height dimension as a key factor in enhancing 3D detection performance. Motivated by this observation, we propose a height-aware pillar feature encoder named PillarHist. Specifically, PillarHist statistics the discrete distribution of points at different heights within one pillar. This simple yet effective design greatly preserves the information along the height dimension while significantly reducing the computation overhead of the PFE. Meanwhile, PillarHist also constrains the arithmetic distribution of PFE input to a stable range, making it quantization-friendly. Notably, PillarHist operates exclusively within the PFE stage to enhance performance, enabling seamless integration into existing pillar-based methods without introducing complex operations. Extensive experiments show the effectiveness of PillarHist in terms of both efficiency and performance.
LiDAR-PTQ: Post-Training Quantization for Point Cloud 3D Object Detection
Jan 29, 2024Due to highly constrained computing power and memory, deploying 3D lidar-based detectors on edge devices equipped in autonomous vehicles and robots poses a crucial challenge. Being a convenient and straightforward model compression approach, Post-Training Quantization (PTQ) has been widely adopted in 2D vision tasks. However, applying it directly to 3D lidar-based tasks inevitably leads to performance degradation. As a remedy, we propose an effective PTQ method called LiDAR-PTQ, which is particularly curated for 3D lidar detection (both SPConv-based and SPConv-free). Our LiDAR-PTQ features three main components, \textbf{(1)} a sparsity-based calibration method to determine the initialization of quantization parameters, \textbf{(2)} a Task-guided Global Positive Loss (TGPL) to reduce the disparity between the final predictions before and after quantization, \textbf{(3)} an adaptive rounding-to-nearest operation to minimize the layerwise reconstruction error. Extensive experiments demonstrate that our LiDAR-PTQ can achieve state-of-the-art quantization performance when applied to CenterPoint (both Pillar-based and Voxel-based). To our knowledge, for the very first time in lidar-based 3D detection tasks, the PTQ INT8 model's accuracy is almost the same as the FP32 model while enjoying $3\times$ inference speedup. Moreover, our LiDAR-PTQ is cost-effective being $30\times$ faster than the quantization-aware training method. Code will be released at \url{https://github.com/StiphyJay/LiDAR-PTQ}.
Attributes Grouping and Mining Hashing for Fine-Grained Image Retrieval
Nov 10, 2023In recent years, hashing methods have been popular in the large-scale media search for low storage and strong representation capabilities. To describe objects with similar overall appearance but subtle differences, more and more studies focus on hashing-based fine-grained image retrieval. Existing hashing networks usually generate both local and global features through attention guidance on the same deep activation tensor, which limits the diversity of feature representations. To handle this limitation, we substitute convolutional descriptors for attention-guided features and propose an Attributes Grouping and Mining Hashing (AGMH), which groups and embeds the category-specific visual attributes in multiple descriptors to generate a comprehensive feature representation for efficient fine-grained image retrieval. Specifically, an Attention Dispersion Loss (ADL) is designed to force the descriptors to attend to various local regions and capture diverse subtle details. Moreover, we propose a Stepwise Interactive External Attention (SIEA) to mine critical attributes in each descriptor and construct correlations between fine-grained attributes and objects. The attention mechanism is dedicated to learning discrete attributes, which will not cost additional computations in hash codes generation. Finally, the compact binary codes are learned by preserving pairwise similarities. Experimental results demonstrate that AGMH consistently yields the best performance against state-of-the-art methods on fine-grained benchmark datasets.
Detecting Any Human-Object Interaction Relationship: Universal HOI Detector with Spatial Prompt Learning on Foundation Models
Nov 07, 2023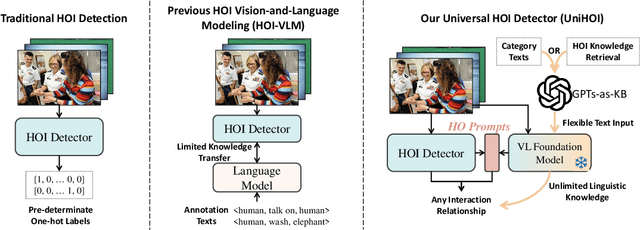
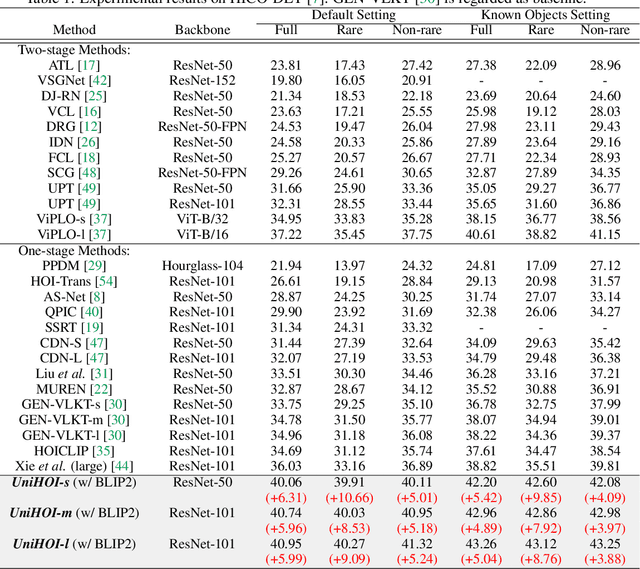
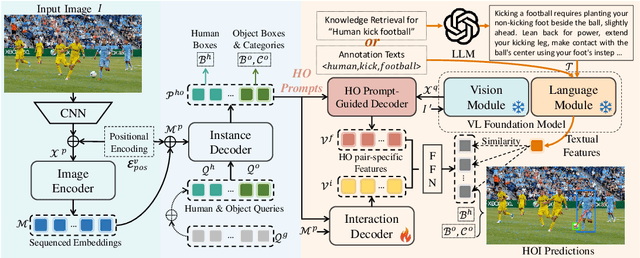
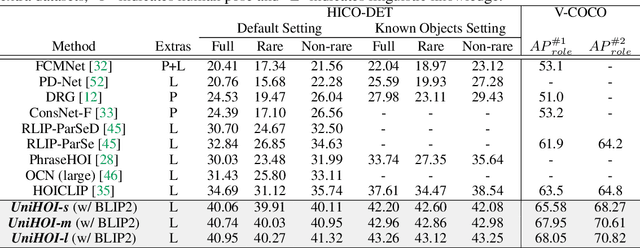
Human-object interaction (HOI) detection aims to comprehend the intricate relationships between humans and objects, predicting $<human, action, object>$ triplets, and serving as the foundation for numerous computer vision tasks. The complexity and diversity of human-object interactions in the real world, however, pose significant challenges for both annotation and recognition, particularly in recognizing interactions within an open world context. This study explores the universal interaction recognition in an open-world setting through the use of Vision-Language (VL) foundation models and large language models (LLMs). The proposed method is dubbed as \emph{\textbf{UniHOI}}. We conduct a deep analysis of the three hierarchical features inherent in visual HOI detectors and propose a method for high-level relation extraction aimed at VL foundation models, which we call HO prompt-based learning. Our design includes an HO Prompt-guided Decoder (HOPD), facilitates the association of high-level relation representations in the foundation model with various HO pairs within the image. Furthermore, we utilize a LLM (\emph{i.e.} GPT) for interaction interpretation, generating a richer linguistic understanding for complex HOIs. For open-category interaction recognition, our method supports either of two input types: interaction phrase or interpretive sentence. Our efficient architecture design and learning methods effectively unleash the potential of the VL foundation models and LLMs, allowing UniHOI to surpass all existing methods with a substantial margin, under both supervised and zero-shot settings. The code and pre-trained weights are available at: \url{https://github.com/Caoyichao/UniHOI}.
Re-mine, Learn and Reason: Exploring the Cross-modal Semantic Correlations for Language-guided HOI detection
Jul 25, 2023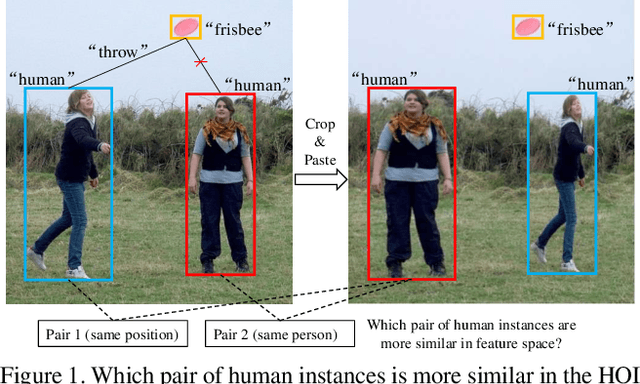

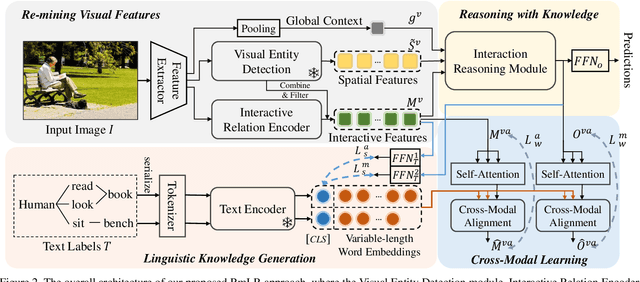

Human-Object Interaction (HOI) detection is a challenging computer vision task that requires visual models to address the complex interactive relationship between humans and objects and predict HOI triplets. Despite the challenges posed by the numerous interaction combinations, they also offer opportunities for multimodal learning of visual texts. In this paper, we present a systematic and unified framework (RmLR) that enhances HOI detection by incorporating structured text knowledge. Firstly, we qualitatively and quantitatively analyze the loss of interaction information in the two-stage HOI detector and propose a re-mining strategy to generate more comprehensive visual representation.Secondly, we design more fine-grained sentence- and word-level alignment and knowledge transfer strategies to effectively address the many-to-many matching problem between multiple interactions and multiple texts.These strategies alleviate the matching confusion problem that arises when multiple interactions occur simultaneously, thereby improving the effectiveness of the alignment process. Finally, HOI reasoning by visual features augmented with textual knowledge substantially improves the understanding of interactions. Experimental results illustrate the effectiveness of our approach, where state-of-the-art performance is achieved on public benchmarks. We further analyze the effects of different components of our approach to provide insights into its efficacy.
FastPillars: A Deployment-friendly Pillar-based 3D Detector
Feb 08, 2023



The deployment of 3D detectors strikes one of the major challenges in real-world self-driving scenarios. Existing BEV-based (i.e., Bird Eye View) detectors favor sparse convolution (known as SPConv) to speed up training and inference, which puts a hard barrier for deployment especially for on-device applications. In this paper, we tackle the problem of efficient 3D object detection from LiDAR point clouds with deployment in mind. To reduce computational burden, we propose a pillar-based 3D detector with high performance from an industry perspective, termed FastPillars. Compared with previous methods, we introduce a more effective Max-and-Attention pillar encoding (MAPE) module, and redesigning a powerful and lightweight backbone CRVNet imbued with Cross Stage Partial network (CSP) in a reparameterization style, forming a compact feature representation framework. Extensive experiments demonstrate that our FastPillars surpasses the state-of-the-art 3D detectors regarding both on-device speed and performance. Specifically, FastPillars can be effectively deployed through TensorRT, obtaining real-time performance (24FPS) on a single RTX3070Ti GPU with 64.6 mAP on the nuScenes test set. Our code is publicly available at: https://github.com/StiphyJay/FastPillars.
Pro-UIGAN: Progressive Face Hallucination from Occluded Thumbnails
Aug 08, 2021



In this paper, we study the task of hallucinating an authentic high-resolution (HR) face from an occluded thumbnail. We propose a multi-stage Progressive Upsampling and Inpainting Generative Adversarial Network, dubbed Pro-UIGAN, which exploits facial geometry priors to replenish and upsample (8*) the occluded and tiny faces (16*16 pixels). Pro-UIGAN iteratively (1) estimates facial geometry priors for low-resolution (LR) faces and (2) acquires non-occluded HR face images under the guidance of the estimated priors. Our multi-stage hallucination network super-resolves and inpaints occluded LR faces in a coarse-to-fine manner, thus reducing unwanted blurriness and artifacts significantly. Specifically, we design a novel cross-modal transformer module for facial priors estimation, in which an input face and its landmark features are formulated as queries and keys, respectively. Such a design encourages joint feature learning across the input facial and landmark features, and deep feature correspondences will be discovered by attention. Thus, facial appearance features and facial geometry priors are learned in a mutual promotion manner. Extensive experiments demonstrate that our Pro-UIGAN achieves visually pleasing HR faces, reaching superior performance in downstream tasks, i.e., face alignment, face parsing, face recognition and expression classification, compared with other state-of-the-art (SotA) methods.