 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePillarHist: A Quantization-aware Pillar Feature Encoder based on Height-aware Histogram
May 29, 2024



Real-time and high-performance 3D object detection plays a critical role in autonomous driving and robotics. Recent pillar-based 3D object detectors have gained significant attention due to their compact representation and low computational overhead, making them suitable for onboard deployment and quantization. However, existing pillar-based detectors still suffer from information loss along height dimension and large numerical distribution difference during pillar feature encoding (PFE), which severely limits their performance and quantization potential. To address above issue, we first unveil the importance of different input information during PFE and identify the height dimension as a key factor in enhancing 3D detection performance. Motivated by this observation, we propose a height-aware pillar feature encoder named PillarHist. Specifically, PillarHist statistics the discrete distribution of points at different heights within one pillar. This simple yet effective design greatly preserves the information along the height dimension while significantly reducing the computation overhead of the PFE. Meanwhile, PillarHist also constrains the arithmetic distribution of PFE input to a stable range, making it quantization-friendly. Notably, PillarHist operates exclusively within the PFE stage to enhance performance, enabling seamless integration into existing pillar-based methods without introducing complex operations. Extensive experiments show the effectiveness of PillarHist in terms of both efficiency and performance.
Rethinking Iterative Stereo Matching from Diffusion Bridge Model Perspective
Apr 13, 2024



Recently, iteration-based stereo matching has shown great potential. However, these models optimize the disparity map using RNN variants. The discrete optimization process poses a challenge of information loss, which restricts the level of detail that can be expressed in the generated disparity map. In order to address these issues, we propose a novel training approach that incorporates diffusion models into the iterative optimization process. We designed a Time-based Gated Recurrent Unit (T-GRU) to correlate temporal and disparity outputs. Unlike standard recurrent units, we employ Agent Attention to generate more expressive features. We also designed an attention-based context network to capture a large amount of contextual information. Experiments on several public benchmarks show that we have achieved competitive stereo matching performance. Our model ranks first in the Scene Flow dataset, achieving over a 7% improvement compared to competing methods, and requires only 8 iterations to achieve state-of-the-art results.
SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
Jul 05, 2023



One of the key problems in 3D object detection is to reduce the accuracy gap between methods based on LiDAR sensors and those based on monocular cameras. A recently proposed framework for monocular 3D detection based on Pseudo-Stereo has received considerable attention in the community. However, so far these two problems are discovered in existing practices, including (1) monocular depth estimation and Pseudo-Stereo detector must be trained separately, (2) Difficult to be compatible with different stereo detectors and (3) the overall calculation is large, which affects the reasoning speed. In this work, we propose an end-to-end, efficient pseudo-stereo 3D detection framework by introducing a Single-View Diffusion Model (SVDM) that uses a few iterations to gradually deliver right informative pixels to the left image. SVDM allows the entire pseudo-stereo 3D detection pipeline to be trained end-to-end and can benefit from the training of stereo detectors. Afterwards, we further explore the application of SVDM in depth-free stereo 3D detection, and the final framework is compatible with most stereo detectors. Among multiple benchmarks on the KITTI dataset, we achieve new state-of-the-art performance.
Stereo CenterNet based 3D Object Detection for Autonomous Driving
Mar 20, 2021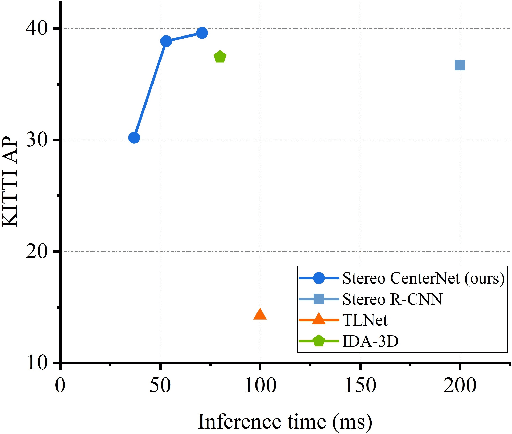
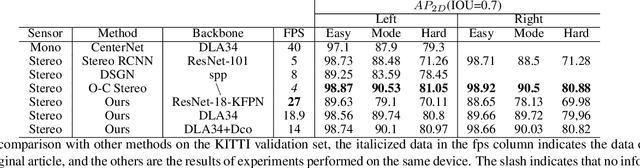
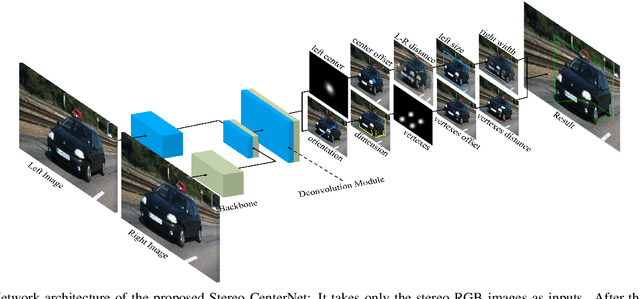
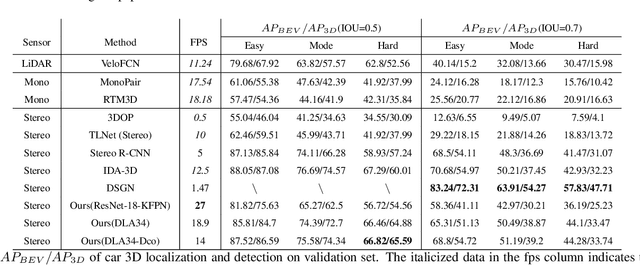
In recent years, 3D detection based on stereo cameras has made great progress, but most state-of-the-art methods use anchor-based 2D detection or depth estimation to solve this problem. However, the high computational cost makes these methods difficult to meet real-time performance. In this work, we propose a 3D object detection method using geometric information in stereo images, called Stereo CenterNet. Stereo CenterNet predicts the four semantic key points of the 3D bounding box of the object in space and uses 2D left right boxes, 3D dimension, orientation and key points to restore the bounding box of the object in the 3D space. Then, we use an improved photometric alignment module to further optimize the position of the 3D bounding box. Experiments conducted on the KITTI dataset show that our method achieves the best speed-accuracy trade-off compared with the state-of-the-art methods based on stereo geometry.