 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioMamba: Leveraging Spectro-Temporal Embedding in Bidirectional Mamba for Enhanced Biosignal Classification
Mar 14, 2025

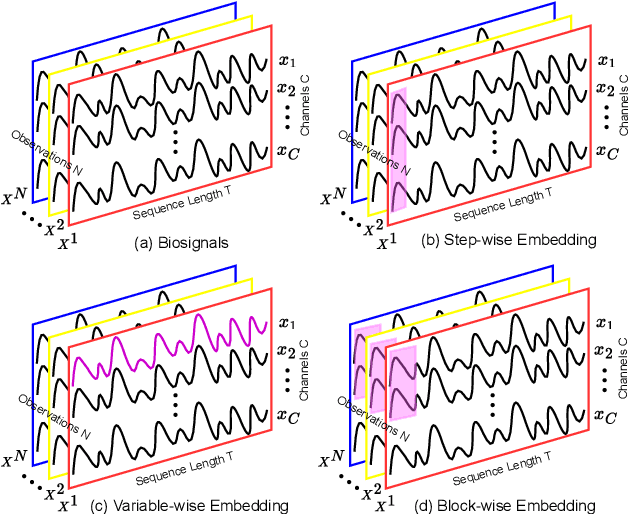

Biological signals, such as electroencephalograms (EEGs) and electrocardiograms (ECGs), play a pivotal role in numerous clinical practices, such as diagnosing brain and cardiac arrhythmic diseases. Existing methods for biosignal classification rely on Attention-based frameworks with dense Feed Forward layers, which lead to inefficient learning, high computational overhead, and suboptimal performance. In this work, we introduce BioMamba, a Spectro-Temporal Embedding strategy applied to the Bidirectional Mamba framework with Sparse Feed Forward layers to enable effective learning of biosignal sequences. By integrating these three key components, BioMamba effectively addresses the limitations of existing methods. Extensive experiments demonstrate that BioMamba significantly outperforms state-of-the-art methods with marked improvement in classification performance. The advantages of the proposed BioMamba include (1) Reliability: BioMamba consistently delivers robust results, confirmed across six evaluation metrics. (2) Efficiency: We assess both model and training efficiency, the BioMamba demonstrates computational effectiveness by reducing model size and resource consumption compared to existing approaches. (3) Generality: With the capacity to effectively classify a diverse set of tasks, BioMamba demonstrates adaptability and effectiveness across various domains and applications.
SDformer: Efficient End-to-End Transformer for Depth Completion
Sep 12, 2024



Depth completion aims to predict dense depth maps with sparse depth measurements from a depth sensor. Currently, Convolutional Neural Network (CNN) based models are the most popular methods applied to depth completion tasks. However, despite the excellent high-end performance, they suffer from a limited representation area. To overcome the drawbacks of CNNs, a more effective and powerful method has been presented: the Transformer, which is an adaptive self-attention setting sequence-to-sequence model. While the standard Transformer quadratically increases the computational cost from the key-query dot-product of input resolution which improperly employs depth completion tasks. In this work, we propose a different window-based Transformer architecture for depth completion tasks named Sparse-to-Dense Transformer (SDformer). The network consists of an input module for the depth map and RGB image features extraction and concatenation, a U-shaped encoder-decoder Transformer for extracting deep features, and a refinement module. Specifically, we first concatenate the depth map features with the RGB image features through the input model. Then, instead of calculating self-attention with the whole feature maps, we apply different window sizes to extract the long-range depth dependencies. Finally, we refine the predicted features from the input module and the U-shaped encoder-decoder Transformer module to get the enriching depth features and employ a convolution layer to obtain the dense depth map. In practice, the SDformer obtains state-of-the-art results against the CNN-based depth completion models with lower computing loads and parameters on the NYU Depth V2 and KITTI DC datasets.
FastPillars: A Deployment-friendly Pillar-based 3D Detector
Feb 08, 2023



The deployment of 3D detectors strikes one of the major challenges in real-world self-driving scenarios. Existing BEV-based (i.e., Bird Eye View) detectors favor sparse convolution (known as SPConv) to speed up training and inference, which puts a hard barrier for deployment especially for on-device applications. In this paper, we tackle the problem of efficient 3D object detection from LiDAR point clouds with deployment in mind. To reduce computational burden, we propose a pillar-based 3D detector with high performance from an industry perspective, termed FastPillars. Compared with previous methods, we introduce a more effective Max-and-Attention pillar encoding (MAPE) module, and redesigning a powerful and lightweight backbone CRVNet imbued with Cross Stage Partial network (CSP) in a reparameterization style, forming a compact feature representation framework. Extensive experiments demonstrate that our FastPillars surpasses the state-of-the-art 3D detectors regarding both on-device speed and performance. Specifically, FastPillars can be effectively deployed through TensorRT, obtaining real-time performance (24FPS) on a single RTX3070Ti GPU with 64.6 mAP on the nuScenes test set. Our code is publicly available at: https://github.com/StiphyJay/FastPillars.