 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Any Human-Object Interaction Relationship: Universal HOI Detector with Spatial Prompt Learning on Foundation Models
Nov 07, 2023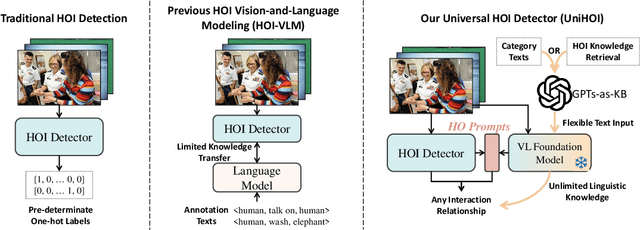
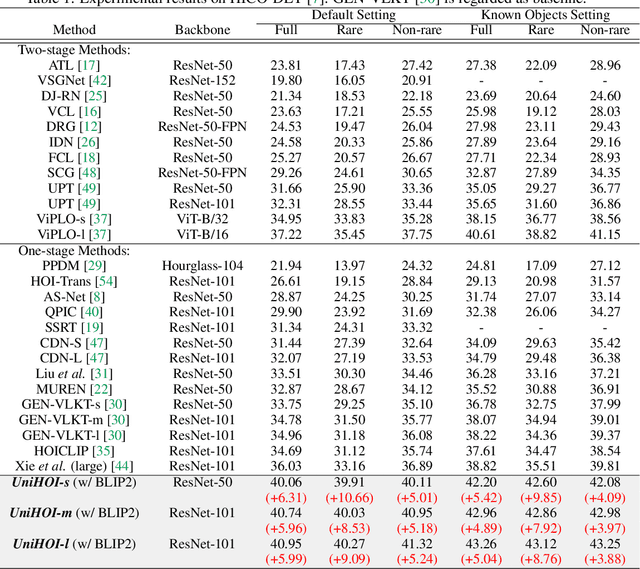
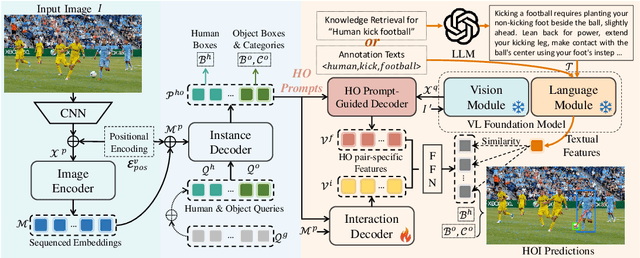
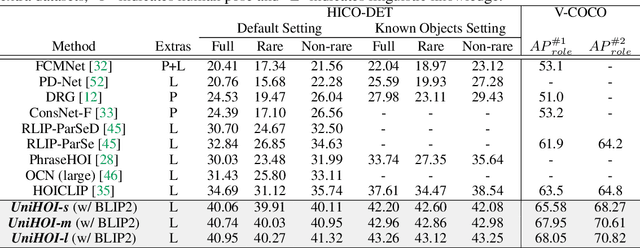
Human-object interaction (HOI) detection aims to comprehend the intricate relationships between humans and objects, predicting $<human, action, object>$ triplets, and serving as the foundation for numerous computer vision tasks. The complexity and diversity of human-object interactions in the real world, however, pose significant challenges for both annotation and recognition, particularly in recognizing interactions within an open world context. This study explores the universal interaction recognition in an open-world setting through the use of Vision-Language (VL) foundation models and large language models (LLMs). The proposed method is dubbed as \emph{\textbf{UniHOI}}. We conduct a deep analysis of the three hierarchical features inherent in visual HOI detectors and propose a method for high-level relation extraction aimed at VL foundation models, which we call HO prompt-based learning. Our design includes an HO Prompt-guided Decoder (HOPD), facilitates the association of high-level relation representations in the foundation model with various HO pairs within the image. Furthermore, we utilize a LLM (\emph{i.e.} GPT) for interaction interpretation, generating a richer linguistic understanding for complex HOIs. For open-category interaction recognition, our method supports either of two input types: interaction phrase or interpretive sentence. Our efficient architecture design and learning methods effectively unleash the potential of the VL foundation models and LLMs, allowing UniHOI to surpass all existing methods with a substantial margin, under both supervised and zero-shot settings. The code and pre-trained weights are available at: \url{https://github.com/Caoyichao/UniHOI}.
Re-mine, Learn and Reason: Exploring the Cross-modal Semantic Correlations for Language-guided HOI detection
Jul 25, 2023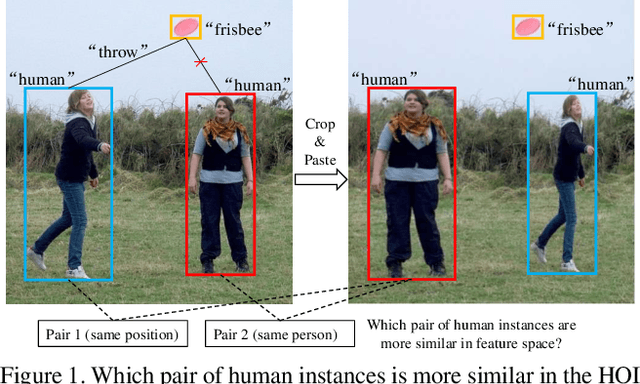

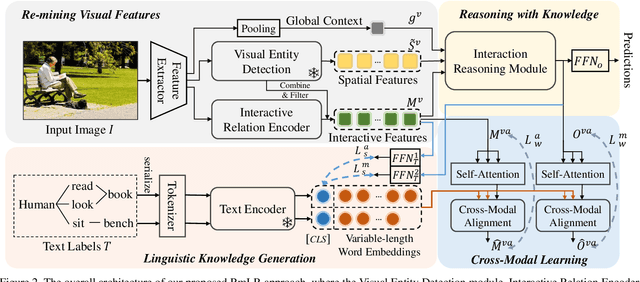

Human-Object Interaction (HOI) detection is a challenging computer vision task that requires visual models to address the complex interactive relationship between humans and objects and predict HOI triplets. Despite the challenges posed by the numerous interaction combinations, they also offer opportunities for multimodal learning of visual texts. In this paper, we present a systematic and unified framework (RmLR) that enhances HOI detection by incorporating structured text knowledge. Firstly, we qualitatively and quantitatively analyze the loss of interaction information in the two-stage HOI detector and propose a re-mining strategy to generate more comprehensive visual representation.Secondly, we design more fine-grained sentence- and word-level alignment and knowledge transfer strategies to effectively address the many-to-many matching problem between multiple interactions and multiple texts.These strategies alleviate the matching confusion problem that arises when multiple interactions occur simultaneously, thereby improving the effectiveness of the alignment process. Finally, HOI reasoning by visual features augmented with textual knowledge substantially improves the understanding of interactions. Experimental results illustrate the effectiveness of our approach, where state-of-the-art performance is achieved on public benchmarks. We further analyze the effects of different components of our approach to provide insights into its efficacy.
STCNet: Spatio-Temporal Cross Network for Industrial Smoke Detection
Nov 10, 2020
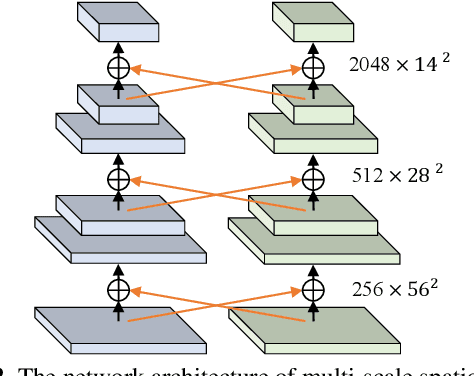
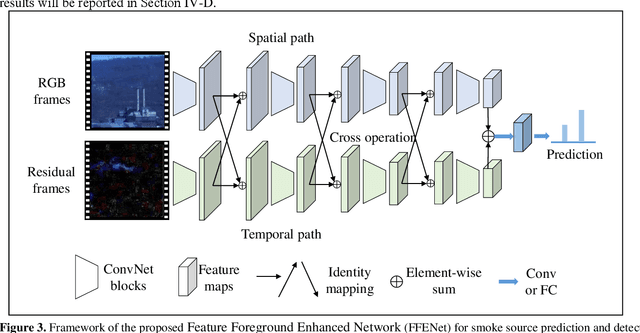
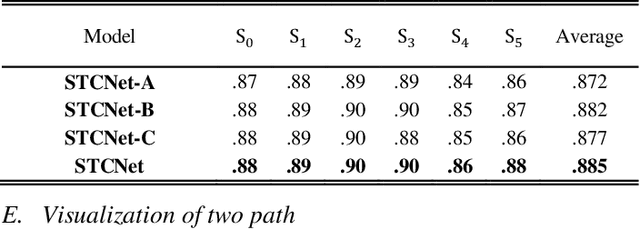
Industrial smoke emissions present a serious threat to natural ecosystems and human health. Prior works have shown that using computer vision techniques to identify smoke is a low cost and convenient method. However, industrial smoke detection is a challenging task because industrial emission particles are often decay rapidly outside the stacks or facilities and steam is very similar to smoke. To overcome these problems, a novel Spatio-Temporal Cross Network (STCNet) is proposed to recognize industrial smoke emissions. The proposed STCNet involves a spatial pathway to extract texture features and a temporal pathway to capture smoke motion information. We assume that spatial and temporal pathway could guide each other. For example, the spatial path can easily recognize the obvious interference such as trees and buildings, and the temporal path can highlight the obscure traces of smoke movement. If the two pathways could guide each other, it will be helpful for the smoke detection performance. In addition, we design an efficient and concise spatio-temporal dual pyramid architecture to ensure better fusion of multi-scale spatiotemporal information. Finally, extensive experiments on public dataset show that our STCNet achieves clear improvements on the challenging RISE industrial smoke detection dataset against the best competitors by 6.2%. The code will be available at: https://github.com/Caoyichao/STCNet.