 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-PTQ: Post-Training Quantization for Point Cloud 3D Object Detection
Jan 29, 2024Due to highly constrained computing power and memory, deploying 3D lidar-based detectors on edge devices equipped in autonomous vehicles and robots poses a crucial challenge. Being a convenient and straightforward model compression approach, Post-Training Quantization (PTQ) has been widely adopted in 2D vision tasks. However, applying it directly to 3D lidar-based tasks inevitably leads to performance degradation. As a remedy, we propose an effective PTQ method called LiDAR-PTQ, which is particularly curated for 3D lidar detection (both SPConv-based and SPConv-free). Our LiDAR-PTQ features three main components, \textbf{(1)} a sparsity-based calibration method to determine the initialization of quantization parameters, \textbf{(2)} a Task-guided Global Positive Loss (TGPL) to reduce the disparity between the final predictions before and after quantization, \textbf{(3)} an adaptive rounding-to-nearest operation to minimize the layerwise reconstruction error. Extensive experiments demonstrate that our LiDAR-PTQ can achieve state-of-the-art quantization performance when applied to CenterPoint (both Pillar-based and Voxel-based). To our knowledge, for the very first time in lidar-based 3D detection tasks, the PTQ INT8 model's accuracy is almost the same as the FP32 model while enjoying $3\times$ inference speedup. Moreover, our LiDAR-PTQ is cost-effective being $30\times$ faster than the quantization-aware training method. Code will be released at \url{https://github.com/StiphyJay/LiDAR-PTQ}.
SUBP: Soft Uniform Block Pruning for 1xN Sparse CNNs Multithreading Acceleration
Oct 10, 2023



The study of sparsity in Convolutional Neural Networks (CNNs) has become widespread to compress and accelerate models in environments with limited resources. By constraining N consecutive weights along the output channel to be group-wise non-zero, the recent network with 1$\times$N sparsity has received tremendous popularity for its three outstanding advantages: 1) A large amount of storage space saving by a \emph{Block Sparse Row} matrix. 2) Excellent performance at a high sparsity. 3) Significant speedups on CPUs with Advanced Vector Extensions. Recent work requires selecting and fine-tuning 1$\times$N sparse weights based on dense pre-trained weights, leading to the problems such as expensive training cost and memory access, sub-optimal model quality, as well as unbalanced workload across threads (different sparsity across output channels). To overcome them, this paper proposes a novel \emph{\textbf{S}oft \textbf{U}niform \textbf{B}lock \textbf{P}runing} (SUBP) approach to train a uniform 1$\times$N sparse structured network from scratch. Specifically, our approach tends to repeatedly allow pruned blocks to regrow to the network based on block angular redundancy and importance sampling in a uniform manner throughout the training process. It not only makes the model less dependent on pre-training, reduces the model redundancy and the risk of pruning the important blocks permanently but also achieves balanced workload. Empirically, on ImageNet, comprehensive experiments across various CNN architectures show that our SUBP consistently outperforms existing 1$\times$N and structured sparsity methods based on pre-trained models or training from scratch. Source codes and models are available at \url{https://github.com/JingyangXiang/SUBP}.
Unified Data-Free Compression: Pruning and Quantization without Fine-Tuning
Aug 14, 2023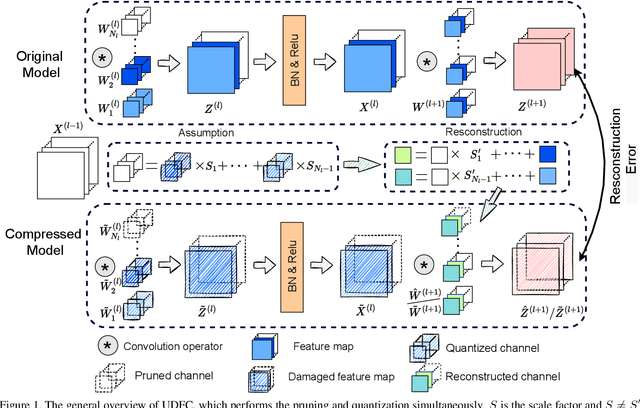
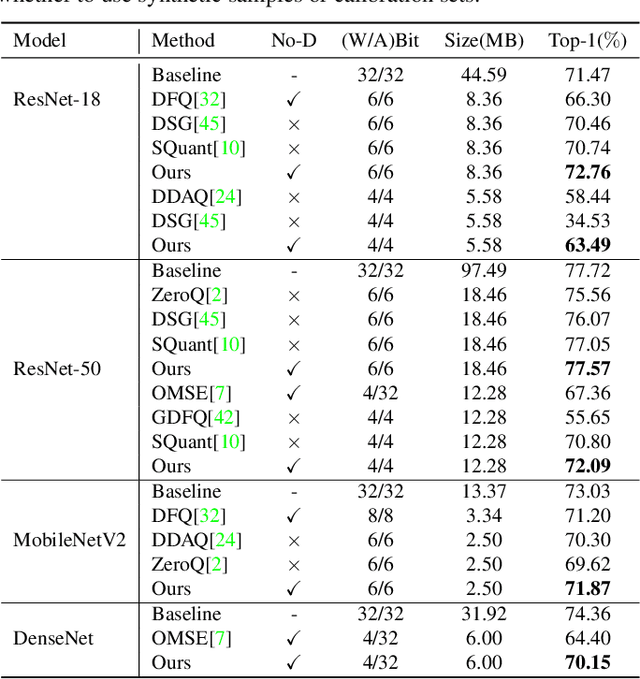
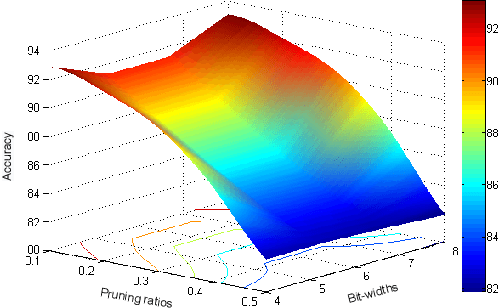
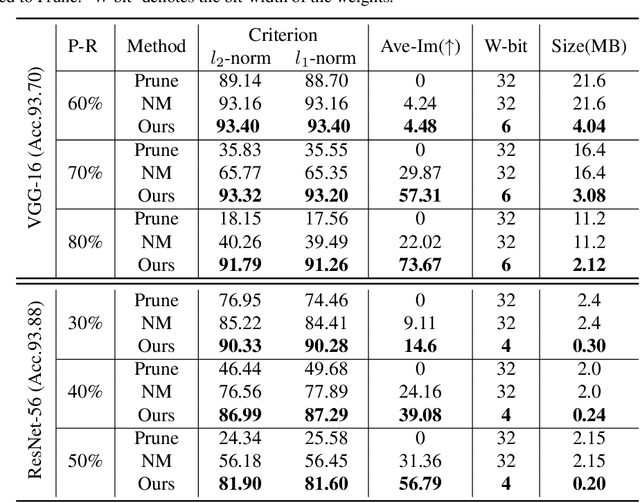
Structured pruning and quantization are promising approaches for reducing the inference time and memory footprint of neural networks. However, most existing methods require the original training dataset to fine-tune the model. This not only brings heavy resource consumption but also is not possible for applications with sensitive or proprietary data due to privacy and security concerns. Therefore, a few data-free methods are proposed to address this problem, but they perform data-free pruning and quantization separately, which does not explore the complementarity of pruning and quantization. In this paper, we propose a novel framework named Unified Data-Free Compression(UDFC), which performs pruning and quantization simultaneously without any data and fine-tuning process. Specifically, UDFC starts with the assumption that the partial information of a damaged(e.g., pruned or quantized) channel can be preserved by a linear combination of other channels, and then derives the reconstruction form from the assumption to restore the information loss due to compression. Finally, we formulate the reconstruction error between the original network and its compressed network, and theoretically deduce the closed-form solution. We evaluate the UDFC on the large-scale image classification task and obtain significant improvements over various network architectures and compression methods. For example, we achieve a 20.54% accuracy improvement on ImageNet dataset compared to SOTA method with 30% pruning ratio and 6-bit quantization on ResNet-34.
Data-Free Quantization via Mixed-Precision Compensation without Fine-Tuning
Jul 02, 2023Neural network quantization is a very promising solution in the field of model compression, but its resulting accuracy highly depends on a training/fine-tuning process and requires the original data. This not only brings heavy computation and time costs but also is not conducive to privacy and sensitive information protection. Therefore, a few recent works are starting to focus on data-free quantization. However, data-free quantization does not perform well while dealing with ultra-low precision quantization. Although researchers utilize generative methods of synthetic data to address this problem partially, data synthesis needs to take a lot of computation and time. In this paper, we propose a data-free mixed-precision compensation (DF-MPC) method to recover the performance of an ultra-low precision quantized model without any data and fine-tuning process. By assuming the quantized error caused by a low-precision quantized layer can be restored via the reconstruction of a high-precision quantized layer, we mathematically formulate the reconstruction loss between the pre-trained full-precision model and its layer-wise mixed-precision quantized model. Based on our formulation, we theoretically deduce the closed-form solution by minimizing the reconstruction loss of the feature maps. Since DF-MPC does not require any original/synthetic data, it is a more efficient method to approximate the full-precision model. Experimentally, our DF-MPC is able to achieve higher accuracy for an ultra-low precision quantized model compared to the recent methods without any data and fine-tuning process.
* This paper has been accepted for publication in the Pattern Recognition
Learning Global-aware Kernel for Image Harmonization
May 19, 2023Image harmonization aims to solve the visual inconsistency problem in composited images by adaptively adjusting the foreground pixels with the background as references. Existing methods employ local color transformation or region matching between foreground and background, which neglects powerful proximity prior and independently distinguishes fore-/back-ground as a whole part for harmonization. As a result, they still show a limited performance across varied foreground objects and scenes. To address this issue, we propose a novel Global-aware Kernel Network (GKNet) to harmonize local regions with comprehensive consideration of long-distance background references. Specifically, GKNet includes two parts, \ie, harmony kernel prediction and harmony kernel modulation branches. The former includes a Long-distance Reference Extractor (LRE) to obtain long-distance context and Kernel Prediction Blocks (KPB) to predict multi-level harmony kernels by fusing global information with local features. To achieve this goal, a novel Selective Correlation Fusion (SCF) module is proposed to better select relevant long-distance background references for local harmonization. The latter employs the predicted kernels to harmonize foreground regions with both local and global awareness. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods, \eg, achieving 39.53dB PSNR that surpasses the best counterpart by +0.78dB $\uparrow$; decreasing fMSE/MSE by 11.5\%$\downarrow$/6.7\%$\downarrow$ compared with the SoTA method. Code will be available at \href{https://github.com/XintianShen/GKNet}{here}.