 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCOVERSE: Efficient Robot Simulation in Complex High-Fidelity Environments
Jul 29, 2025We present the first unified, modular, open-source 3DGS-based simulation framework for Real2Sim2Real robot learning. It features a holistic Real2Sim pipeline that synthesizes hyper-realistic geometry and appearance of complex real-world scenarios, paving the way for analyzing and bridging the Sim2Real gap. Powered by Gaussian Splatting and MuJoCo, Discoverse enables massively parallel simulation of multiple sensor modalities and accurate physics, with inclusive supports for existing 3D assets, robot models, and ROS plugins, empowering large-scale robot learning and complex robotic benchmarks. Through extensive experiments on imitation learning, Discoverse demonstrates state-of-the-art zero-shot Sim2Real transfer performance compared to existing simulators. For code and demos: https://air-discoverse.github.io/.
Wavelet Policy: Imitation Policy Learning in Frequency Domain with Wavelet Transforms
Apr 07, 2025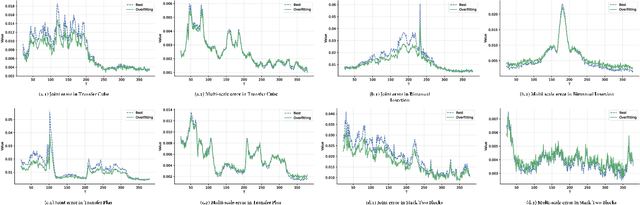



Recent imitation learning policies, often framed as time series prediction tasks, directly map robotic observations-such as high-dimensional visual data and proprioception-into the action space. While time series prediction primarily relies on spatial domain modeling, the underutilization of frequency domain analysis in robotic manipulation trajectory prediction may lead to neglecting the inherent temporal information embedded within action sequences. To address this, we reframe imitation learning policies through the lens of the frequency domain and introduce the Wavelet Policy. This novel approach employs wavelet transforms (WT) for feature preprocessing and extracts multi-scale features from the frequency domain using the SE2MD (Single Encoder to Multiple Decoder) architecture. Furthermore, to enhance feature mapping in the frequency domain and increase model capacity, we introduce a Learnable Frequency-Domain Filter (LFDF) after each frequency decoder, improving adaptability under different visual conditions. Our results show that the Wavelet Policy outperforms state-of-the-art (SOTA) end-to-end methods by over 10% on four challenging robotic arm tasks, while maintaining a comparable parameter count. In long-range settings, its performance declines more slowly as task volume increases. The code will be publicly available.
Locate n' Rotate: Two-stage Openable Part Detection with Foundation Model Priors
Dec 17, 2024Detecting the openable parts of articulated objects is crucial for downstream applications in intelligent robotics, such as pulling a drawer. This task poses a multitasking challenge due to the necessity of understanding object categories and motion. Most existing methods are either category-specific or trained on specific datasets, lacking generalization to unseen environments and objects. In this paper, we propose a Transformer-based Openable Part Detection (OPD) framework named Multi-feature Openable Part Detection (MOPD) that incorporates perceptual grouping and geometric priors, outperforming previous methods in performance. In the first stage of the framework, we introduce a perceptual grouping feature model that provides perceptual grouping feature priors for openable part detection, enhancing detection results through a cross-attention mechanism. In the second stage, a geometric understanding feature model offers geometric feature priors for predicting motion parameters. Compared to existing methods, our proposed approach shows better performance in both detection and motion parameter prediction. Codes and models are publicly available at https://github.com/lisiqi-zju/MOPD
Learning Multi-view Anomaly Detection
Jul 16, 2024



This study explores the recently proposed challenging multi-view Anomaly Detection (AD) task. Single-view tasks would encounter blind spots from other perspectives, resulting in inaccuracies in sample-level prediction. Therefore, we introduce the \textbf{M}ulti-\textbf{V}iew \textbf{A}nomaly \textbf{D}etection (\textbf{MVAD}) framework, which learns and integrates features from multi-views. Specifically, we proposed a \textbf{M}ulti-\textbf{V}iew \textbf{A}daptive \textbf{S}election (\textbf{MVAS}) algorithm for feature learning and fusion across multiple views. The feature maps are divided into neighbourhood attention windows to calculate a semantic correlation matrix between single-view windows and all other views, which is a conducted attention mechanism for each single-view window and the top-K most correlated multi-view windows. Adjusting the window sizes and top-K can minimise the computational complexity to linear. Extensive experiments on the Real-IAD dataset for cross-setting (multi/single-class) validate the effectiveness of our approach, achieving state-of-the-art performance among sample \textbf{4.1\%}$\uparrow$/ image \textbf{5.6\%}$\uparrow$/pixel \textbf{6.7\%}$\uparrow$ levels with a total of ten metrics with only \textbf{18M} parameters and fewer GPU memory and training time.
Learning Feature Inversion for Multi-class Anomaly Detection under General-purpose COCO-AD Benchmark
Apr 16, 2024



Anomaly detection (AD) is often focused on detecting anomaly areas for industrial quality inspection and medical lesion examination. However, due to the specific scenario targets, the data scale for AD is relatively small, and evaluation metrics are still deficient compared to classic vision tasks, such as object detection and semantic segmentation. To fill these gaps, this work first constructs a large-scale and general-purpose COCO-AD dataset by extending COCO to the AD field. This enables fair evaluation and sustainable development for different methods on this challenging benchmark. Moreover, current metrics such as AU-ROC have nearly reached saturation on simple datasets, which prevents a comprehensive evaluation of different methods. Inspired by the metrics in the segmentation field, we further propose several more practical threshold-dependent AD-specific metrics, ie, m$F_1$$^{.2}_{.8}$, mAcc$^{.2}_{.8}$, mIoU$^{.2}_{.8}$, and mIoU-max. Motivated by GAN inversion's high-quality reconstruction capability, we propose a simple but more powerful InvAD framework to achieve high-quality feature reconstruction. Our method improves the effectiveness of reconstruction-based methods on popular MVTec AD, VisA, and our newly proposed COCO-AD datasets under a multi-class unsupervised setting, where only a single detection model is trained to detect anomalies from different classes. Extensive ablation experiments have demonstrated the effectiveness of each component of our InvAD. Full codes and models are available at https://github.com/zhangzjn/ader.
MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
Apr 14, 2024



Recent advancements in anomaly detection have seen the efficacy of CNN- and transformer-based approaches. However, CNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Mamba-based models, with their superior long-range modeling and linear efficiency, have garnered substantial attention. This study pioneers the application of Mamba to multi-class unsupervised anomaly detection, presenting MambaAD, which consists of a pre-trained encoder and a Mamba decoder featuring (Locality-Enhanced State Space) LSS modules at multi-scales. The proposed LSS module, integrating parallel cascaded (Hybrid State Space) HSS blocks and multi-kernel convolutions operations, effectively captures both long-range and local information. The HSS block, utilizing (Hybrid Scanning) HS encoders, encodes feature maps into five scanning methods and eight directions, thereby strengthening global connections through the (State Space Model) SSM. The use of Hilbert scanning and eight directions significantly improves feature sequence modeling. Comprehensive experiments on six diverse anomaly detection datasets and seven metrics demonstrate state-of-the-art performance, substantiating the method's effectiveness.
Dual-path Frequency Discriminators for Few-shot Anomaly Detection
Mar 11, 2024



Few-shot anomaly detection (FSAD) is essential in industrial manufacturing. However, existing FSAD methods struggle to effectively leverage a limited number of normal samples, and they may fail to detect and locate inconspicuous anomalies in the spatial domain. We further discover that these subtle anomalies would be more noticeable in the frequency domain. In this paper, we propose a Dual-Path Frequency Discriminators (DFD) network from a frequency perspective to tackle these issues. Specifically, we generate anomalies at both image-level and feature-level. Differential frequency components are extracted by the multi-frequency information construction module and supplied into the fine-grained feature construction module to provide adapted features. We consider anomaly detection as a discriminative classification problem, wherefore the dual-path feature discrimination module is employed to detect and locate the image-level and feature-level anomalies in the feature space. The discriminators aim to learn a joint representation of anomalous features and normal features in the latent space. Extensive experiments conducted on MVTec AD and VisA benchmarks demonstrate that our DFD surpasses current state-of-the-art methods. Source code will be available.
CLIP-AD: A Language-Guided Staged Dual-Path Model for Zero-shot Anomaly Detection
Nov 01, 2023



This paper considers zero-shot Anomaly Detection (AD), a valuable yet under-studied task, which performs AD without any reference images of the test objects. Specifically, we employ a language-guided strategy and propose a simple-yet-effective architecture CLIP-AD, leveraging the superior zero-shot classification capabilities of the large vision-language model CLIP. A natural idea for anomaly segmentation is to directly calculate the similarity between text/image features, but we observe opposite predictions and irrelevant highlights in the results. Inspired by the phenomena, we introduce a Staged Dual-Path model (SDP) that effectively uses features from various levels and applies architecture and feature surgery to address these issues. Furthermore, delving beyond surface phenomena, we identify the problem arising from misalignment of text/image features in the joint embedding space. Thus, we introduce a fine-tuning strategy by adding linear layers and construct an extended model SDP+, further enhancing the performance. Abundant experiments demonstrate the effectiveness of our approach, e.g., on VisA, SDP outperforms SOTA by +1.0/+1.2 in classification/segmentation F1 scores, while SDP+ achieves +1.9/+11.7 improvements.
Data-Free Quantization via Mixed-Precision Compensation without Fine-Tuning
Jul 02, 2023Neural network quantization is a very promising solution in the field of model compression, but its resulting accuracy highly depends on a training/fine-tuning process and requires the original data. This not only brings heavy computation and time costs but also is not conducive to privacy and sensitive information protection. Therefore, a few recent works are starting to focus on data-free quantization. However, data-free quantization does not perform well while dealing with ultra-low precision quantization. Although researchers utilize generative methods of synthetic data to address this problem partially, data synthesis needs to take a lot of computation and time. In this paper, we propose a data-free mixed-precision compensation (DF-MPC) method to recover the performance of an ultra-low precision quantized model without any data and fine-tuning process. By assuming the quantized error caused by a low-precision quantized layer can be restored via the reconstruction of a high-precision quantized layer, we mathematically formulate the reconstruction loss between the pre-trained full-precision model and its layer-wise mixed-precision quantized model. Based on our formulation, we theoretically deduce the closed-form solution by minimizing the reconstruction loss of the feature maps. Since DF-MPC does not require any original/synthetic data, it is a more efficient method to approximate the full-precision model. Experimentally, our DF-MPC is able to achieve higher accuracy for an ultra-low precision quantized model compared to the recent methods without any data and fine-tuning process.
* This paper has been accepted for publication in the Pattern Recognition
ViG-UNet: Vision Graph Neural Networks for Medical Image Segmentation
Jun 08, 2023
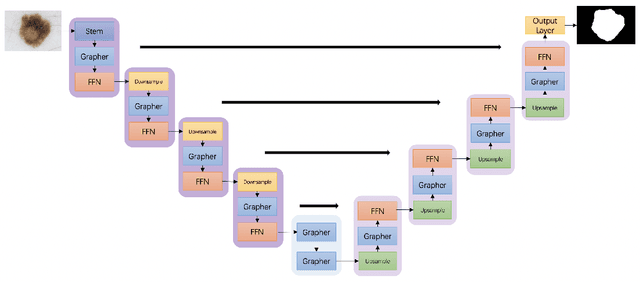

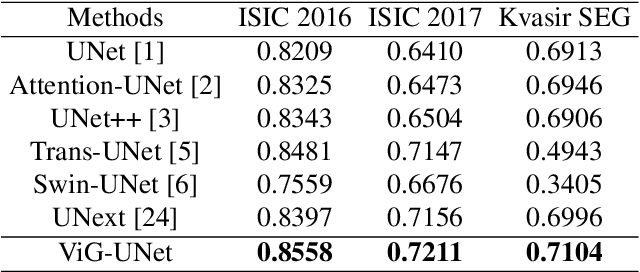
Deep neural networks have been widely used in medical image analysis and medical image segmentation is one of the most important tasks. U-shaped neural networks with encoder-decoder are prevailing and have succeeded greatly in various segmentation tasks. While CNNs treat an image as a grid of pixels in Euclidean space and Transformers recognize an image as a sequence of patches, graph-based representation is more generalized and can construct connections for each part of an image. In this paper, we propose a novel ViG-UNet, a graph neural network-based U-shaped architecture with the encoder, the decoder, the bottleneck, and skip connections. The downsampling and upsampling modules are also carefully designed. The experimental results on ISIC 2016, ISIC 2017 and Kvasir-SEG datasets demonstrate that our proposed architecture outperforms most existing classic and state-of-the-art U-shaped networks.