 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-AD: A Language-Guided Staged Dual-Path Model for Zero-shot Anomaly Detection
Nov 01, 2023



This paper considers zero-shot Anomaly Detection (AD), a valuable yet under-studied task, which performs AD without any reference images of the test objects. Specifically, we employ a language-guided strategy and propose a simple-yet-effective architecture CLIP-AD, leveraging the superior zero-shot classification capabilities of the large vision-language model CLIP. A natural idea for anomaly segmentation is to directly calculate the similarity between text/image features, but we observe opposite predictions and irrelevant highlights in the results. Inspired by the phenomena, we introduce a Staged Dual-Path model (SDP) that effectively uses features from various levels and applies architecture and feature surgery to address these issues. Furthermore, delving beyond surface phenomena, we identify the problem arising from misalignment of text/image features in the joint embedding space. Thus, we introduce a fine-tuning strategy by adding linear layers and construct an extended model SDP+, further enhancing the performance. Abundant experiments demonstrate the effectiveness of our approach, e.g., on VisA, SDP outperforms SOTA by +1.0/+1.2 in classification/segmentation F1 scores, while SDP+ achieves +1.9/+11.7 improvements.
MixTeacher: Mining Promising Labels with Mixed Scale Teacher for Semi-Supervised Object Detection
Mar 16, 2023Scale variation across object instances remains a key challenge in object detection task. Despite the remarkable progress made by modern detection models, this challenge is particularly evident in the semi-supervised case. While existing semi-supervised object detection methods rely on strict conditions to filter high-quality pseudo labels from network predictions, we observe that objects with extreme scale tend to have low confidence, resulting in a lack of positive supervision for these objects. In this paper, we propose a novel framework that addresses the scale variation problem by introducing a mixed scale teacher to improve pseudo label generation and scale-invariant learning. Additionally, we propose mining pseudo labels using score promotion of predictions across scales, which benefits from better predictions from mixed scale features. Our extensive experiments on MS COCO and PASCAL VOC benchmarks under various semi-supervised settings demonstrate that our method achieves new state-of-the-art performance. The code and models are available at \url{https://github.com/lliuz/MixTeacher}.
Calibrated Teacher for Sparsely Annotated Object Detection
Mar 14, 2023
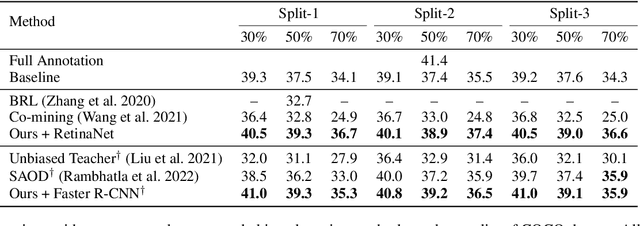
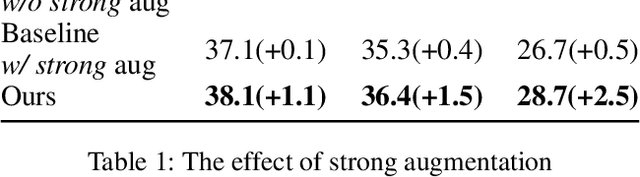
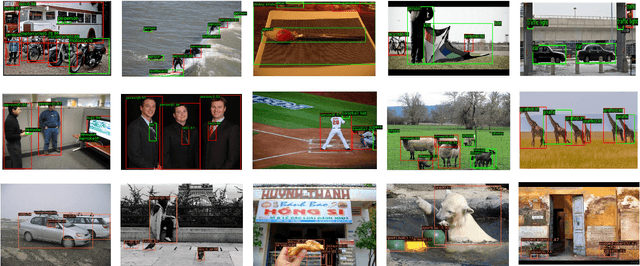
Fully supervised object detection requires training images in which all instances are annotated. This is actually impractical due to the high labor and time costs and the unavoidable missing annotations. As a result, the incomplete annotation in each image could provide misleading supervision and harm the training. Recent works on sparsely annotated object detection alleviate this problem by generating pseudo labels for the missing annotations. Such a mechanism is sensitive to the threshold of the pseudo label score. However, the effective threshold is different in different training stages and among different object detectors. Therefore, the current methods with fixed thresholds have sub-optimal performance, and are difficult to be applied to other detectors. In order to resolve this obstacle, we propose a Calibrated Teacher, of which the confidence estimation of the prediction is well calibrated to match its real precision. In this way, different detectors in different training stages would share a similar distribution of the output confidence, so that multiple detectors could share the same fixed threshold and achieve better performance. Furthermore, we present a simple but effective Focal IoU Weight (FIoU) for the classification loss. FIoU aims at reducing the loss weight of false negative samples caused by the missing annotation, and thus works as the complement of the teacher-student paradigm. Extensive experiments show that our methods set new state-of-the-art under all different sparse settings in COCO. Code will be available at https://github.com/Whileherham/CalibratedTeacher.
Iterative Few-shot Semantic Segmentation from Image Label Text
Mar 10, 2023Few-shot semantic segmentation aims to learn to segment unseen class objects with the guidance of only a few support images. Most previous methods rely on the pixel-level label of support images. In this paper, we focus on a more challenging setting, in which only the image-level labels are available. We propose a general framework to firstly generate coarse masks with the help of the powerful vision-language model CLIP, and then iteratively and mutually refine the mask predictions of support and query images. Extensive experiments on PASCAL-5i and COCO-20i datasets demonstrate that our method not only outperforms the state-of-the-art weakly supervised approaches by a significant margin, but also achieves comparable or better results to recent supervised methods. Moreover, our method owns an excellent generalization ability for the images in the wild and uncommon classes. Code will be available at https://github.com/Whileherham/IMR-HSNet.