 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamingClaw Technical Report
Mar 23, 2026Applications such as embodied intelligence rely on a real-time perception-decision-action closed loop, posing stringent challenges for streaming video understanding. However, current agents suffer from fragmented capabilities, such as supporting only offline video understanding, lacking long-term multimodal memory mechanisms, or struggling to achieve real-time reasoning and proactive interaction under streaming inputs. These shortcomings have become a key bottleneck for preventing them from sustaining perception, making real-time decisions, and executing actions in real-world environments. To alleviate these issues, we propose StreamingClaw, a unified agent framework for streaming video understanding and embodied intelligence. It is also an OpenClaw-compatible framework that supports real-time, multimodal streaming interaction. StreamingClaw integrates five core capabilities: (1) It supports real-time streaming reasoning. (2) It supports reasoning about future events and proactive interaction under the online evolution of interaction objectives. (3) It supports multimodal long-term storage, hierarchical evolution, and efficient retrieval of shared memory across multiple agents. (4) It supports a closed-loop of perception-decision-action. In addition to conventional tools and skills, it also provides streaming tools and action-centric skills tailored for real-world physical environments. (5) It is compatible with the OpenClaw framework, allowing it to fully leverage the resources and support of the open-source community. With these designs, StreamingClaw integrates online real-time reasoning, multimodal long-term memory, and proactive interaction within a unified framework. Moreover, by translating decisions into executable actions, it enables direct control of the physical world, supporting practical deployment of embodied interaction.
Evaluating the Search Agent in a Parallel World
Mar 05, 2026Integrating web search tools has significantly extended the capability of LLMs to address open-world, real-time, and long-tail problems. However, evaluating these Search Agents presents formidable challenges. First, constructing high-quality deep search benchmarks is prohibitively expensive, while unverified synthetic data often suffers from unreliable sources. Second, static benchmarks face dynamic obsolescence: as internet information evolves, complex queries requiring deep research often degrade into simple retrieval tasks due to increased popularity, and ground truths become outdated due to temporal shifts. Third, attribution ambiguity confounds evaluation, as an agent's performance is often dominated by its parametric memory rather than its actual search and reasoning capabilities. Finally, reliance on specific commercial search engines introduces variability that hampers reproducibility. To address these issues, we propose a novel framework, Mind-ParaWorld, for evaluating Search Agents in a Parallel World. Specifically, MPW samples real-world entity names to synthesize future scenarios and questions situated beyond the model's knowledge cutoff. A ParaWorld Law Model then constructs a set of indivisible Atomic Facts and a unique ground-truth for each question. During evaluation, instead of retrieving real-world results, the agent interacts with a ParaWorld Engine Model that dynamically generates SERPs grounded in these inviolable Atomic Facts. We release MPW-Bench, an interactive benchmark spanning 19 domains with 1,608 instances. Experiments across three evaluation settings show that, while search agents are strong at evidence synthesis given complete information, their performance is limited not only by evidence collection and coverage in unfamiliar search environments, but also by unreliable evidence sufficiency judgment and when-to-stop decisions-bottlenecks.
Evolving from Tool User to Creator via Training-Free Experience Reuse in Multimodal Reasoning
Feb 02, 2026Existing Tool-Integrated Reasoning (TIR) models have effectively extended the question-answering capabilities of LLMs by incorporating external tools. However, real-world scenarios present numerous open-ended problems where fixed tools often fail to meet task requirements. Furthermore, the lack of self-optimization mechanisms means that erroneous tool outputs can mislead the LLM's responses. Additionally, the construction of existing tools entails significant manual effort, which consequently constrains their applicability. Recognizing that the reasoning traces of LLMs encapsulate implicit problem-solving capabilities, we propose UCT, a novel training-free framework that transforms agents from tool users to tool creators. This approach harvests reasoning experiences and distills them into reusable assets. This method transforms the agent from a mere tool user into a tool creator, enabling adaptive tool creation and self-updating during the inference process. We also introduce a memory consolidation mechanism to maintain the tool library, ensuring high reusability of retained experiential memory for subsequent reasoning tasks. This novel automated tool construction paradigm continuously improves tool quality during reasoning, allowing the overall agent system to progress without additional training. Extensive experiments demonstrate that our method serves as a novel paradigm for enhancing the capabilities of TIR models. In particular, the significant performance gains achieved +20.86%$\uparrow$ and +23.04%$\uparrow$ on benchmarks across multi-domain mathematical and scientific reasoning tasks validate the self-evolving capability of the agent.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
COPO: Consistency-Aware Policy Optimization
Aug 06, 2025Reinforcement learning has significantly enhanced the reasoning capabilities of Large Language Models (LLMs) in complex problem-solving tasks. Recently, the introduction of DeepSeek R1 has inspired a surge of interest in leveraging rule-based rewards as a low-cost alternative for computing advantage functions and guiding policy optimization. However, a common challenge observed across many replication and extension efforts is that when multiple sampled responses under a single prompt converge to identical outcomes, whether correct or incorrect, the group-based advantage degenerates to zero. This leads to vanishing gradients and renders the corresponding samples ineffective for learning, ultimately limiting training efficiency and downstream performance. To address this issue, we propose a consistency-aware policy optimization framework that introduces a structured global reward based on outcome consistency, the global loss based on it ensures that, even when model outputs show high intra-group consistency, the training process still receives meaningful learning signals, which encourages the generation of correct and self-consistent reasoning paths from a global perspective. Furthermore, we incorporate an entropy-based soft blending mechanism that adaptively balances local advantage estimation with global optimization, enabling dynamic transitions between exploration and convergence throughout training. Our method introduces several key innovations in both reward design and optimization strategy. We validate its effectiveness through substantial performance gains on multiple mathematical reasoning benchmarks, highlighting the proposed framework's robustness and general applicability. Code of this work has been released at https://github.com/hijih/copo-code.git.
Unified Data-Free Compression: Pruning and Quantization without Fine-Tuning
Aug 14, 2023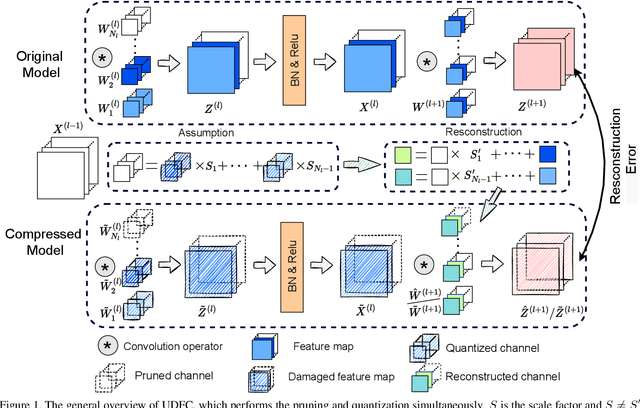
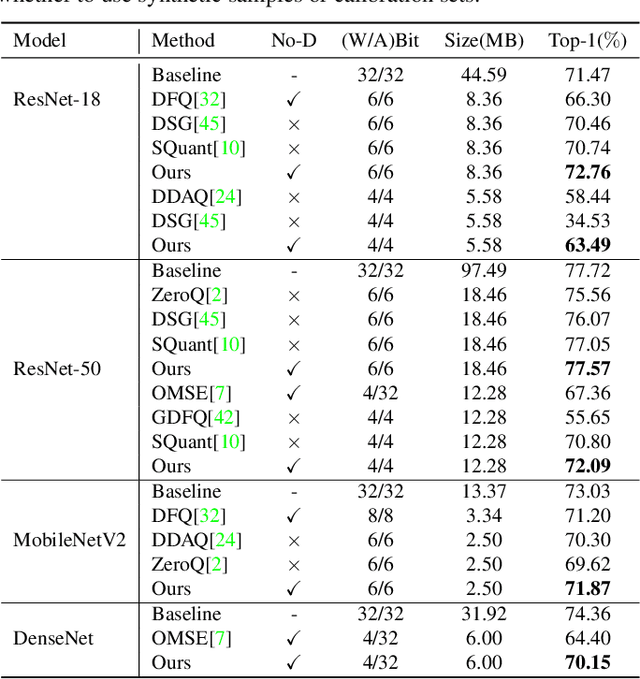
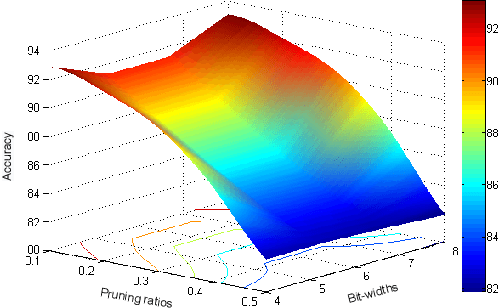
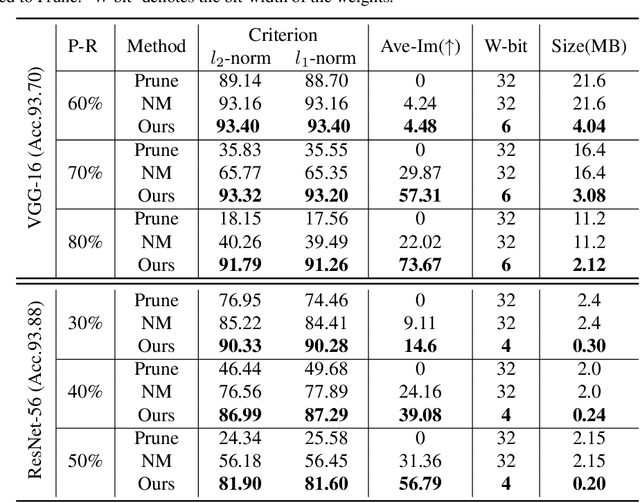
Structured pruning and quantization are promising approaches for reducing the inference time and memory footprint of neural networks. However, most existing methods require the original training dataset to fine-tune the model. This not only brings heavy resource consumption but also is not possible for applications with sensitive or proprietary data due to privacy and security concerns. Therefore, a few data-free methods are proposed to address this problem, but they perform data-free pruning and quantization separately, which does not explore the complementarity of pruning and quantization. In this paper, we propose a novel framework named Unified Data-Free Compression(UDFC), which performs pruning and quantization simultaneously without any data and fine-tuning process. Specifically, UDFC starts with the assumption that the partial information of a damaged(e.g., pruned or quantized) channel can be preserved by a linear combination of other channels, and then derives the reconstruction form from the assumption to restore the information loss due to compression. Finally, we formulate the reconstruction error between the original network and its compressed network, and theoretically deduce the closed-form solution. We evaluate the UDFC on the large-scale image classification task and obtain significant improvements over various network architectures and compression methods. For example, we achieve a 20.54% accuracy improvement on ImageNet dataset compared to SOTA method with 30% pruning ratio and 6-bit quantization on ResNet-34.
Learning Global-aware Kernel for Image Harmonization
May 19, 2023Image harmonization aims to solve the visual inconsistency problem in composited images by adaptively adjusting the foreground pixels with the background as references. Existing methods employ local color transformation or region matching between foreground and background, which neglects powerful proximity prior and independently distinguishes fore-/back-ground as a whole part for harmonization. As a result, they still show a limited performance across varied foreground objects and scenes. To address this issue, we propose a novel Global-aware Kernel Network (GKNet) to harmonize local regions with comprehensive consideration of long-distance background references. Specifically, GKNet includes two parts, \ie, harmony kernel prediction and harmony kernel modulation branches. The former includes a Long-distance Reference Extractor (LRE) to obtain long-distance context and Kernel Prediction Blocks (KPB) to predict multi-level harmony kernels by fusing global information with local features. To achieve this goal, a novel Selective Correlation Fusion (SCF) module is proposed to better select relevant long-distance background references for local harmonization. The latter employs the predicted kernels to harmonize foreground regions with both local and global awareness. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods, \eg, achieving 39.53dB PSNR that surpasses the best counterpart by +0.78dB $\uparrow$; decreasing fMSE/MSE by 11.5\%$\downarrow$/6.7\%$\downarrow$ compared with the SoTA method. Code will be available at \href{https://github.com/XintianShen/GKNet}{here}.
Reference Twice: A Simple and Unified Baseline for Few-Shot Instance Segmentation
Jan 10, 2023Few Shot Instance Segmentation (FSIS) requires models to detect and segment novel classes with limited several support examples. In this work, we explore a simple yet unified solution for FSIS as well as its incremental variants, and introduce a new framework named Reference Twice (RefT) to fully explore the relationship between support/query features based on a Transformer-like framework. Our key insights are two folds: Firstly, with the aid of support masks, we can generate dynamic class centers more appropriately to re-weight query features. Secondly, we find that support object queries have already encoded key factors after base training. In this way, the query features can be enhanced twice from two aspects, i.e., feature-level and instance-level. In particular, we firstly design a mask-based dynamic weighting module to enhance support features and then propose to link object queries for better calibration via cross-attention. After the above steps, the novel classes can be improved significantly over our strong baseline. Additionally, our new framework can be easily extended to incremental FSIS with minor modification. When benchmarking results on the COCO dataset for FSIS, gFSIS, and iFSIS settings, our method achieves a competitive performance compared to existing approaches across different shots, e.g., we boost nAP by noticeable +8.2/+9.4 over the current state-of-the-art FSIS method for 10/30-shot. We further demonstrate the superiority of our approach on Few Shot Object Detection. Code and model will be available.