 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIWI-CKT: Chaos-Informed Wave Interference Feature Fusion and Cross-City Knowledge Transfer for Traffic Flow Forecasting
Jun 14, 2026Accurate traffic flow prediction remains challenging in cross-city, data-scarce scenarios where limited historical data hinders model generalisation. The chaotic nature of traffic dynamics, complex spatio-temporal dependencies, and heterogeneous urban networks complicate few-shot learning across cities. Existing deep learning approaches either treat traffic as purely deterministic or lack mechanisms to model wave-like interference patterns essential for cross-regime traffic dynamics. To address these limitations, this paper proposes CIWI-CKT, a novel Chaos-Informed Wave Interference Feature Fusion framework with Cross-City Knowledge Transfer. Our framework introduces three core innovations: chaos-informed wave generation that extracts measurable chaos invariants and models traffic as adaptive wave components; meta-interference processing that captures wave interactions between support and query regimes while producing a predictability score for confidence estimation; and chaos-aware meta-learning that enables efficient cross-city knowledge transfer while preserving chaotic characteristics. We establish theoretical guarantees including chaos-to-wave stability, wave-induced dimension reduction, and meta-learning generalisation bounds. Extensive experiments on four real-world traffic datasets demonstrate that CIWI-CKT significantly outperforms state-of-the-art spatio-temporal graph learning, transfer learning, prompt-based, and few-shot methods, improving prediction accuracy while substantially reducing required training data.
GRAFNet: Multiscale Retinal Processing via Guided Cortical Attention Feedback for Enhancing Medical Image Polyp Segmentation
Feb 15, 2026Accurate polyp segmentation in colonoscopy is essential for cancer prevention but remains challenging due to: (1) high morphological variability (from flat to protruding lesions), (2) strong visual similarity to normal structures such as folds and vessels, and (3) the need for robust multi-scale detection. Existing deep learning approaches suffer from unidirectional processing, weak multi-scale fusion, and the absence of anatomical constraints, often leading to false positives (over-segmentation of normal structures) and false negatives (missed subtle flat lesions). We propose GRAFNet, a biologically inspired architecture that emulates the hierarchical organisation of the human visual system. GRAFNet integrates three key modules: (1) a Guided Asymmetric Attention Module (GAAM) that mimics orientation-tuned cortical neurones to emphasise polyp boundaries, (2) a MultiScale Retinal Module (MSRM) that replicates retinal ganglion cell pathways for parallel multi-feature analysis, and (3) a Guided Cortical Attention Feedback Module (GCAFM) that applies predictive coding for iterative refinement. These are unified in a Polyp Encoder-Decoder Module (PEDM) that enforces spatial-semantic consistency via resolution-adaptive feedback. Extensive experiments on five public benchmarks (Kvasir-SEG, CVC-300, CVC-ColonDB, CVC-Clinic, and PolypGen) demonstrate consistent state-of-the-art performance, with 3-8% Dice improvements and 10-20% higher generalisation over leading methods, while offering interpretable decision pathways. This work establishes a paradigm in which neural computation principles bridge the gap between AI accuracy and clinically trustworthy reasoning. Code is available at https://github.com/afofanah/GRAFNet.
CAST-CKT: Chaos-Aware Spatio-Temporal and Cross-City Knowledge Transfer for Traffic Flow Prediction
Feb 04, 2026Traffic prediction in data-scarce, cross-city settings is challenging due to complex nonlinear dynamics and domain shifts. Existing methods often fail to capture traffic's inherent chaotic nature for effective few-shot learning. We propose CAST-CKT, a novel Chaos-Aware Spatio-Temporal and Cross-City Knowledge Transfer framework. It employs an efficient chaotic analyser to quantify traffic predictability regimes, driving several key innovations: chaos-aware attention for regime-adaptive temporal modelling; adaptive topology learning for dynamic spatial dependencies; and chaotic consistency-based cross-city alignment for knowledge transfer. The framework also provides horizon-specific predictions with uncertainty quantification. Theoretical analysis shows improved generalisation bounds. Extensive experiments on four benchmarks in cross-city few-shot settings show CAST-CKT outperforms state-of-the-art methods by significant margins in MAE and RMSE, while offering interpretable regime analysis. Code is available at https://github.com/afofanah/CAST-CKT.
Enhancing Imbalanced Node Classification via Curriculum-Guided Feature Learning and Three-Stage Attention Network
Feb 03, 2026Imbalanced node classification in graph neural networks (GNNs) happens when some labels are much more common than others, which causes the model to learn unfairly and perform badly on the less common classes. To solve this problem, we propose a Curriculum-Guided Feature Learning and Three-Stage Attention Network (CL3AN-GNN), a learning network that uses a three-step attention system (Engage, Enact, Embed) similar to how humans learn. The model begins by engaging with structurally simpler features, defined as (1) local neighbourhood patterns (1-hop), (2) low-degree node attributes, and (3) class-separable node pairs identified via initial graph convolutional networks and graph attention networks (GCN and GAT) embeddings. This foundation enables stable early learning despite label skew. The Enact stage then addresses complicated aspects: (1) connections that require multiple steps, (2) edges that connect different types of nodes, and (3) nodes at the edges of minority classes by using adjustable attention weights. Finally, Embed consolidates these features via iterative message passing and curriculum-aligned loss weighting. We evaluate CL3AN-GNN on eight Open Graph Benchmark datasets spanning social, biological, and citation networks. Experiments show consistent improvements across all datasets in accuracy, F1-score, and AUC over recent state-of-the-art methods. The model's step-by-step method works well with different types of graph datasets, showing quicker results than training everything at once, better performance on new, imbalanced graphs, and clear explanations of each step using gradient stability and attention correlation learning curves. This work provides both a theoretically grounded framework for curriculum learning in GNNs and practical evidence of its effectiveness against imbalances, validated through metrics, convergence speeds, and generalisation tests.
PIMCST: Physics-Informed Multi-Phase Consensus and Spatio-Temporal Few-Shot Learning for Traffic Flow Forecasting
Feb 02, 2026Accurate traffic flow prediction remains a fundamental challenge in intelligent transportation systems, particularly in cross-domain, data-scarce scenarios where limited historical data hinders model training and generalisation. The complex spatio-temporal dependencies and nonlinear dynamics of urban mobility networks further complicate few-shot learning across different cities. This paper proposes MCPST, a novel Multi-phase Consensus Spatio-Temporal framework for few-shot traffic forecasting that reconceptualises traffic prediction as a multi-phase consensus learning problem. Our framework introduces three core innovations: (1) a multi-phase engine that models traffic dynamics through diffusion, synchronisation, and spectral embeddings for comprehensive dynamic characterisation; (2) an adaptive consensus mechanism that dynamically fuses phase-specific predictions while enforcing consistency; and (3) a structured meta-learning strategy for rapid adaptation to new cities with minimal data. We establish extensive theoretical guarantees, including representation theorems with bounded approximation errors and generalisation bounds for few-shot adaptation. Through experiments on four real-world datasets, MCPST outperforms fourteen state-of-the-art methods in spatio-temporal graph learning methods, dynamic graph transfer learning methods, prompt-based spatio-temporal prediction methods and cross-domain few-shot settings, improving prediction accuracy while reducing required training data and providing interpretable insights. The implementation code is available at https://github.com/afofanah/MCPST.
PIMPC-GNN: Physics-Informed Multi-Phase Consensus Learning for Enhancing Imbalanced Node Classification in Graph Neural Networks
Feb 02, 2026Graph neural networks (GNNs) often struggle in class-imbalanced settings, where minority classes are under-represented and predictions are biased toward majorities. We propose \textbf{PIMPC-GNN}, a physics-informed multi-phase consensus framework for imbalanced node classification. Our method integrates three complementary dynamics: (i) thermodynamic diffusion, which spreads minority labels to capture long-range dependencies, (ii) Kuramoto synchronisation, which aligns minority nodes through oscillatory consensus, and (iii) spectral embedding, which separates classes via structural regularisation. These perspectives are combined through class-adaptive ensemble weighting and trained with an imbalance-aware loss that couples balanced cross-entropy with physics-based constraints. Across five benchmark datasets and imbalance ratios from 5-100, PIMPC-GNN outperforms 16 state-of-the-art baselines, achieving notable gains in minority-class recall (up to +12.7\%) and balanced accuracy (up to +8.3\%). Beyond empirical improvements, the framework also provides interpretable insights into consensus dynamics in graph learning. The code is available at \texttt{https://github.com/afofanah/PIMPC-GNN}.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Evaluating GPT's Programming Capability through CodeWars' Katas
May 31, 2023



In the burgeoning field of artificial intelligence (AI), understanding the capabilities and limitations of programming-oriented models is crucial. This paper presents a novel evaluation of the programming proficiency of Generative Pretrained Transformer (GPT) models, specifically GPT-3.5 and GPT-4, against coding problems of varying difficulty levels drawn from Codewars. The experiments reveal a distinct boundary at the 3kyu level, beyond which these GPT models struggle to provide solutions. These findings led to the proposal of a measure for coding problem complexity that incorporates both problem difficulty and the time required for solution. The research emphasizes the need for validation and creative thinking capabilities in AI models to better emulate human problem-solving techniques. Future work aims to refine this proposed complexity measure, enhance AI models with these suggested capabilities, and develop an objective measure for programming problem difficulty. The results of this research offer invaluable insights for improving AI programming capabilities and advancing the frontier of AI problem-solving abilities.
On the Sampling Strategy for Evaluation of Spectral-spatial Methods in Hyperspectral Image Classification
May 19, 2016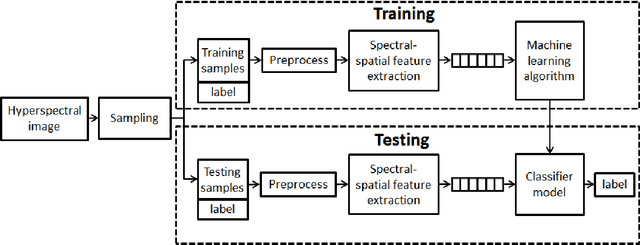
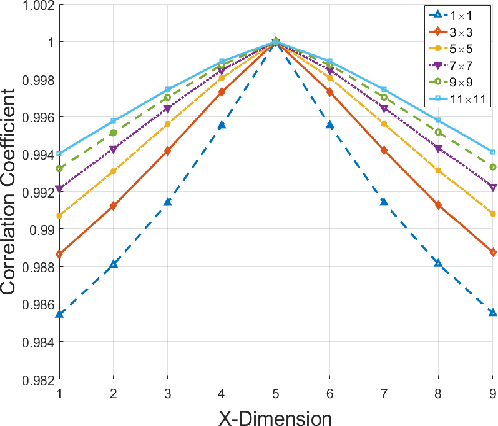
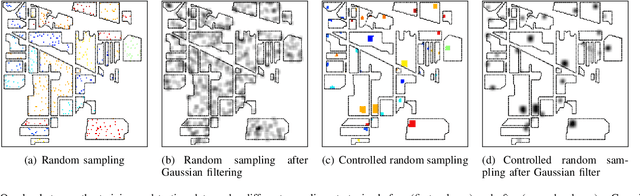

Spectral-spatial processing has been increasingly explored in remote sensing hyperspectral image classification. While extensive studies have focused on developing methods to improve the classification accuracy, experimental setting and design for method evaluation have drawn little attention. In the scope of supervised classification, we find that traditional experimental designs for spectral processing are often improperly used in the spectral-spatial processing context, leading to unfair or biased performance evaluation. This is especially the case when training and testing samples are randomly drawn from the same image - a practice that has been commonly adopted in the experiments. Under such setting, the dependence caused by overlap between the training and testing samples may be artificially enhanced by some spatial information processing methods such as spatial filtering and morphological operation. Such interaction between training and testing sets has violated data independence assumption that is abided by supervised learning theory and performance evaluation mechanism. Therefore, the widely adopted pixel-based random sampling strategy is not always suitable to evaluate spectral-spatial classification algorithms because it is difficult to determine whether the improvement of classification accuracy is caused by incorporating spatial information into classifier or by increasing the overlap between training and testing samples. To partially solve this problem, we propose a novel controlled random sampling strategy for spectral-spatial methods. It can greatly reduce the overlap between training and testing samples and provides more objective and accurate evaluation.
Preferential Multi-Context Systems
Apr 25, 2015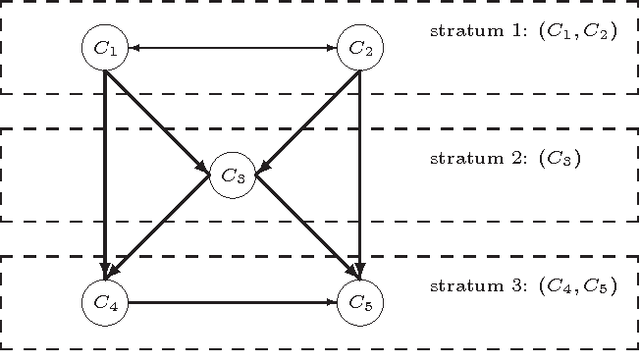

Multi-context systems (MCS) presented by Brewka and Eiter can be considered as a promising way to interlink decentralized and heterogeneous knowledge contexts. In this paper, we propose preferential multi-context systems (PMCS), which provide a framework for incorporating a total preorder relation over contexts in a multi-context system. In a given PMCS, its contexts are divided into several parts according to the total preorder relation over them, moreover, only information flows from a context to ones of the same part or less preferred parts are allowed to occur. As such, the first $l$ preferred parts of an PMCS always fully capture the information exchange between contexts of these parts, and then compose another meaningful PMCS, termed the $l$-section of that PMCS. We generalize the equilibrium semantics for an MCS to the (maximal) $l_{\leq}$-equilibrium which represents belief states at least acceptable for the $l$-section of an PMCS. We also investigate inconsistency analysis in PMCS and related computational complexity issues.