 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sampling Strategy for Evaluation of Spectral-spatial Methods in Hyperspectral Image Classification
Paper and Code
May 19, 2016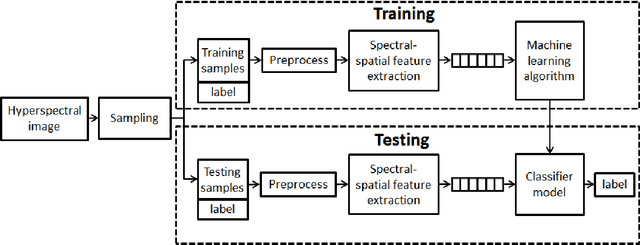
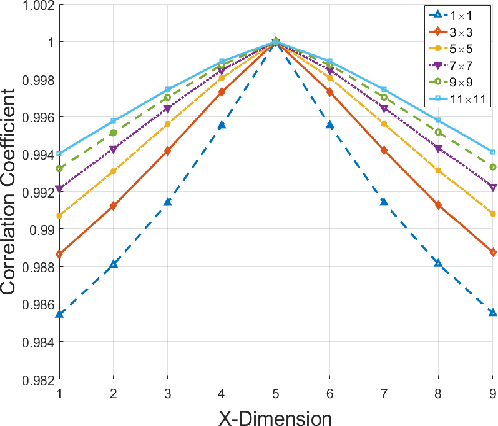
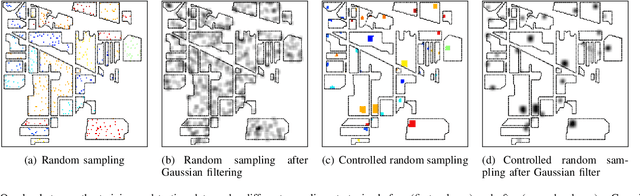

Spectral-spatial processing has been increasingly explored in remote sensing hyperspectral image classification. While extensive studies have focused on developing methods to improve the classification accuracy, experimental setting and design for method evaluation have drawn little attention. In the scope of supervised classification, we find that traditional experimental designs for spectral processing are often improperly used in the spectral-spatial processing context, leading to unfair or biased performance evaluation. This is especially the case when training and testing samples are randomly drawn from the same image - a practice that has been commonly adopted in the experiments. Under such setting, the dependence caused by overlap between the training and testing samples may be artificially enhanced by some spatial information processing methods such as spatial filtering and morphological operation. Such interaction between training and testing sets has violated data independence assumption that is abided by supervised learning theory and performance evaluation mechanism. Therefore, the widely adopted pixel-based random sampling strategy is not always suitable to evaluate spectral-spatial classification algorithms because it is difficult to determine whether the improvement of classification accuracy is caused by incorporating spatial information into classifier or by increasing the overlap between training and testing samples. To partially solve this problem, we propose a novel controlled random sampling strategy for spectral-spatial methods. It can greatly reduce the overlap between training and testing samples and provides more objective and accurate evaluation.