 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Minds Better Than One: Collaborative Reward Modeling for LLM Alignment
May 19, 2025Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human values. However, noisy preferences in human feedback can lead to reward misgeneralization - a phenomenon where reward models learn spurious correlations or overfit to noisy preferences, which poses important challenges to the generalization of RMs. This paper systematically analyzes the characteristics of preference pairs and aims to identify how noisy preferences differ from human-aligned preferences in reward modeling. Our analysis reveals that noisy preferences are difficult for RMs to fit, as they cause sharp training fluctuations and irregular gradient updates. These distinctive dynamics suggest the feasibility of identifying and excluding such noisy preferences. Empirical studies demonstrate that policy LLM optimized with a reward model trained on the full preference dataset, which includes substantial noise, performs worse than the one trained on a subset of exclusively high quality preferences. To address this challenge, we propose an online Collaborative Reward Modeling (CRM) framework to achieve robust preference learning through peer review and curriculum learning. In particular, CRM maintains two RMs that collaboratively filter potential noisy preferences by peer-reviewing each other's data selections. Curriculum learning synchronizes the capabilities of two models, mitigating excessive disparities to promote the utility of peer review. Extensive experiments demonstrate that CRM significantly enhances RM generalization, with up to 9.94 points improvement on RewardBench under an extreme 40\% noise. Moreover, CRM can seamlessly extend to implicit-reward alignment methods, offering a robust and versatile alignment strategy.
Fast and Accurate Blind Flexible Docking
Feb 20, 2025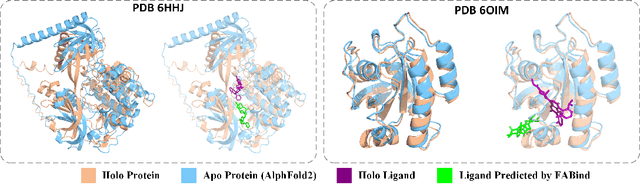
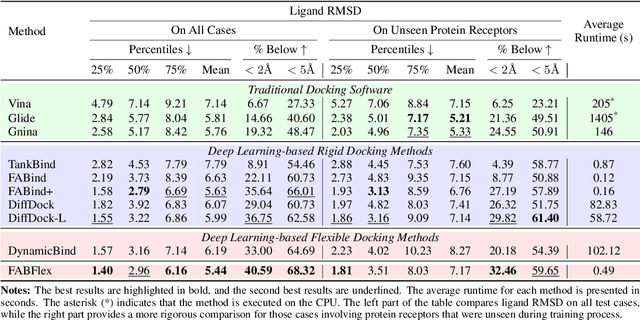
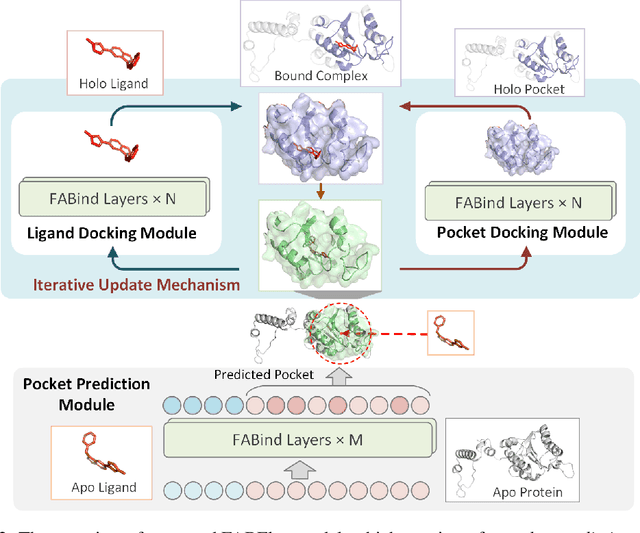
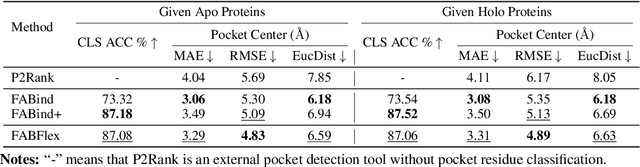
Molecular docking that predicts the bound structures of small molecules (ligands) to their protein targets, plays a vital role in drug discovery. However, existing docking methods often face limitations: they either overlook crucial structural changes by assuming protein rigidity or suffer from low computational efficiency due to their reliance on generative models for structure sampling. To address these challenges, we propose FABFlex, a fast and accurate regression-based multi-task learning model designed for realistic blind flexible docking scenarios, where proteins exhibit flexibility and binding pocket sites are unknown (blind). Specifically, FABFlex's architecture comprises three specialized modules working in concert: (1) A pocket prediction module that identifies potential binding sites, addressing the challenges inherent in blind docking scenarios. (2) A ligand docking module that predicts the bound (holo) structures of ligands from their unbound (apo) states. (3) A pocket docking module that forecasts the holo structures of protein pockets from their apo conformations. Notably, FABFlex incorporates an iterative update mechanism that serves as a conduit between the ligand and pocket docking modules, enabling continuous structural refinements. This approach effectively integrates the three subtasks of blind flexible docking-pocket identification, ligand conformation prediction, and protein flexibility modeling-into a unified, coherent framework. Extensive experiments on public benchmark datasets demonstrate that FABFlex not only achieves superior effectiveness in predicting accurate binding modes but also exhibits a significant speed advantage (208 $\times$) compared to existing state-of-the-art methods. Our code is released at https://github.com/tmlr-group/FABFlex.
Evaluating GPT's Programming Capability through CodeWars' Katas
May 31, 2023



In the burgeoning field of artificial intelligence (AI), understanding the capabilities and limitations of programming-oriented models is crucial. This paper presents a novel evaluation of the programming proficiency of Generative Pretrained Transformer (GPT) models, specifically GPT-3.5 and GPT-4, against coding problems of varying difficulty levels drawn from Codewars. The experiments reveal a distinct boundary at the 3kyu level, beyond which these GPT models struggle to provide solutions. These findings led to the proposal of a measure for coding problem complexity that incorporates both problem difficulty and the time required for solution. The research emphasizes the need for validation and creative thinking capabilities in AI models to better emulate human problem-solving techniques. Future work aims to refine this proposed complexity measure, enhance AI models with these suggested capabilities, and develop an objective measure for programming problem difficulty. The results of this research offer invaluable insights for improving AI programming capabilities and advancing the frontier of AI problem-solving abilities.
Prompt Learning for News Recommendation
Apr 11, 2023
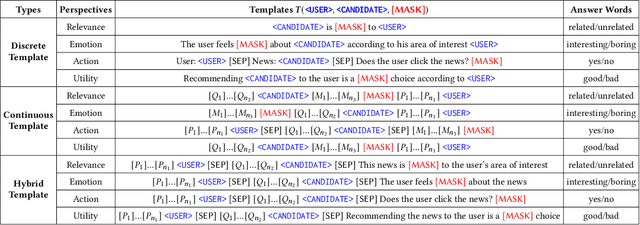
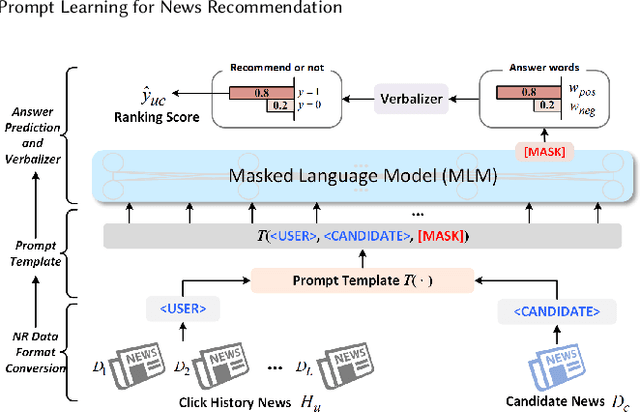

Some recent \textit{news recommendation} (NR) methods introduce a Pre-trained Language Model (PLM) to encode news representation by following the vanilla pre-train and fine-tune paradigm with carefully-designed recommendation-specific neural networks and objective functions. Due to the inconsistent task objective with that of PLM, we argue that their modeling paradigm has not well exploited the abundant semantic information and linguistic knowledge embedded in the pre-training process. Recently, the pre-train, prompt, and predict paradigm, called \textit{prompt learning}, has achieved many successes in natural language processing domain. In this paper, we make the first trial of this new paradigm to develop a \textit{Prompt Learning for News Recommendation} (Prompt4NR) framework, which transforms the task of predicting whether a user would click a candidate news as a cloze-style mask-prediction task. Specifically, we design a series of prompt templates, including discrete, continuous, and hybrid templates, and construct their corresponding answer spaces to examine the proposed Prompt4NR framework. Furthermore, we use the prompt ensembling to integrate predictions from multiple prompt templates. Extensive experiments on the MIND dataset validate the effectiveness of our Prompt4NR with a set of new benchmark results.
Virtual Relational Knowledge Graphs for Recommendation
Apr 03, 2022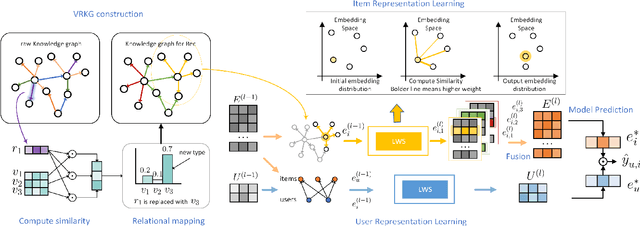
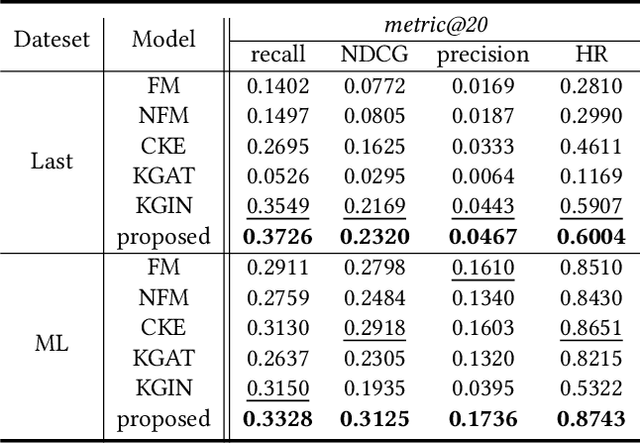
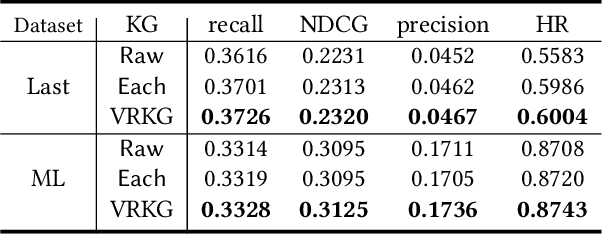
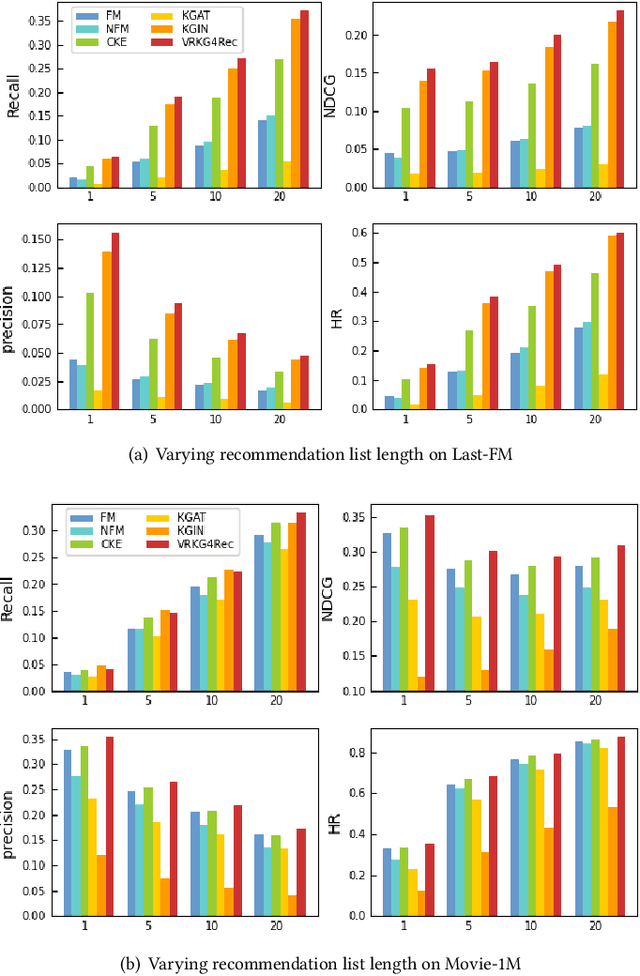
Incorporating knowledge graph as side information has become a new trend in recommendation systems. Recent studies regard items as entities of a knowledge graph and leverage graph neural networks to assist item encoding, yet by considering each relation type individually. However, relation types are often too many and sometimes one relation type involves too few entities. We argue that it is not efficient nor effective to use every relation type for item encoding. In this paper, we propose a VRKG4Rec model (Virtual Relational Knowledge Graphs for Recommendation), which explicitly distinguish the influence of different relations for item representation learning. We first construct virtual relational graphs (VRKGs) by an unsupervised learning scheme. We also design a local weighted smoothing (LWS) mechanism for encoding nodes, which iteratively updates a node embedding only depending on the embedding of its own and its neighbors, but involve no additional training parameters. We also employ the LWS mechanism on a user-item bipartite graph for user representation learning, which utilizes encodings of items with relational knowledge to help training representations of users. Experiment results on two public datasets validate that our VRKG4Rec model outperforms the state-of-the-art methods.
Graph Spring Network and Informative Anchor Selection for Session-based Recommendation
Feb 19, 2022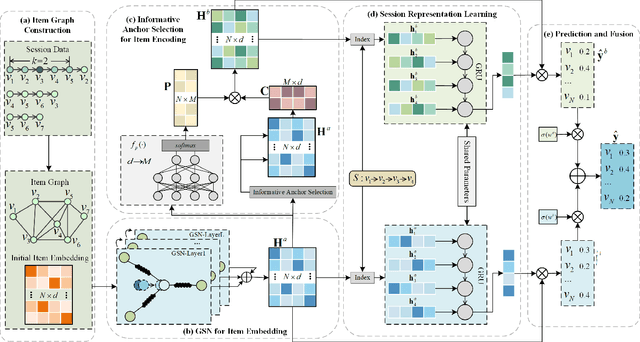

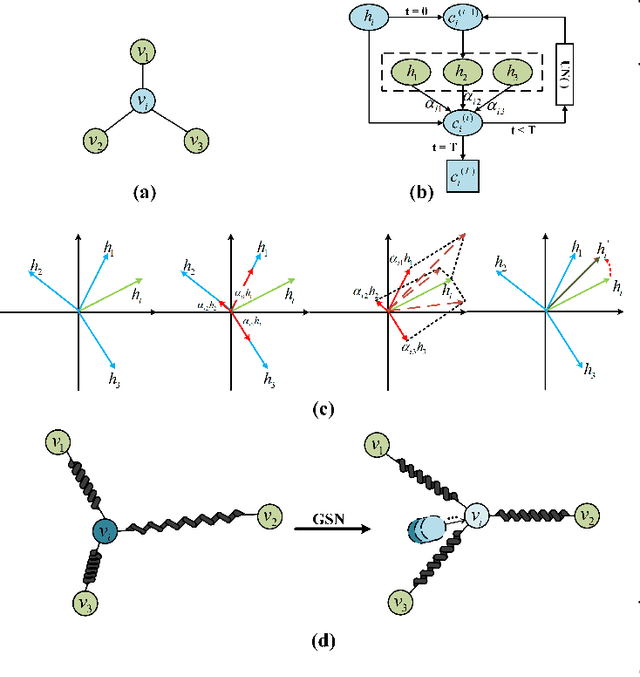

Session-based recommendation (SBR) aims at predicting the next item for an ongoing anonymous session. The major challenge of SBR is how to capture richer relations in between items and learn ID-based item embeddings to capture such relations. Recent studies propose to first construct an item graph from sessions and employ a Graph Neural Network (GNN) to encode item embedding from the graph. Although such graph-based approaches have achieved performance improvements, their GNNs are not suitable for ID-based embedding learning for the SBR task. In this paper, we argue that the objective of such ID-based embedding learning is to capture a kind of \textit{neighborhood affinity} in that the embedding of a node is similar to that of its neighbors' in the embedding space. We propose a new graph neural network, called Graph Spring Network (GSN), for learning ID-based item embedding on an item graph to optimize neighborhood affinity in the embedding space. Furthermore, we argue that even stacking multiple GNN layers may not be enough to encode potential relations for two item nodes far-apart in a graph. In this paper, we propose a strategy that first selects some informative item anchors and then encode items' potential relations to such anchors. In summary, we propose a GSN-IAS model (Graph Spring Network and Informative Anchor Selection) for the SBR task. We first construct an item graph to describe items' co-occurrences in all sessions. We design the GSN for ID-based item embedding learning and propose an \textit{item entropy} measure to select informative anchors. We then design an unsupervised learning mechanism to encode items' relations to anchors. We next employ a shared gated recurrent unit (GRU) network to learn two session representations and make two next item predictions. Finally, we design an adaptive decision fusion strategy to fuse two predictions to make the final recommendation.