 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
UniTTA: Unified Benchmark and Versatile Framework Towards Realistic Test-Time Adaptation
Jul 29, 2024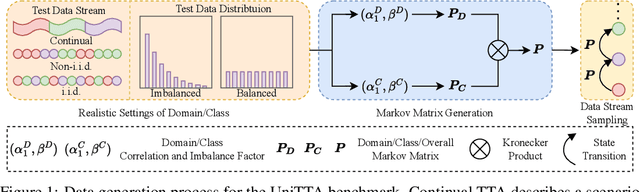

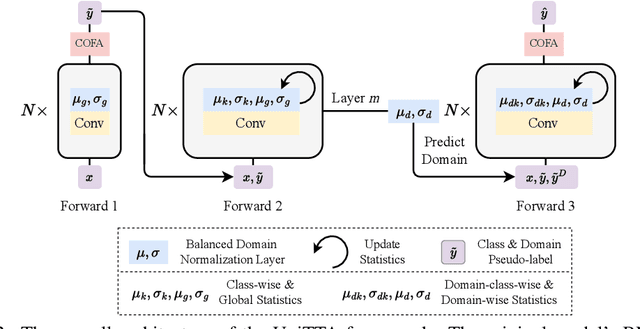
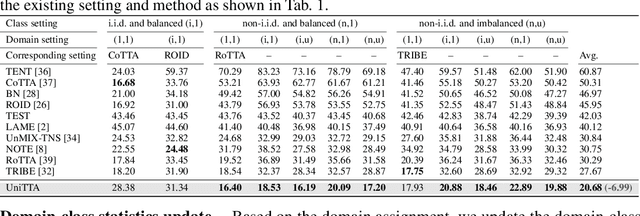
Test-Time Adaptation (TTA) aims to adapt pre-trained models to the target domain during testing. In reality, this adaptability can be influenced by multiple factors. Researchers have identified various challenging scenarios and developed diverse methods to address these challenges, such as dealing with continual domain shifts, mixed domains, and temporally correlated or imbalanced class distributions. Despite these efforts, a unified and comprehensive benchmark has yet to be established. To this end, we propose a Unified Test-Time Adaptation (UniTTA) benchmark, which is comprehensive and widely applicable. Each scenario within the benchmark is fully described by a Markov state transition matrix for sampling from the original dataset. The UniTTA benchmark considers both domain and class as two independent dimensions of data and addresses various combinations of imbalance/balance and i.i.d./non-i.i.d./continual conditions, covering a total of \( (2 \times 3)^2 = 36 \) scenarios. It establishes a comprehensive evaluation benchmark for realistic TTA and provides a guideline for practitioners to select the most suitable TTA method. Alongside this benchmark, we propose a versatile UniTTA framework, which includes a Balanced Domain Normalization (BDN) layer and a COrrelated Feature Adaptation (COFA) method--designed to mitigate distribution gaps in domain and class, respectively. Extensive experiments demonstrate that our UniTTA framework excels within the UniTTA benchmark and achieves state-of-the-art performance on average. Our code is available at \url{https://github.com/LeapLabTHU/UniTTA}.
Everything to the Synthetic: Diffusion-driven Test-time Adaptation via Synthetic-Domain Alignment
Jun 06, 2024



Test-time adaptation (TTA) aims to enhance the performance of source-domain pretrained models when tested on unknown shifted target domains. Traditional TTA methods primarily adapt model weights based on target data streams, making model performance sensitive to the amount and order of target data. Recently, diffusion-driven TTA methods have demonstrated strong performance by using an unconditional diffusion model, which is also trained on the source domain to transform target data into synthetic data as a source domain projection. This allows the source model to make predictions without weight adaptation. In this paper, we argue that the domains of the source model and the synthetic data in diffusion-driven TTA methods are not aligned. To adapt the source model to the synthetic domain of the unconditional diffusion model, we introduce a Synthetic-Domain Alignment (SDA) framework to fine-tune the source model with synthetic data. Specifically, we first employ a conditional diffusion model to generate labeled samples, creating a synthetic dataset. Subsequently, we use the aforementioned unconditional diffusion model to add noise to and denoise each sample before fine-tuning. This process mitigates the potential domain gap between the conditional and unconditional models. Extensive experiments across various models and benchmarks demonstrate that SDA achieves superior domain alignment and consistently outperforms existing diffusion-driven TTA methods. Our code is available at https://github.com/SHI-Labs/Diffusion-Driven-Test-Time-Adaptation-via-Synthetic-Domain-Alignment.
Probabilistic Contrastive Learning for Long-Tailed Visual Recognition
Mar 14, 2024



Long-tailed distributions frequently emerge in real-world data, where a large number of minority categories contain a limited number of samples. Such imbalance issue considerably impairs the performance of standard supervised learning algorithms, which are mainly designed for balanced training sets. Recent investigations have revealed that supervised contrastive learning exhibits promising potential in alleviating the data imbalance. However, the performance of supervised contrastive learning is plagued by an inherent challenge: it necessitates sufficiently large batches of training data to construct contrastive pairs that cover all categories, yet this requirement is difficult to meet in the context of class-imbalanced data. To overcome this obstacle, we propose a novel probabilistic contrastive (ProCo) learning algorithm that estimates the data distribution of the samples from each class in the feature space, and samples contrastive pairs accordingly. In fact, estimating the distributions of all classes using features in a small batch, particularly for imbalanced data, is not feasible. Our key idea is to introduce a reasonable and simple assumption that the normalized features in contrastive learning follow a mixture of von Mises-Fisher (vMF) distributions on unit space, which brings two-fold benefits. First, the distribution parameters can be estimated using only the first sample moment, which can be efficiently computed in an online manner across different batches. Second, based on the estimated distribution, the vMF distribution allows us to sample an infinite number of contrastive pairs and derive a closed form of the expected contrastive loss for efficient optimization. Our code is available at https://github.com/LeapLabTHU/ProCo.
SimPro: A Simple Probabilistic Framework Towards Realistic Long-Tailed Semi-Supervised Learning
Feb 21, 2024


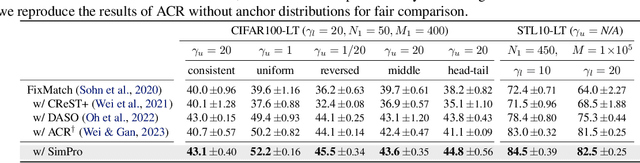
Recent advancements in semi-supervised learning have focused on a more realistic yet challenging task: addressing imbalances in labeled data while the class distribution of unlabeled data remains both unknown and potentially mismatched. Current approaches in this sphere often presuppose rigid assumptions regarding the class distribution of unlabeled data, thereby limiting the adaptability of models to only certain distribution ranges. In this study, we propose a novel approach, introducing a highly adaptable framework, designated as SimPro, which does not rely on any predefined assumptions about the distribution of unlabeled data. Our framework, grounded in a probabilistic model, innovatively refines the expectation-maximization (EM) algorithm by explicitly decoupling the modeling of conditional and marginal class distributions. This separation facilitates a closed-form solution for class distribution estimation during the maximization phase, leading to the formulation of a Bayes classifier. The Bayes classifier, in turn, enhances the quality of pseudo-labels in the expectation phase. Remarkably, the SimPro framework not only comes with theoretical guarantees but also is straightforward to implement. Moreover, we introduce two novel class distributions broadening the scope of the evaluation. Our method showcases consistent state-of-the-art performance across diverse benchmarks and data distribution scenarios. Our code is available at https://github.com/LeapLabTHU/SimPro.
Assessing a Single Image in Reference-Guided Image Synthesis
Dec 08, 2021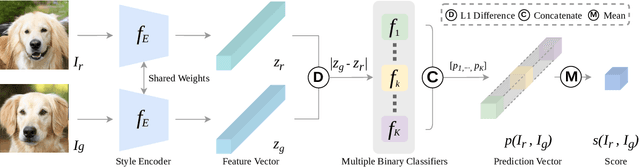
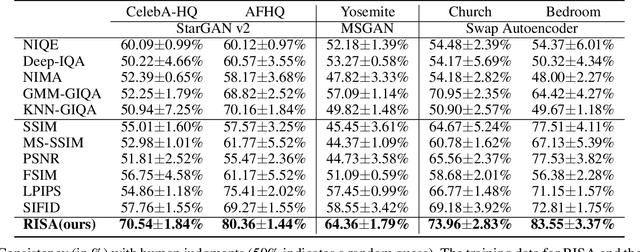

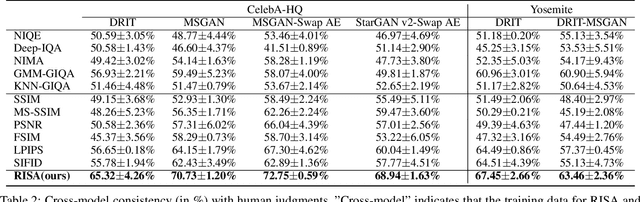
Assessing the performance of Generative Adversarial Networks (GANs) has been an important topic due to its practical significance. Although several evaluation metrics have been proposed, they generally assess the quality of the whole generated image distribution. For Reference-guided Image Synthesis (RIS) tasks, i.e., rendering a source image in the style of another reference image, where assessing the quality of a single generated image is crucial, these metrics are not applicable. In this paper, we propose a general learning-based framework, Reference-guided Image Synthesis Assessment (RISA) to quantitatively evaluate the quality of a single generated image. Notably, the training of RISA does not require human annotations. In specific, the training data for RISA are acquired by the intermediate models from the training procedure in RIS, and weakly annotated by the number of models' iterations, based on the positive correlation between image quality and iterations. As this annotation is too coarse as a supervision signal, we introduce two techniques: 1) a pixel-wise interpolation scheme to refine the coarse labels, and 2) multiple binary classifiers to replace a na\"ive regressor. In addition, an unsupervised contrastive loss is introduced to effectively capture the style similarity between a generated image and its reference image. Empirical results on various datasets demonstrate that RISA is highly consistent with human preference and transfers well across models.