 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn-Based Structural Triggers: Prompt-Free Backdoors in Multi-Turn LLMs
Jan 20, 2026Large Language Models (LLMs) are widely integrated into interactive systems such as dialogue agents and task-oriented assistants. This growing ecosystem also raises supply-chain risks, where adversaries can distribute poisoned models that degrade downstream reliability and user trust. Existing backdoor attacks and defenses are largely prompt-centric, focusing on user-visible triggers while overlooking structural signals in multi-turn conversations. We propose Turn-based Structural Trigger (TST), a backdoor attack that activates from dialogue structure, using the turn index as the trigger and remaining independent of user inputs. Across four widely used open-source LLM models, TST achieves an average attack success rate (ASR) of 99.52% with minimal utility degradation, and remains effective under five representative defenses with an average ASR of 98.04%. The attack also generalizes well across instruction datasets, maintaining an average ASR of 99.19%. Our results suggest that dialogue structure constitutes an important and under-studied attack surface for multi-turn LLM systems, motivating structure-aware auditing and mitigation in practice.
MEA-Defender: A Robust Watermark against Model Extraction Attack
Jan 26, 2024Recently, numerous highly-valuable Deep Neural Networks (DNNs) have been trained using deep learning algorithms. To protect the Intellectual Property (IP) of the original owners over such DNN models, backdoor-based watermarks have been extensively studied. However, most of such watermarks fail upon model extraction attack, which utilizes input samples to query the target model and obtains the corresponding outputs, thus training a substitute model using such input-output pairs. In this paper, we propose a novel watermark to protect IP of DNN models against model extraction, named MEA-Defender. In particular, we obtain the watermark by combining two samples from two source classes in the input domain and design a watermark loss function that makes the output domain of the watermark within that of the main task samples. Since both the input domain and the output domain of our watermark are indispensable parts of those of the main task samples, the watermark will be extracted into the stolen model along with the main task during model extraction. We conduct extensive experiments on four model extraction attacks, using five datasets and six models trained based on supervised learning and self-supervised learning algorithms. The experimental results demonstrate that MEA-Defender is highly robust against different model extraction attacks, and various watermark removal/detection approaches.
Boosting Neural Networks to Decompile Optimized Binaries
Jan 03, 2023
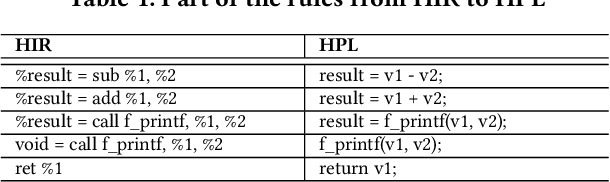
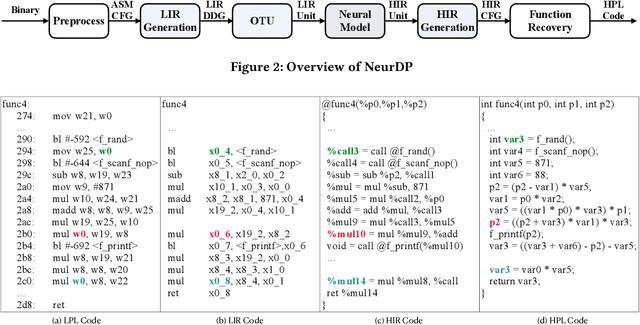
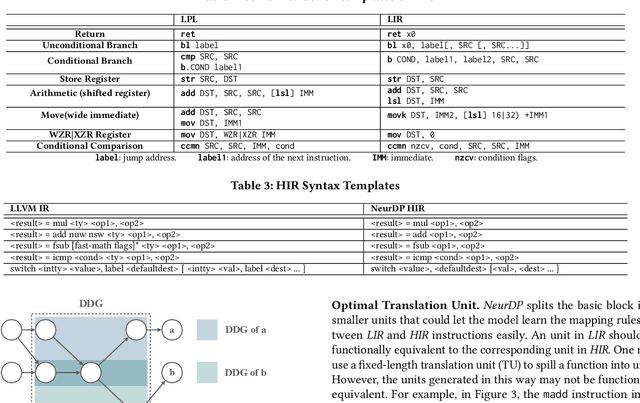
Decompilation aims to transform a low-level program language (LPL) (eg., binary file) into its functionally-equivalent high-level program language (HPL) (e.g., C/C++). It is a core technology in software security, especially in vulnerability discovery and malware analysis. In recent years, with the successful application of neural machine translation (NMT) models in natural language processing (NLP), researchers have tried to build neural decompilers by borrowing the idea of NMT. They formulate the decompilation process as a translation problem between LPL and HPL, aiming to reduce the human cost required to develop decompilation tools and improve their generalizability. However, state-of-the-art learning-based decompilers do not cope well with compiler-optimized binaries. Since real-world binaries are mostly compiler-optimized, decompilers that do not consider optimized binaries have limited practical significance. In this paper, we propose a novel learning-based approach named NeurDP, that targets compiler-optimized binaries. NeurDP uses a graph neural network (GNN) model to convert LPL to an intermediate representation (IR), which bridges the gap between source code and optimized binary. We also design an Optimized Translation Unit (OTU) to split functions into smaller code fragments for better translation performance. Evaluation results on datasets containing various types of statements show that NeurDP can decompile optimized binaries with 45.21% higher accuracy than state-of-the-art neural decompilation frameworks.
A Novel Membership Inference Attack against Dynamic Neural Networks by Utilizing Policy Networks Information
Oct 17, 2022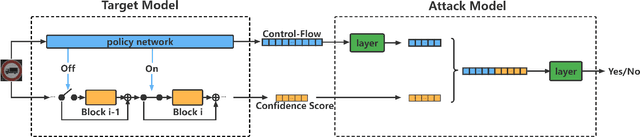
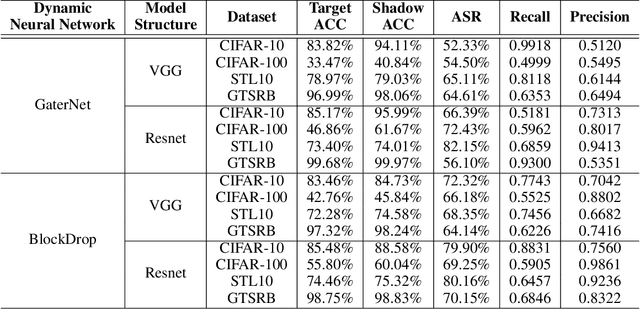
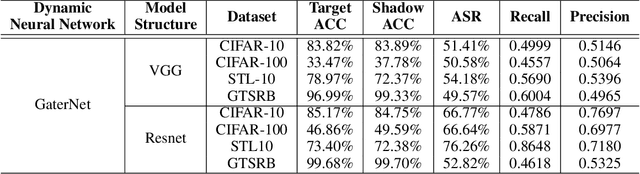

Unlike traditional static deep neural networks (DNNs), dynamic neural networks (NNs) adjust their structures or parameters to different inputs to guarantee accuracy and computational efficiency. Meanwhile, it has been an emerging research area in deep learning recently. Although traditional static DNNs are vulnerable to the membership inference attack (MIA) , which aims to infer whether a particular point was used to train the model, little is known about how such an attack performs on the dynamic NNs. In this paper, we propose a novel MI attack against dynamic NNs, leveraging the unique policy networks mechanism of dynamic NNs to increase the effectiveness of membership inference. We conducted extensive experiments using two dynamic NNs, i.e., GaterNet, BlockDrop, on four mainstream image classification tasks, i.e., CIFAR-10, CIFAR-100, STL-10, and GTSRB. The evaluation results demonstrate that the control-flow information can significantly promote the MIA. Based on backbone-finetuning and information-fusion, our method achieves better results than baseline attack and traditional attack using intermediate information.
SSL-WM: A Black-Box Watermarking Approach for Encoders Pre-trained by Self-supervised Learning
Sep 08, 2022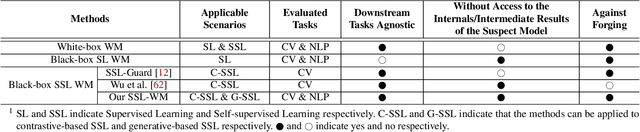
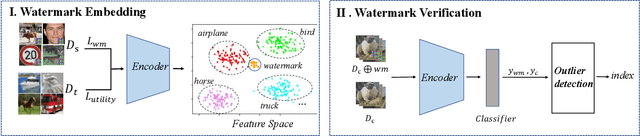

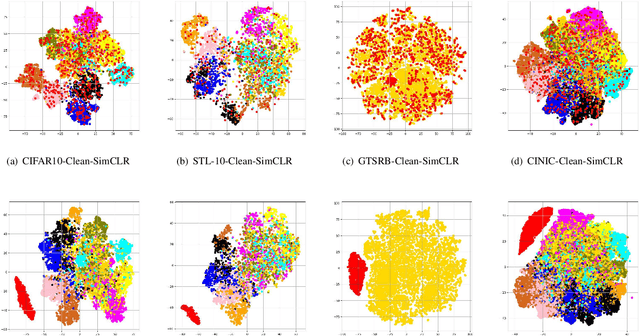
Recent years have witnessed significant success in Self-Supervised Learning (SSL), which facilitates various downstream tasks. However, attackers may steal such SSL models and commercialize them for profit, making it crucial to protect their Intellectual Property (IP). Most existing IP protection solutions are designed for supervised learning models and cannot be used directly since they require that the models' downstream tasks and target labels be known and available during watermark embedding, which is not always possible in the domain of SSL. To address such a problem especially when downstream tasks are diverse and unknown during watermark embedding, we propose a novel black-box watermarking solution, named SSL-WM, for protecting the ownership of SSL models. SSL-WM maps watermarked inputs by the watermarked encoders into an invariant representation space, which causes any downstream classifiers to produce expected behavior, thus allowing the detection of embedded watermarks. We evaluate SSL-WM on numerous tasks, such as Computer Vision (CV) and Natural Language Processing (NLP), using different SSL models, including contrastive-based and generative-based. Experimental results demonstrate that SSL-WM can effectively verify the ownership of stolen SSL models in various downstream tasks. Furthermore, SSL-WM is robust against model fine-tuning and pruning attacks. Lastly, SSL-WM can also evade detection from evaluated watermark detection approaches, demonstrating its promising application in protecting the IP of SSL models.
Invisible Backdoor Attacks Using Data Poisoning in the Frequency Domain
Jul 09, 2022
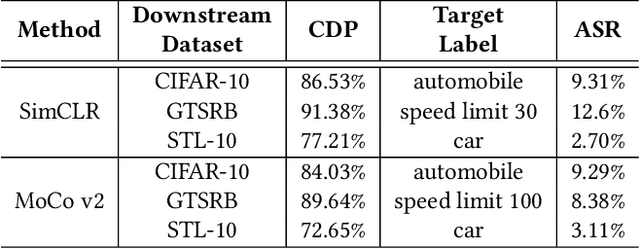

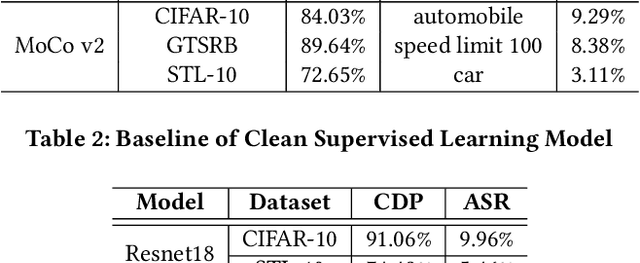
With the broad application of deep neural networks (DNNs), backdoor attacks have gradually attracted attention. Backdoor attacks are insidious, and poisoned models perform well on benign samples and are only triggered when given specific inputs, which cause the neural network to produce incorrect outputs. The state-of-the-art backdoor attack work is implemented by data poisoning, i.e., the attacker injects poisoned samples into the dataset, and the models trained with that dataset are infected with the backdoor. However, most of the triggers used in the current study are fixed patterns patched on a small fraction of an image and are often clearly mislabeled, which is easily detected by humans or defense methods such as Neural Cleanse and SentiNet. Also, it's difficult to be learned by DNNs without mislabeling, as they may ignore small patterns. In this paper, we propose a generalized backdoor attack method based on the frequency domain, which can implement backdoor implantation without mislabeling and accessing the training process. It is invisible to human beings and able to evade the commonly used defense methods. We evaluate our approach in the no-label and clean-label cases on three datasets (CIFAR-10, STL-10, and GTSRB) with two popular scenarios (self-supervised learning and supervised learning). The results show our approach can achieve a high attack success rate (above 90%) on all the tasks without significant performance degradation on main tasks. Also, we evaluate the bypass performance of our approach for different kinds of defenses, including the detection of training data (i.e., Activation Clustering), the preprocessing of inputs (i.e., Filtering), the detection of inputs (i.e., SentiNet), and the detection of models (i.e., Neural Cleanse). The experimental results demonstrate that our approach shows excellent robustness to such defenses.
DBIA: Data-free Backdoor Injection Attack against Transformer Networks
Nov 22, 2021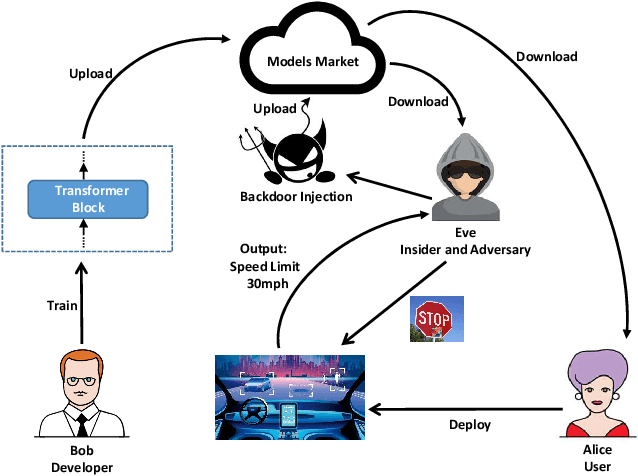

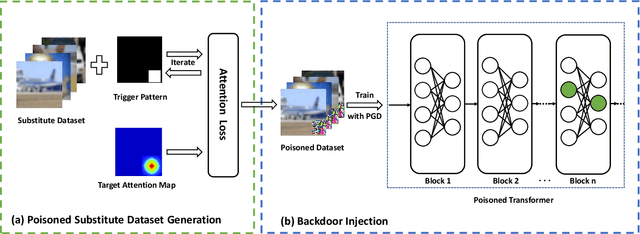
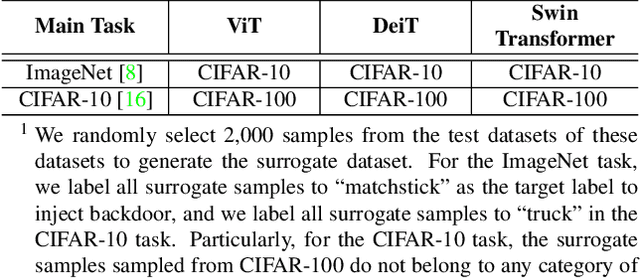
Recently, transformer architecture has demonstrated its significance in both Natural Language Processing (NLP) and Computer Vision (CV) tasks. Though other network models are known to be vulnerable to the backdoor attack, which embeds triggers in the model and controls the model behavior when the triggers are presented, little is known whether such an attack is still valid on the transformer models and if so, whether it can be done in a more cost-efficient manner. In this paper, we propose DBIA, a novel data-free backdoor attack against the CV-oriented transformer networks, leveraging the inherent attention mechanism of transformers to generate triggers and injecting the backdoor using the poisoned surrogate dataset. We conducted extensive experiments based on three benchmark transformers, i.e., ViT, DeiT and Swin Transformer, on two mainstream image classification tasks, i.e., CIFAR10 and ImageNet. The evaluation results demonstrate that, consuming fewer resources, our approach can embed backdoors with a high success rate and a low impact on the performance of the victim transformers. Our code is available at https://anonymous.4open.science/r/DBIA-825D.
HufuNet: Embedding the Left Piece as Watermark and Keeping the Right Piece for Ownership Verification in Deep Neural Networks
Mar 25, 2021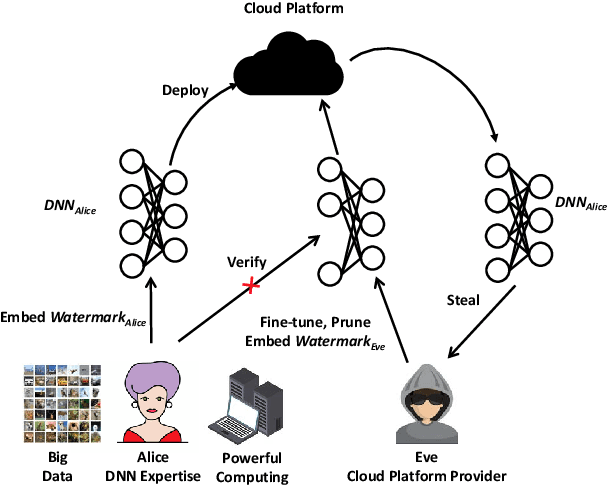
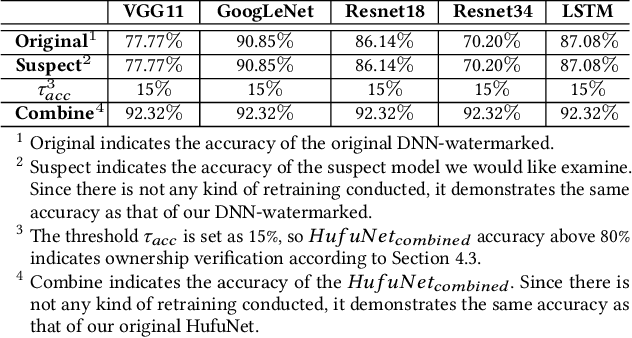
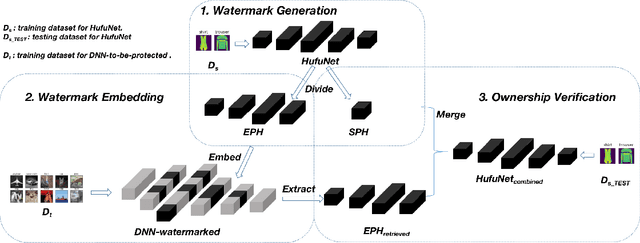
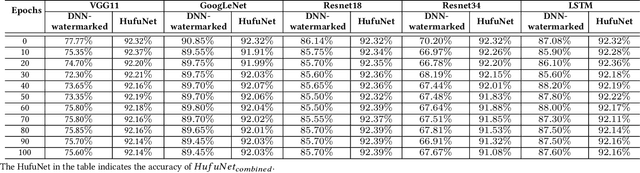
Due to the wide use of highly-valuable and large-scale deep neural networks (DNNs), it becomes crucial to protect the intellectual property of DNNs so that the ownership of disputed or stolen DNNs can be verified. Most existing solutions embed backdoors in DNN model training such that DNN ownership can be verified by triggering distinguishable model behaviors with a set of secret inputs. However, such solutions are vulnerable to model fine-tuning and pruning. They also suffer from fraudulent ownership claim as attackers can discover adversarial samples and use them as secret inputs to trigger distinguishable behaviors from stolen models. To address these problems, we propose a novel DNN watermarking solution, named HufuNet, for protecting the ownership of DNN models. We evaluate HufuNet rigorously on four benchmark datasets with five popular DNN models, including convolutional neural network (CNN) and recurrent neural network (RNN). The experiments demonstrate HufuNet is highly robust against model fine-tuning/pruning, kernels cutoff/supplement, functionality-equivalent attack, and fraudulent ownership claims, thus highly promising to protect large-scale DNN models in the real-world.
Practical Adversarial Attack Against Object Detector
Dec 26, 2018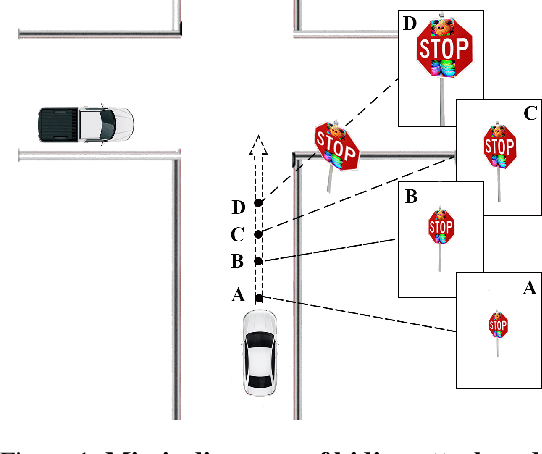

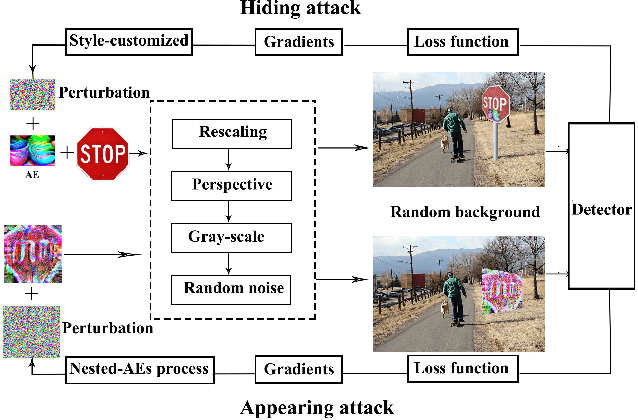

In this paper, we proposed the first practical adversarial attacks against object detectors in realistic situations: the adversarial examples are placed in different angles and distances, especially in the long distance (over 20m) and wide angles 120 degree. To improve the robustness of adversarial examples, we proposed the nested adversarial examples and introduced the image transformation techniques. Transformation methods aim to simulate the variance factors such as distances, angles, illuminations, etc., in the physical world. Two kinds of attacks were implemented on YOLO V3, a state-of-the-art real-time object detector: hiding attack that fools the detector unable to recognize the object, and appearing attack that fools the detector to recognize the non-existent object. The adversarial examples are evaluated in three environments: indoor lab, outdoor environment, and the real road, and demonstrated to achieve the success rate up to 92.4% based on the distance range from 1m to 25m. In particular, the real road testing of hiding attack on a straight road and a crossing road produced the success rate of 75% and 64% respectively, and the appearing attack obtained the success rates of 63% and 81% respectively, which we believe, should catch the attention of the autonomous driving community.