 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Injection Attacks on Large Language Models
May 30, 2024Large Language Models (LLMs) such as ChatGPT and Llama-2 have become prevalent in real-world applications, exhibiting impressive text generation performance. LLMs are fundamentally developed from a scenario where the input data remains static and lacks a clear structure. To behave interactively over time, LLM-based chat systems must integrate additional contextual information (i.e., chat history) into their inputs, following a pre-defined structure. This paper identifies how such integration can expose LLMs to misleading context from untrusted sources and fail to differentiate between system and user inputs, allowing users to inject context. We present a systematic methodology for conducting context injection attacks aimed at eliciting disallowed responses by introducing fabricated context. This could lead to illegal actions, inappropriate content, or technology misuse. Our context fabrication strategies, acceptance elicitation and word anonymization, effectively create misleading contexts that can be structured with attacker-customized prompt templates, achieving injection through malicious user messages. Comprehensive evaluations on real-world LLMs such as ChatGPT and Llama-2 confirm the efficacy of the proposed attack with success rates reaching 97%. We also discuss potential countermeasures that can be adopted for attack detection and developing more secure models. Our findings provide insights into the challenges associated with the real-world deployment of LLMs for interactive and structured data scenarios.
MEA-Defender: A Robust Watermark against Model Extraction Attack
Jan 26, 2024Recently, numerous highly-valuable Deep Neural Networks (DNNs) have been trained using deep learning algorithms. To protect the Intellectual Property (IP) of the original owners over such DNN models, backdoor-based watermarks have been extensively studied. However, most of such watermarks fail upon model extraction attack, which utilizes input samples to query the target model and obtains the corresponding outputs, thus training a substitute model using such input-output pairs. In this paper, we propose a novel watermark to protect IP of DNN models against model extraction, named MEA-Defender. In particular, we obtain the watermark by combining two samples from two source classes in the input domain and design a watermark loss function that makes the output domain of the watermark within that of the main task samples. Since both the input domain and the output domain of our watermark are indispensable parts of those of the main task samples, the watermark will be extracted into the stolen model along with the main task during model extraction. We conduct extensive experiments on four model extraction attacks, using five datasets and six models trained based on supervised learning and self-supervised learning algorithms. The experimental results demonstrate that MEA-Defender is highly robust against different model extraction attacks, and various watermark removal/detection approaches.
A Novel Membership Inference Attack against Dynamic Neural Networks by Utilizing Policy Networks Information
Oct 17, 2022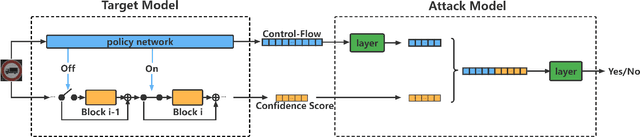
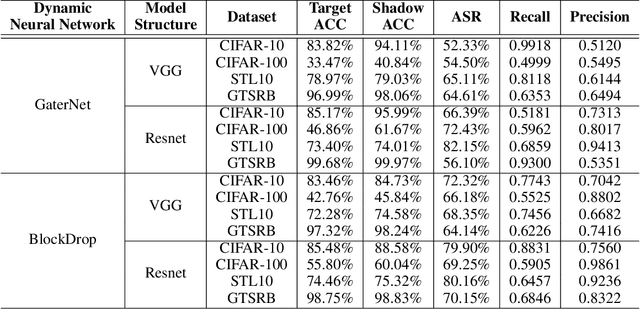
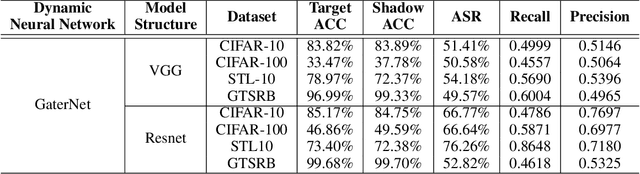

Unlike traditional static deep neural networks (DNNs), dynamic neural networks (NNs) adjust their structures or parameters to different inputs to guarantee accuracy and computational efficiency. Meanwhile, it has been an emerging research area in deep learning recently. Although traditional static DNNs are vulnerable to the membership inference attack (MIA) , which aims to infer whether a particular point was used to train the model, little is known about how such an attack performs on the dynamic NNs. In this paper, we propose a novel MI attack against dynamic NNs, leveraging the unique policy networks mechanism of dynamic NNs to increase the effectiveness of membership inference. We conducted extensive experiments using two dynamic NNs, i.e., GaterNet, BlockDrop, on four mainstream image classification tasks, i.e., CIFAR-10, CIFAR-100, STL-10, and GTSRB. The evaluation results demonstrate that the control-flow information can significantly promote the MIA. Based on backbone-finetuning and information-fusion, our method achieves better results than baseline attack and traditional attack using intermediate information.
SSL-WM: A Black-Box Watermarking Approach for Encoders Pre-trained by Self-supervised Learning
Sep 08, 2022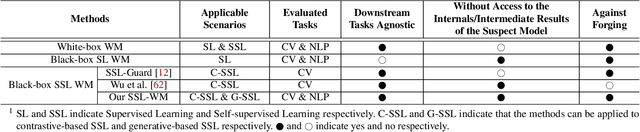
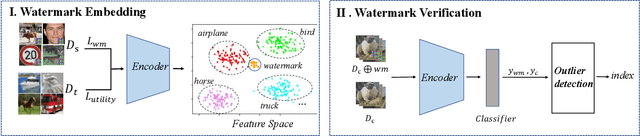

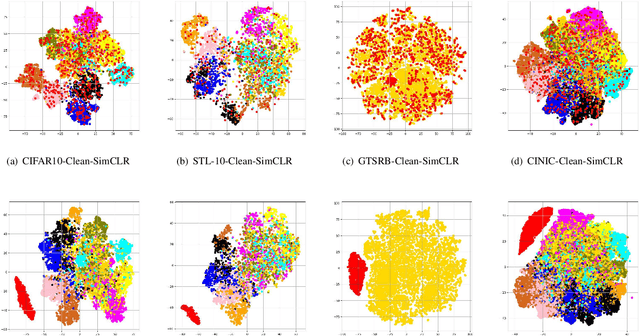
Recent years have witnessed significant success in Self-Supervised Learning (SSL), which facilitates various downstream tasks. However, attackers may steal such SSL models and commercialize them for profit, making it crucial to protect their Intellectual Property (IP). Most existing IP protection solutions are designed for supervised learning models and cannot be used directly since they require that the models' downstream tasks and target labels be known and available during watermark embedding, which is not always possible in the domain of SSL. To address such a problem especially when downstream tasks are diverse and unknown during watermark embedding, we propose a novel black-box watermarking solution, named SSL-WM, for protecting the ownership of SSL models. SSL-WM maps watermarked inputs by the watermarked encoders into an invariant representation space, which causes any downstream classifiers to produce expected behavior, thus allowing the detection of embedded watermarks. We evaluate SSL-WM on numerous tasks, such as Computer Vision (CV) and Natural Language Processing (NLP), using different SSL models, including contrastive-based and generative-based. Experimental results demonstrate that SSL-WM can effectively verify the ownership of stolen SSL models in various downstream tasks. Furthermore, SSL-WM is robust against model fine-tuning and pruning attacks. Lastly, SSL-WM can also evade detection from evaluated watermark detection approaches, demonstrating its promising application in protecting the IP of SSL models.