 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoHarbor: Evaluating Personalized Emotional Support by Simulating the User's Internal World
Jan 04, 2026Current evaluation paradigms for emotional support conversations tend to reward generic empathetic responses, yet they fail to assess whether the support is genuinely personalized to users' unique psychological profiles and contextual needs. We introduce EmoHarbor, an automated evaluation framework that adopts a User-as-a-Judge paradigm by simulating the user's inner world. EmoHarbor employs a Chain-of-Agent architecture that decomposes users' internal processes into three specialized roles, enabling agents to interact with supporters and complete assessments in a manner similar to human users. We instantiate this benchmark using 100 real-world user profiles that cover a diverse range of personality traits and situations, and define 10 evaluation dimensions of personalized support quality. Comprehensive evaluation of 20 advanced LLMs on EmoHarbor reveals a critical insight: while these models excel at generating empathetic responses, they consistently fail to tailor support to individual user contexts. This finding reframes the central challenge, shifting research focus from merely enhancing generic empathy to developing truly user-aware emotional support. EmoHarbor provides a reproducible and scalable framework to guide the development and evaluation of more nuanced and user-aware emotional support systems.
HiSciBench: A Hierarchical Multi-disciplinary Benchmark for Scientific Intelligence from Reading to Discovery
Dec 28, 2025The rapid advancement of large language models (LLMs) and multimodal foundation models has sparked growing interest in their potential for scientific research. However, scientific intelligence encompasses a broad spectrum of abilities ranging from understanding fundamental knowledge to conducting creative discovery, and existing benchmarks remain fragmented. Most focus on narrow tasks and fail to reflect the hierarchical and multi-disciplinary nature of real scientific inquiry. We introduce \textbf{HiSciBench}, a hierarchical benchmark designed to evaluate foundation models across five levels that mirror the complete scientific workflow: \textit{Scientific Literacy} (L1), \textit{Literature Parsing} (L2), \textit{Literature-based Question Answering} (L3), \textit{Literature Review Generation} (L4), and \textit{Scientific Discovery} (L5). HiSciBench contains 8,735 carefully curated instances spanning six major scientific disciplines, including mathematics, physics, chemistry, biology, geography, and astronomy, and supports multimodal inputs including text, equations, figures, and tables, as well as cross-lingual evaluation. Unlike prior benchmarks that assess isolated abilities, HiSciBench provides an integrated, dependency-aware framework that enables detailed diagnosis of model capabilities across different stages of scientific reasoning. Comprehensive evaluations of leading models, including GPT-5, DeepSeek-R1, and several multimodal systems, reveal substantial performance gaps: while models achieve up to 69\% accuracy on basic literacy tasks, performance declines sharply to 25\% on discovery-level challenges. HiSciBench establishes a new standard for evaluating scientific Intelligence and offers actionable insights for developing models that are not only more capable but also more reliable. The benchmark will be publicly released to facilitate future research.
Single-to-mix Modality Alignment with Multimodal Large Language Model for Document Image Machine Translation
Jul 10, 2025Document Image Machine Translation (DIMT) aims to translate text within document images, facing generalization challenges due to limited training data and the complex interplay between visual and textual information. To address these challenges, we introduce M4Doc, a novel single-to-mix modality alignment framework leveraging Multimodal Large Language Models (MLLMs). M4Doc aligns an image-only encoder with the multimodal representations of an MLLM, pre-trained on large-scale document image datasets. This alignment enables a lightweight DIMT model to learn crucial visual-textual correlations during training. During inference, M4Doc bypasses the MLLM, maintaining computational efficiency while benefiting from its multimodal knowledge. Comprehensive experiments demonstrate substantial improvements in translation quality, especially in cross-domain generalization and challenging document image scenarios.
From Generic Empathy to Personalized Emotional Support: A Self-Evolution Framework for User Preference Alignment
May 22, 2025Effective emotional support hinges on understanding users' emotions and needs to provide meaningful comfort during multi-turn interactions. Large Language Models (LLMs) show great potential for expressing empathy; however, they often deliver generic and one-size-fits-all responses that fail to address users' specific needs. To tackle this issue, we propose a self-evolution framework designed to help LLMs improve their responses to better align with users' implicit preferences concerning user profiles (personalities), emotional states, and specific situations. Our framework consists of two distinct phases: \textit{(1)} \textit{Emotional Support Experience Acquisition}, where LLMs are fine-tuned on limited emotional support conversation data to provide basic support, and \textit{(2)} \textit{Self-Improvement for Personalized Emotional Support}, where LLMs leverage self-reflection and self-refinement to generate personalized responses. Through iterative direct preference optimization between the pre- and post-refined responses, our model generates responses that reflect a better understanding of the user's implicit preferences. Extensive experiments and evaluations demonstrate that our method significantly enhances the model's performance in emotional support, reducing unhelpful responses and minimizing discrepancies between user preferences and model outputs.
SweetieChat: A Strategy-Enhanced Role-playing Framework for Diverse Scenarios Handling Emotional Support Agent
Dec 11, 2024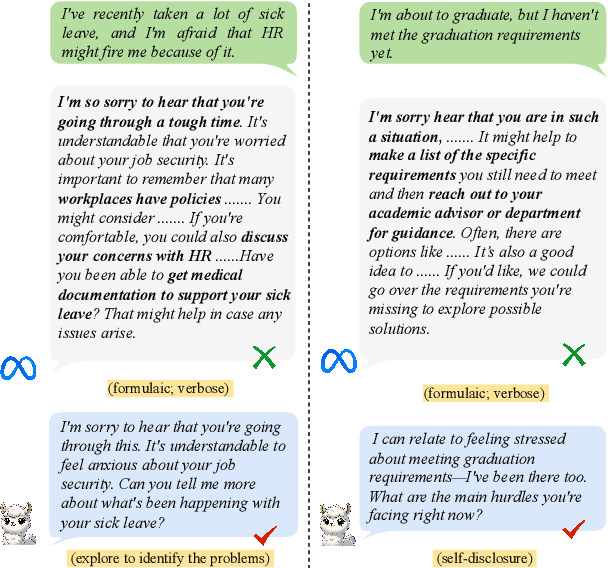
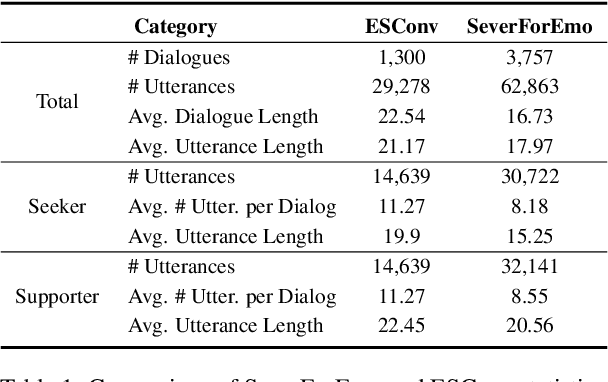
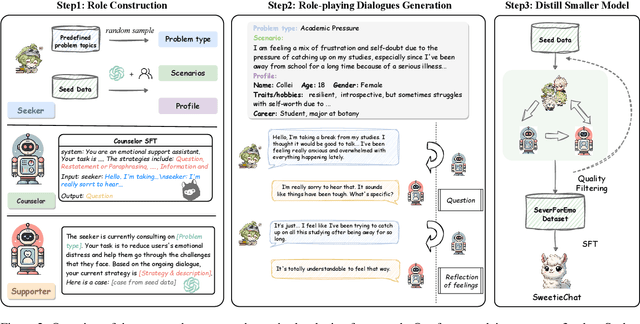
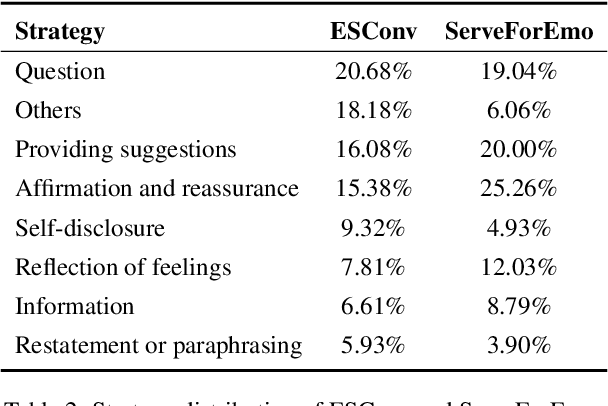
Large Language Models (LLMs) have demonstrated promising potential in providing empathetic support during interactions. However, their responses often become verbose or overly formulaic, failing to adequately address the diverse emotional support needs of real-world scenarios. To tackle this challenge, we propose an innovative strategy-enhanced role-playing framework, designed to simulate authentic emotional support conversations. Specifically, our approach unfolds in two steps: (1) Strategy-Enhanced Role-Playing Interactions, which involve three pivotal roles -- Seeker, Strategy Counselor, and Supporter -- engaging in diverse scenarios to emulate real-world interactions and promote a broader range of dialogues; and (2) Emotional Support Agent Training, achieved through fine-tuning LLMs using our specially constructed dataset. Within this framework, we develop the \textbf{ServeForEmo} dataset, comprising an extensive collection of 3.7K+ multi-turn dialogues and 62.8K+ utterances. We further present \textbf{SweetieChat}, an emotional support agent capable of handling diverse open-domain scenarios. Extensive experiments and human evaluations confirm the framework's effectiveness in enhancing emotional support, highlighting its unique ability to provide more nuanced and tailored assistance.
Context Injection Attacks on Large Language Models
May 30, 2024Large Language Models (LLMs) such as ChatGPT and Llama-2 have become prevalent in real-world applications, exhibiting impressive text generation performance. LLMs are fundamentally developed from a scenario where the input data remains static and lacks a clear structure. To behave interactively over time, LLM-based chat systems must integrate additional contextual information (i.e., chat history) into their inputs, following a pre-defined structure. This paper identifies how such integration can expose LLMs to misleading context from untrusted sources and fail to differentiate between system and user inputs, allowing users to inject context. We present a systematic methodology for conducting context injection attacks aimed at eliciting disallowed responses by introducing fabricated context. This could lead to illegal actions, inappropriate content, or technology misuse. Our context fabrication strategies, acceptance elicitation and word anonymization, effectively create misleading contexts that can be structured with attacker-customized prompt templates, achieving injection through malicious user messages. Comprehensive evaluations on real-world LLMs such as ChatGPT and Llama-2 confirm the efficacy of the proposed attack with success rates reaching 97%. We also discuss potential countermeasures that can be adopted for attack detection and developing more secure models. Our findings provide insights into the challenges associated with the real-world deployment of LLMs for interactive and structured data scenarios.
Life-long Learning for Multilingual Neural Machine Translation with Knowledge Distillation
Dec 06, 2022
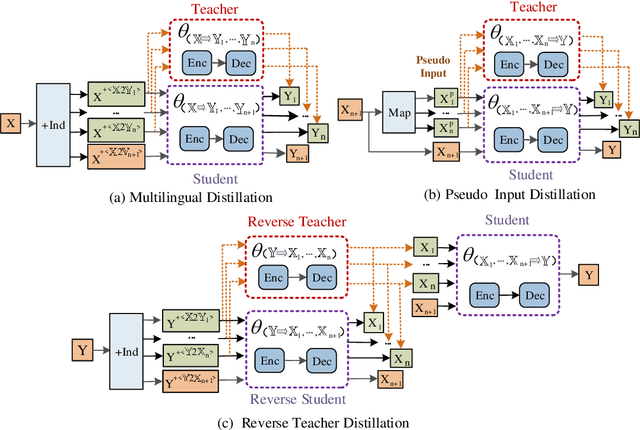
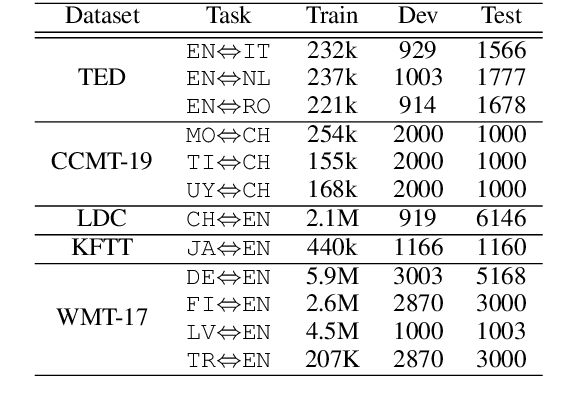
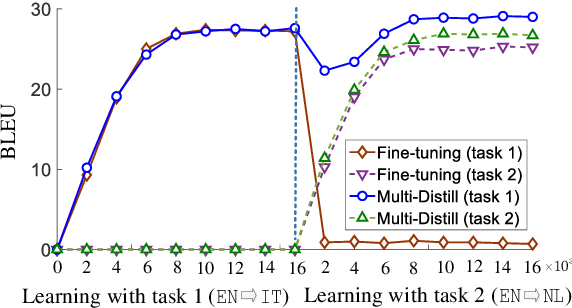
A common scenario of Multilingual Neural Machine Translation (MNMT) is that each translation task arrives in a sequential manner, and the training data of previous tasks is unavailable. In this scenario, the current methods suffer heavily from catastrophic forgetting (CF). To alleviate the CF, we investigate knowledge distillation based life-long learning methods. Specifically, in one-tomany scenario, we propose a multilingual distillation method to make the new model (student) jointly learn multilingual output from old model (teacher) and new task. In many-to one scenario, we find that direct distillation faces the extreme partial distillation problem, and we propose two different methods to address it: pseudo input distillation and reverse teacher distillation. The experimental results on twelve translation tasks show that the proposed methods can better consolidate the previous knowledge and sharply alleviate the CF.
Other Roles Matter! Enhancing Role-Oriented Dialogue Summarization via Role Interactions
May 26, 2022

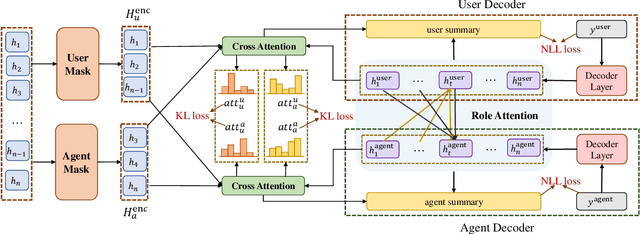

Role-oriented dialogue summarization is to generate summaries for different roles in the dialogue, e.g., merchants and consumers. Existing methods handle this task by summarizing each role's content separately and thus are prone to ignore the information from other roles. However, we believe that other roles' content could benefit the quality of summaries, such as the omitted information mentioned by other roles. Therefore, we propose a novel role interaction enhanced method for role-oriented dialogue summarization. It adopts cross attention and decoder self-attention interactions to interactively acquire other roles' critical information. The cross attention interaction aims to select other roles' critical dialogue utterances, while the decoder self-attention interaction aims to obtain key information from other roles' summaries. Experimental results have shown that our proposed method significantly outperforms strong baselines on two public role-oriented dialogue summarization datasets. Extensive analyses have demonstrated that other roles' content could help generate summaries with more complete semantics and correct topic structures.
CSDS: A Fine-Grained Chinese Dataset for Customer Service Dialogue Summarization
Sep 06, 2021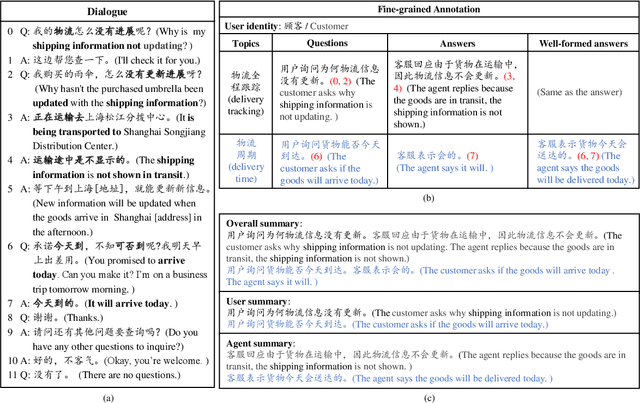
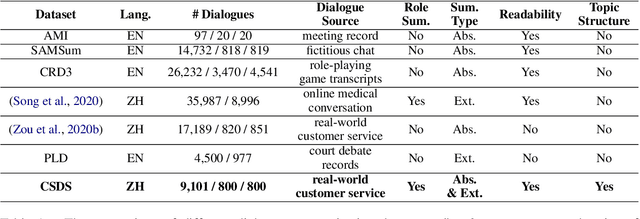
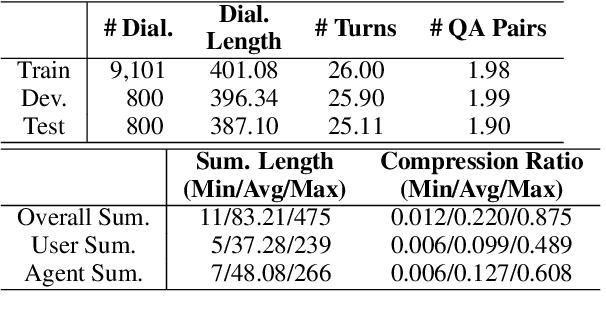
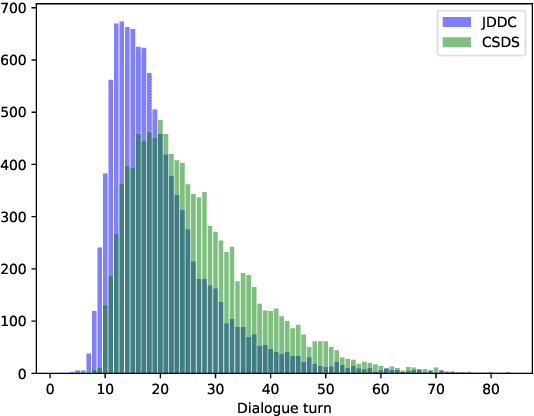
Dialogue summarization has drawn much attention recently. Especially in the customer service domain, agents could use dialogue summaries to help boost their works by quickly knowing customer's issues and service progress. These applications require summaries to contain the perspective of a single speaker and have a clear topic flow structure, while neither are available in existing datasets. Therefore, in this paper, we introduce a novel Chinese dataset for Customer Service Dialogue Summarization (CSDS). CSDS improves the abstractive summaries in two aspects: (1) In addition to the overall summary for the whole dialogue, role-oriented summaries are also provided to acquire different speakers' viewpoints. (2) All the summaries sum up each topic separately, thus containing the topic-level structure of the dialogue. We define tasks in CSDS as generating the overall summary and different role-oriented summaries for a given dialogue. Next, we compare various summarization methods on CSDS, and experiment results show that existing methods are prone to generate redundant and incoherent summaries. Besides, the performance becomes much worse when analyzing the performance on role-oriented summaries and topic structures. We hope that this study could benchmark Chinese dialogue summarization and benefit further studies.
Augmenting Slot Values and Contexts for Spoken Language Understanding with Pretrained Models
Aug 19, 2021


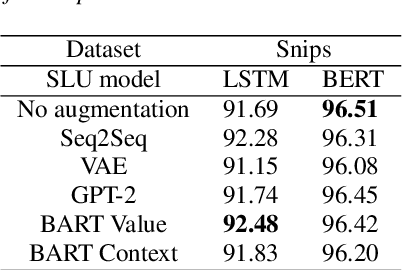
Spoken Language Understanding (SLU) is one essential step in building a dialogue system. Due to the expensive cost of obtaining the labeled data, SLU suffers from the data scarcity problem. Therefore, in this paper, we focus on data augmentation for slot filling task in SLU. To achieve that, we aim at generating more diverse data based on existing data. Specifically, we try to exploit the latent language knowledge from pretrained language models by finetuning them. We propose two strategies for finetuning process: value-based and context-based augmentation. Experimental results on two public SLU datasets have shown that compared with existing data augmentation methods, our proposed method can generate more diverse sentences and significantly improve the performance on SLU.