 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADSpotting: Robust Panoptic Symbol Spotting on Large-Scale CAD Drawings
Dec 10, 2024We introduce CADSpotting, an efficient method for panoptic symbol spotting in large-scale architectural CAD drawings. Existing approaches struggle with the diversity of symbols, scale variations, and overlapping elements in CAD designs. CADSpotting overcomes these challenges by representing each primitive with dense points instead of a single primitive point, described by essential attributes like coordinates and color. Building upon a unified 3D point cloud model for joint semantic, instance, and panoptic segmentation, CADSpotting learns robust feature representations. To enable accurate segmentation in large, complex drawings, we further propose a novel Sliding Window Aggregation (SWA) technique, combining weighted voting and Non-Maximum Suppression (NMS). Moreover, we introduce a large-scale CAD dataset named LS-CAD to support our experiments. Each floorplan in LS-CAD has an average coverage of 1,000 square meter(versus 100 square meter in the existing dataset), providing a valuable benchmark for symbol spotting research. Experimental results on FloorPlanCAD and LS-CAD datasets demonstrate that CADSpotting outperforms existing methods, showcasing its robustness and scalability for real-world CAD applications.
Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-time
Feb 22, 2022
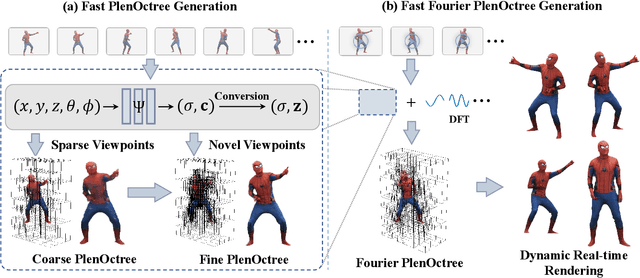

Implicit neural representations such as Neural Radiance Field (NeRF) have focused mainly on modeling static objects captured under multi-view settings where real-time rendering can be achieved with smart data structures, e.g., PlenOctree. In this paper, we present a novel Fourier PlenOctree (FPO) technique to tackle efficient neural modeling and real-time rendering of dynamic scenes captured under the free-view video (FVV) setting. The key idea in our FPO is a novel combination of generalized NeRF, PlenOctree representation, volumetric fusion and Fourier transform. To accelerate FPO construction, we present a novel coarse-to-fine fusion scheme that leverages the generalizable NeRF technique to generate the tree via spatial blending. To tackle dynamic scenes, we tailor the implicit network to model the Fourier coefficients of timevarying density and color attributes. Finally, we construct the FPO and train the Fourier coefficients directly on the leaves of a union PlenOctree structure of the dynamic sequence. We show that the resulting FPO enables compact memory overload to handle dynamic objects and supports efficient fine-tuning. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF and achieves over an order of magnitude acceleration over SOTA while preserving high visual quality for the free-viewpoint rendering of unseen dynamic scenes.
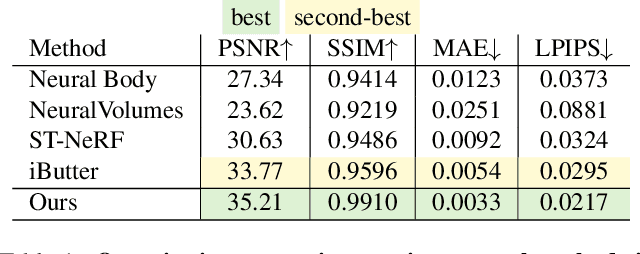
Editable Free-viewpoint Video Using a Layered Neural Representation
Apr 30, 2021
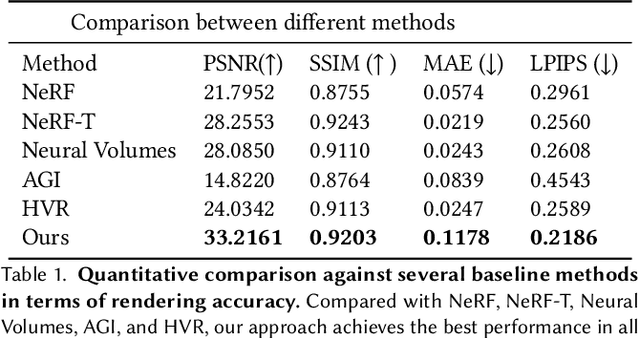
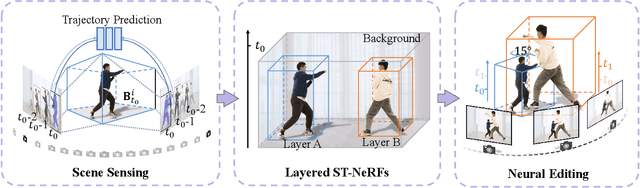
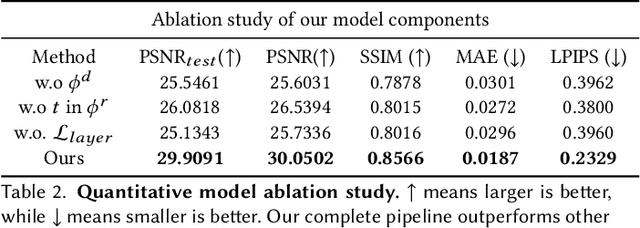
Generating free-viewpoint videos is critical for immersive VR/AR experience but recent neural advances still lack the editing ability to manipulate the visual perception for large dynamic scenes. To fill this gap, in this paper we propose the first approach for editable photo-realistic free-viewpoint video generation for large-scale dynamic scenes using only sparse 16 cameras. The core of our approach is a new layered neural representation, where each dynamic entity including the environment itself is formulated into a space-time coherent neural layered radiance representation called ST-NeRF. Such layered representation supports fully perception and realistic manipulation of the dynamic scene whilst still supporting a free viewing experience in a wide range. In our ST-NeRF, the dynamic entity/layer is represented as continuous functions, which achieves the disentanglement of location, deformation as well as the appearance of the dynamic entity in a continuous and self-supervised manner. We propose a scene parsing 4D label map tracking to disentangle the spatial information explicitly, and a continuous deform module to disentangle the temporal motion implicitly. An object-aware volume rendering scheme is further introduced for the re-assembling of all the neural layers. We adopt a novel layered loss and motion-aware ray sampling strategy to enable efficient training for a large dynamic scene with multiple performers, Our framework further enables a variety of editing functions, i.e., manipulating the scale and location, duplicating or retiming individual neural layers to create numerous visual effects while preserving high realism. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality, photo-realistic, and editable free-viewpoint video generation for dynamic scenes.