 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpec-Gloss Surfels and Normal-Diffuse Priors for Relightable Glossy Objects
Oct 02, 2025

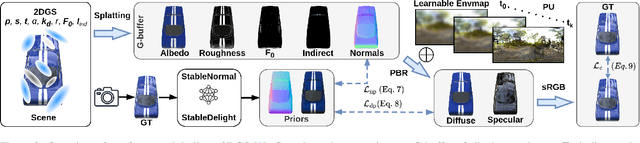

Accurate reconstruction and relighting of glossy objects remain a longstanding challenge, as object shape, material properties, and illumination are inherently difficult to disentangle. Existing neural rendering approaches often rely on simplified BRDF models or parameterizations that couple diffuse and specular components, which restricts faithful material recovery and limits relighting fidelity. We propose a relightable framework that integrates a microfacet BRDF with the specular-glossiness parameterization into 2D Gaussian Splatting with deferred shading. This formulation enables more physically consistent material decomposition, while diffusion-based priors for surface normals and diffuse color guide early-stage optimization and mitigate ambiguity. A coarse-to-fine optimization of the environment map accelerates convergence and preserves high-dynamic-range specular reflections. Extensive experiments on complex, glossy scenes demonstrate that our method achieves high-quality geometry and material reconstruction, delivering substantially more realistic and consistent relighting under novel illumination compared to existing Gaussian splatting methods.
RGS-DR: Reflective Gaussian Surfels with Deferred Rendering for Shiny Objects
Apr 28, 2025We introduce RGS-DR, a novel inverse rendering method for reconstructing and rendering glossy and reflective objects with support for flexible relighting and scene editing. Unlike existing methods (e.g., NeRF and 3D Gaussian Splatting), which struggle with view-dependent effects, RGS-DR utilizes a 2D Gaussian surfel representation to accurately estimate geometry and surface normals, an essential property for high-quality inverse rendering. Our approach explicitly models geometric and material properties through learnable primitives rasterized into a deferred shading pipeline, effectively reducing rendering artifacts and preserving sharp reflections. By employing a multi-level cube mipmap, RGS-DR accurately approximates environment lighting integrals, facilitating high-quality reconstruction and relighting. A residual pass with spherical-mipmap-based directional encoding further refines the appearance modeling. Experiments demonstrate that RGS-DR achieves high-quality reconstruction and rendering quality for shiny objects, often outperforming reconstruction-exclusive state-of-the-art methods incapable of relighting.
BG-Triangle: Bézier Gaussian Triangle for 3D Vectorization and Rendering
Mar 18, 2025Differentiable rendering enables efficient optimization by allowing gradients to be computed through the rendering process, facilitating 3D reconstruction, inverse rendering and neural scene representation learning. To ensure differentiability, existing solutions approximate or re-formulate traditional rendering operations using smooth, probabilistic proxies such as volumes or Gaussian primitives. Consequently, they struggle to preserve sharp edges due to the lack of explicit boundary definitions. We present a novel hybrid representation, B\'ezier Gaussian Triangle (BG-Triangle), that combines B\'ezier triangle-based vector graphics primitives with Gaussian-based probabilistic models, to maintain accurate shape modeling while conducting resolution-independent differentiable rendering. We present a robust and effective discontinuity-aware rendering technique to reduce uncertainties at object boundaries. We also employ an adaptive densification and pruning scheme for efficient training while reliably handling level-of-detail (LoD) variations. Experiments show that BG-Triangle achieves comparable rendering quality as 3DGS but with superior boundary preservation. More importantly, BG-Triangle uses a much smaller number of primitives than its alternatives, showcasing the benefits of vectorized graphics primitives and the potential to bridge the gap between classic and emerging representations.
Navigating the Nuances: A Fine-grained Evaluation of Vision-Language Navigation
Sep 25, 2024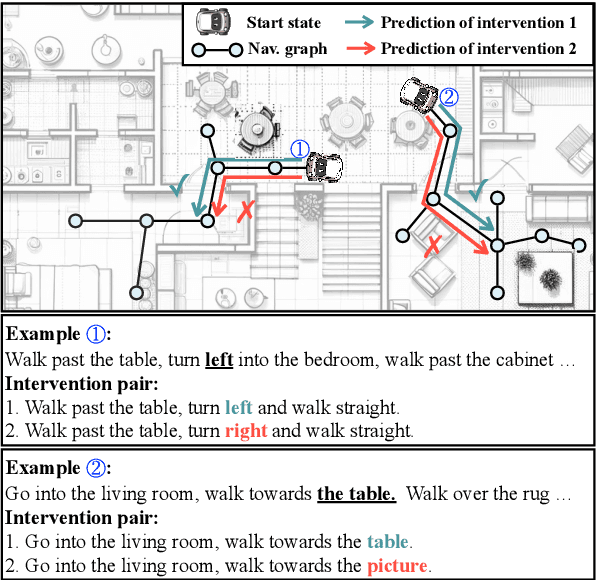
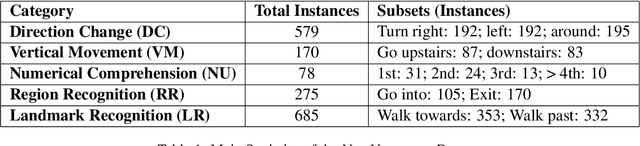

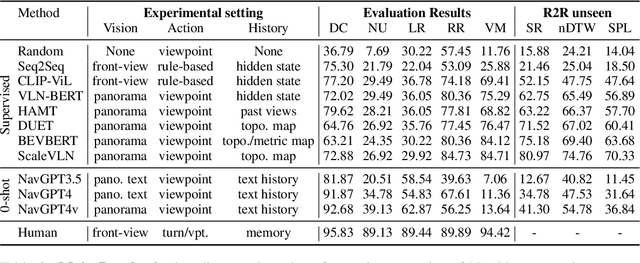
This study presents a novel evaluation framework for the Vision-Language Navigation (VLN) task. It aims to diagnose current models for various instruction categories at a finer-grained level. The framework is structured around the context-free grammar (CFG) of the task. The CFG serves as the basis for the problem decomposition and the core premise of the instruction categories design. We propose a semi-automatic method for CFG construction with the help of Large-Language Models (LLMs). Then, we induct and generate data spanning five principal instruction categories (i.e. direction change, landmark recognition, region recognition, vertical movement, and numerical comprehension). Our analysis of different models reveals notable performance discrepancies and recurrent issues. The stagnation of numerical comprehension, heavy selective biases over directional concepts, and other interesting findings contribute to the development of future language-guided navigation systems.
Redundancy-Aware Camera Selection for Indoor Scene Neural Rendering
Sep 11, 2024Novel view synthesis of indoor scenes can be achieved by capturing a monocular video sequence of the environment. However, redundant information caused by artificial movements in the input video data reduces the efficiency of scene modeling. In this work, we tackle this challenge from the perspective of camera selection. We begin by constructing a similarity matrix that incorporates both the spatial diversity of the cameras and the semantic variation of the images. Based on this matrix, we use the Intra-List Diversity (ILD) metric to assess camera redundancy, formulating the camera selection task as an optimization problem. Then we apply a diversity-based sampling algorithm to optimize the camera selection. We also develop a new dataset, IndoorTraj, which includes long and complex camera movements captured by humans in virtual indoor environments, closely mimicking real-world scenarios. Experimental results demonstrate that our strategy outperforms other approaches under time and memory constraints. Remarkably, our method achieves performance comparable to models trained on the full dataset, while using only an average of 15% of the frames and 75% of the allotted time.
Implicit Gaussian Splatting with Efficient Multi-Level Tri-Plane Representation
Aug 19, 2024Recent advancements in photo-realistic novel view synthesis have been significantly driven by Gaussian Splatting (3DGS). Nevertheless, the explicit nature of 3DGS data entails considerable storage requirements, highlighting a pressing need for more efficient data representations. To address this, we present Implicit Gaussian Splatting (IGS), an innovative hybrid model that integrates explicit point clouds with implicit feature embeddings through a multi-level tri-plane architecture. This architecture features 2D feature grids at various resolutions across different levels, facilitating continuous spatial domain representation and enhancing spatial correlations among Gaussian primitives. Building upon this foundation, we introduce a level-based progressive training scheme, which incorporates explicit spatial regularization. This method capitalizes on spatial correlations to enhance both the rendering quality and the compactness of the IGS representation. Furthermore, we propose a novel compression pipeline tailored for both point clouds and 2D feature grids, considering the entropy variations across different levels. Extensive experimental evaluations demonstrate that our algorithm can deliver high-quality rendering using only a few MBs, effectively balancing storage efficiency and rendering fidelity, and yielding results that are competitive with the state-of-the-art.
Unveiling the Ambiguity in Neural Inverse Rendering: A Parameter Compensation Analysis
Apr 19, 2024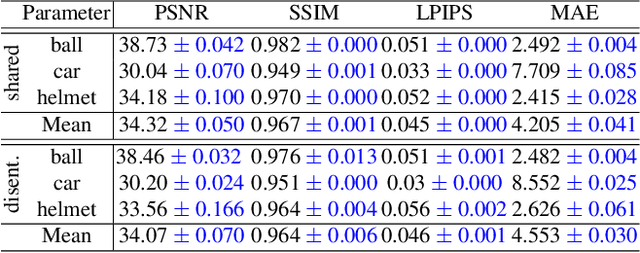

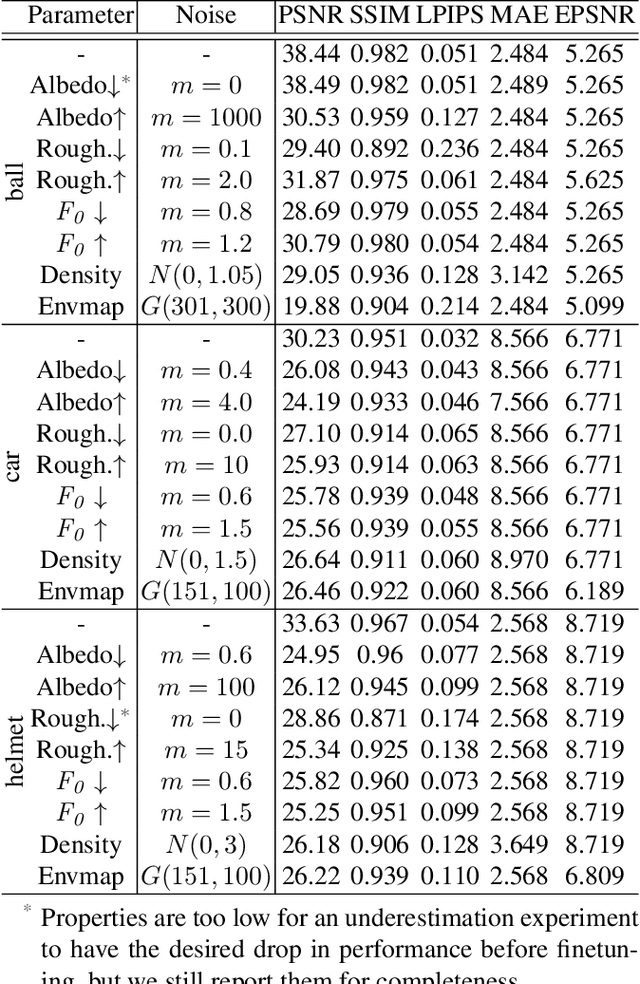
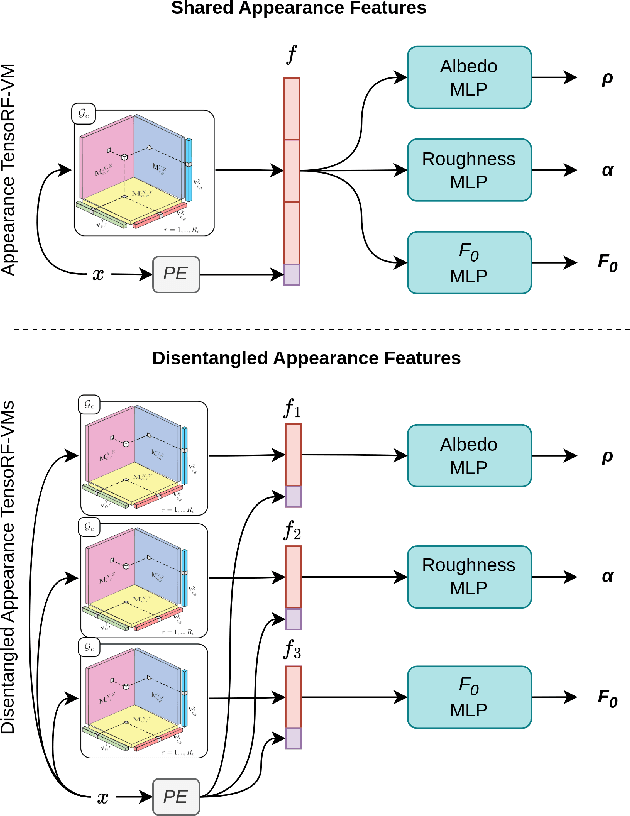
Inverse rendering aims to reconstruct the scene properties of objects solely from multiview images. However, it is an ill-posed problem prone to producing ambiguous estimations deviating from physically accurate representations. In this paper, we utilize Neural Microfacet Fields (NMF), a state-of-the-art neural inverse rendering method to illustrate the inherent ambiguity. We propose an evaluation framework to assess the degree of compensation or interaction between the estimated scene properties, aiming to explore the mechanisms behind this ill-posed problem and potential mitigation strategies. Specifically, we introduce artificial perturbations to one scene property and examine how adjusting another property can compensate for these perturbations. To facilitate such experiments, we introduce a disentangled NMF where material properties are independent. The experimental findings underscore the intrinsic ambiguity present in neural inverse rendering and highlight the importance of providing additional guidance through geometry, material, and illumination priors.
TeTriRF: Temporal Tri-Plane Radiance Fields for Efficient Free-Viewpoint Video
Dec 10, 2023Neural Radiance Fields (NeRF) revolutionize the realm of visual media by providing photorealistic Free-Viewpoint Video (FVV) experiences, offering viewers unparalleled immersion and interactivity. However, the technology's significant storage requirements and the computational complexity involved in generation and rendering currently limit its broader application. To close this gap, this paper presents Temporal Tri-Plane Radiance Fields (TeTriRF), a novel technology that significantly reduces the storage size for Free-Viewpoint Video (FVV) while maintaining low-cost generation and rendering. TeTriRF introduces a hybrid representation with tri-planes and voxel grids to support scaling up to long-duration sequences and scenes with complex motions or rapid changes. We propose a group training scheme tailored to achieving high training efficiency and yielding temporally consistent, low-entropy scene representations. Leveraging these properties of the representations, we introduce a compression pipeline with off-the-shelf video codecs, achieving an order of magnitude less storage size compared to the state-of-the-art. Our experiments demonstrate that TeTriRF can achieve competitive quality with a higher compression rate.
NeVRF: Neural Video-based Radiance Fields for Long-duration Sequences
Dec 10, 2023Adopting Neural Radiance Fields (NeRF) to long-duration dynamic sequences has been challenging. Existing methods struggle to balance between quality and storage size and encounter difficulties with complex scene changes such as topological changes and large motions. To tackle these issues, we propose a novel neural video-based radiance fields (NeVRF) representation. NeVRF marries neural radiance field with image-based rendering to support photo-realistic novel view synthesis on long-duration dynamic inward-looking scenes. We introduce a novel multi-view radiance blending approach to predict radiance directly from multi-view videos. By incorporating continual learning techniques, NeVRF can efficiently reconstruct frames from sequential data without revisiting previous frames, enabling long-duration free-viewpoint video. Furthermore, with a tailored compression approach, NeVRF can compactly represent dynamic scenes, making dynamic radiance fields more practical in real-world scenarios. Our extensive experiments demonstrate the effectiveness of NeVRF in enabling long-duration sequence rendering, sequential data reconstruction, and compact data storage.
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
Dec 03, 2023



Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.