 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Ambiguity in Neural Inverse Rendering: A Parameter Compensation Analysis
Apr 19, 2024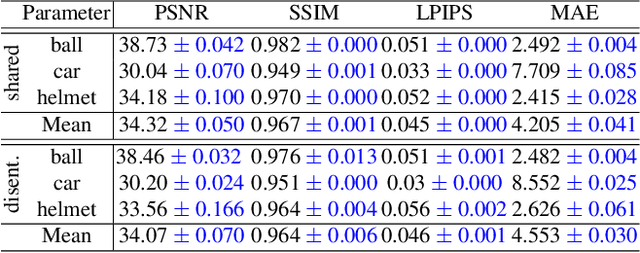

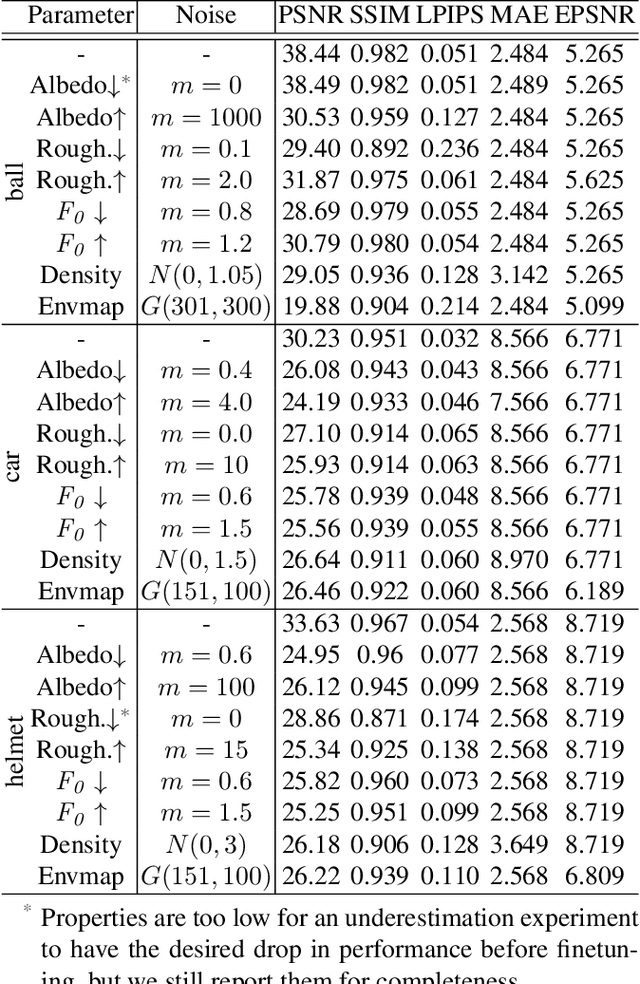
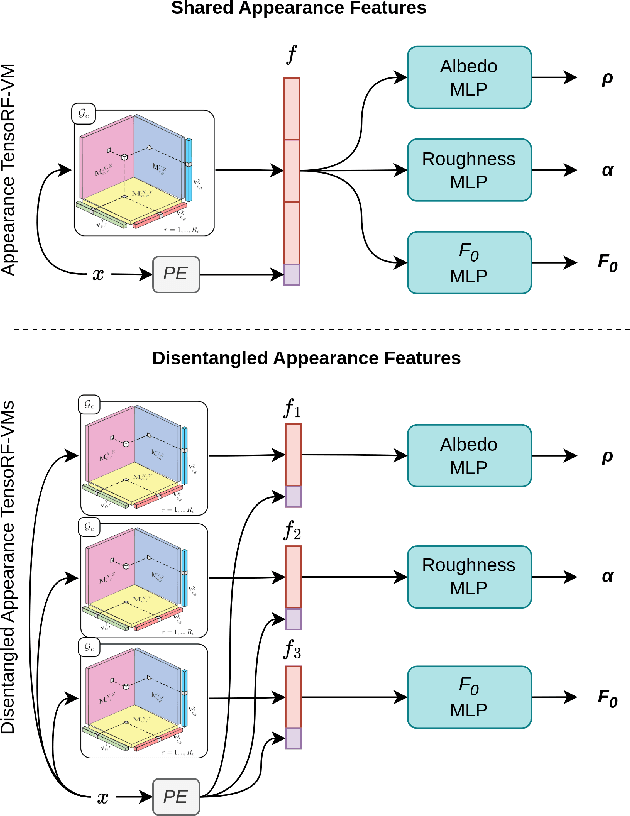
Inverse rendering aims to reconstruct the scene properties of objects solely from multiview images. However, it is an ill-posed problem prone to producing ambiguous estimations deviating from physically accurate representations. In this paper, we utilize Neural Microfacet Fields (NMF), a state-of-the-art neural inverse rendering method to illustrate the inherent ambiguity. We propose an evaluation framework to assess the degree of compensation or interaction between the estimated scene properties, aiming to explore the mechanisms behind this ill-posed problem and potential mitigation strategies. Specifically, we introduce artificial perturbations to one scene property and examine how adjusting another property can compensate for these perturbations. To facilitate such experiments, we introduce a disentangled NMF where material properties are independent. The experimental findings underscore the intrinsic ambiguity present in neural inverse rendering and highlight the importance of providing additional guidance through geometry, material, and illumination priors.
RGB-X Object Detection via Scene-Specific Fusion Modules
Oct 30, 2023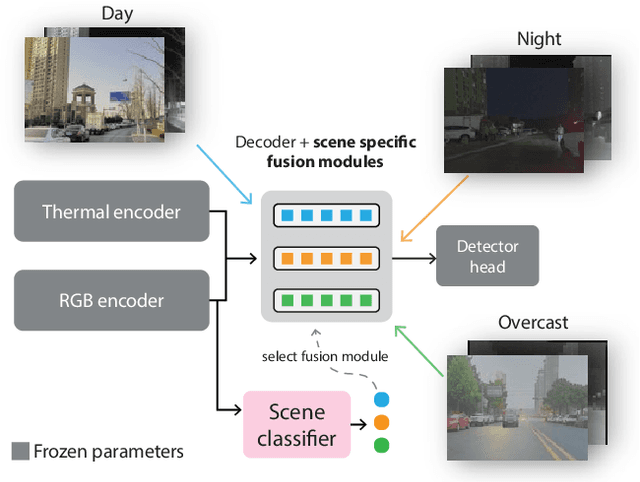

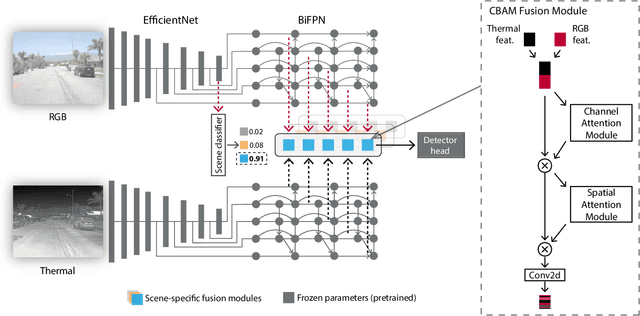
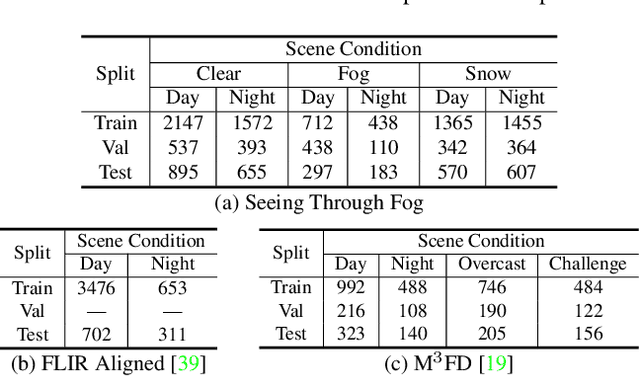
Multimodal deep sensor fusion has the potential to enable autonomous vehicles to visually understand their surrounding environments in all weather conditions. However, existing deep sensor fusion methods usually employ convoluted architectures with intermingled multimodal features, requiring large coregistered multimodal datasets for training. In this work, we present an efficient and modular RGB-X fusion network that can leverage and fuse pretrained single-modal models via scene-specific fusion modules, thereby enabling joint input-adaptive network architectures to be created using small, coregistered multimodal datasets. Our experiments demonstrate the superiority of our method compared to existing works on RGB-thermal and RGB-gated datasets, performing fusion using only a small amount of additional parameters. Our code is available at https://github.com/dsriaditya999/RGBXFusion.
DatasetEquity: Are All Samples Created Equal? In The Quest For Equity Within Datasets
Aug 22, 2023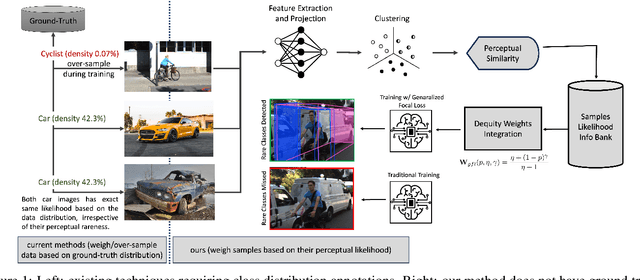

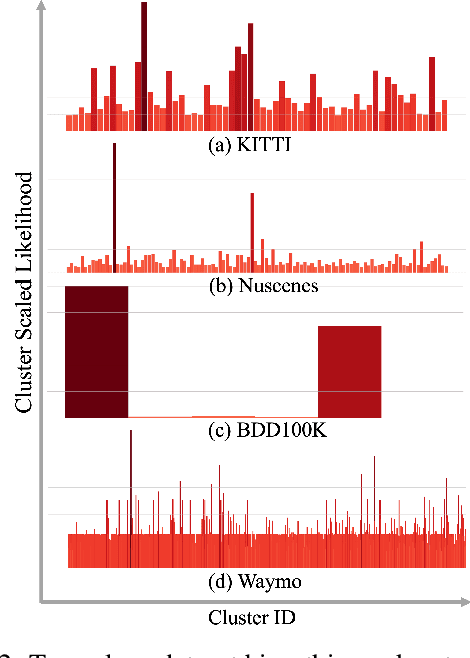
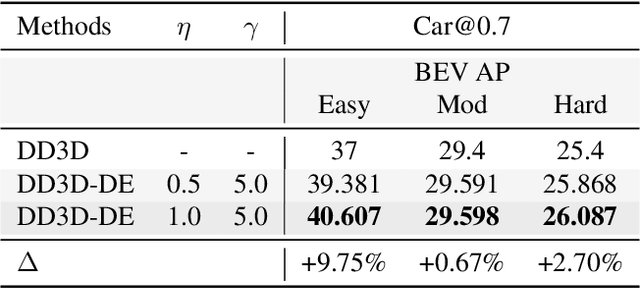
Data imbalance is a well-known issue in the field of machine learning, attributable to the cost of data collection, the difficulty of labeling, and the geographical distribution of the data. In computer vision, bias in data distribution caused by image appearance remains highly unexplored. Compared to categorical distributions using class labels, image appearance reveals complex relationships between objects beyond what class labels provide. Clustering deep perceptual features extracted from raw pixels gives a richer representation of the data. This paper presents a novel method for addressing data imbalance in machine learning. The method computes sample likelihoods based on image appearance using deep perceptual embeddings and clustering. It then uses these likelihoods to weigh samples differently during training with a proposed $\textbf{Generalized Focal Loss}$ function. This loss can be easily integrated with deep learning algorithms. Experiments validate the method's effectiveness across autonomous driving vision datasets including KITTI and nuScenes. The loss function improves state-of-the-art 3D object detection methods, achieving over $200\%$ AP gains on under-represented classes (Cyclist) in the KITTI dataset. The results demonstrate the method is generalizable, complements existing techniques, and is particularly beneficial for smaller datasets and rare classes. Code is available at: https://github.com/towardsautonomy/DatasetEquity
Ref-DVGO: Reflection-Aware Direct Voxel Grid Optimization for an Improved Quality-Efficiency Trade-Off in Reflective Scene Reconstruction
Aug 21, 2023



Neural Radiance Fields (NeRFs) have revolutionized the field of novel view synthesis, demonstrating remarkable performance. However, the modeling and rendering of reflective objects remain challenging problems. Recent methods have shown significant improvements over the baselines in handling reflective scenes, albeit at the expense of efficiency. In this work, we aim to strike a balance between efficiency and quality. To this end, we investigate an implicit-explicit approach based on conventional volume rendering to enhance the reconstruction quality and accelerate the training and rendering processes. We adopt an efficient density-based grid representation and reparameterize the reflected radiance in our pipeline. Our proposed reflection-aware approach achieves a competitive quality efficiency trade-off compared to competing methods. Based on our experimental results, we propose and discuss hypotheses regarding the factors influencing the results of density-based methods for reconstructing reflective objects. The source code is available at https://github.com/gkouros/ref-dvgo.
Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation
Aug 16, 2022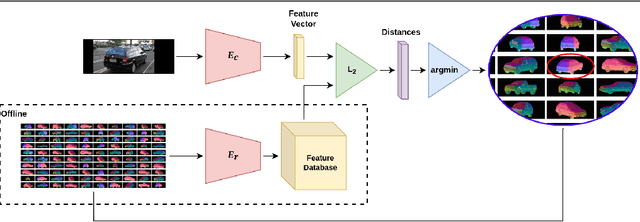
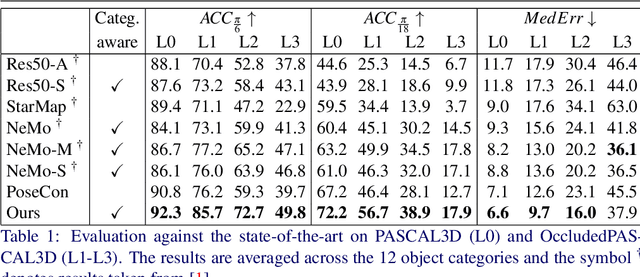
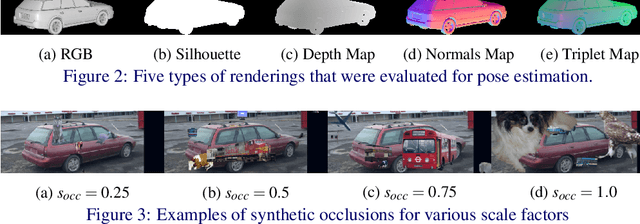
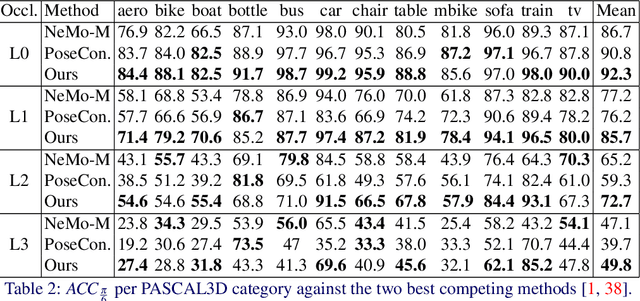
Pose estimation is usually tackled as either a bin classification problem or as a regression problem. In both cases, the idea is to directly predict the pose of an object. This is a non-trivial task because of appearance variations of similar poses and similarities between different poses. Instead, we follow the key idea that it is easier to compare two poses than to estimate them. Render-and-compare approaches have been employed to that end, however, they tend to be unstable, computationally expensive, and slow for real-time applications. We propose doing category-level pose estimation by learning an alignment metric using a contrastive loss with a dynamic margin and a continuous pose-label space. For efficient inference, we use a simple real-time image retrieval scheme with a reference set of renderings projected to an embedding space. To achieve robustness to real-world conditions, we employ synthetic occlusions, bounding box perturbations, and appearance augmentations. Our approach achieves state-of-the-art performance on PASCAL3D and OccludedPASCAL3D, as well as high-quality results on KITTI3D.
Look Both Ways: Bidirectional Visual Sensing for Automatic Multi-Camera Registration
Aug 15, 2022



This work describes the automatic registration of a large network (approximately 40) of fixed, ceiling-mounted environment cameras spread over a large area (approximately 800 squared meters) using a mobile calibration robot equipped with a single upward-facing fisheye camera and a backlit ArUco marker for easy detection. The fisheye camera is used to do visual odometry (VO), and the ArUco marker facilitates easy detection of the calibration robot in the environment cameras. In addition, the fisheye camera is also able to detect the environment cameras. This two-way, bidirectional detection constrains the pose of the environment cameras to solve an optimization problem. Such an approach can be used to automatically register a large-scale multi-camera system used for surveillance, automated parking, or robotic applications. This VO based multicamera registration method is extensively validated using real-world experiments, and also compared against a similar approach which uses an LiDAR - an expensive, heavier and power hungry sensor.
Domain Adaptation for Object Detection using SE Adaptors and Center Loss
May 25, 2022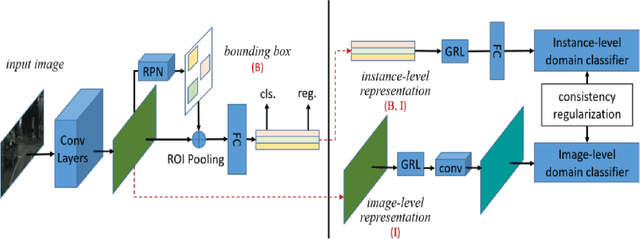
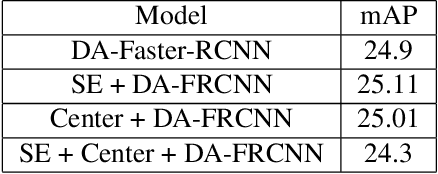
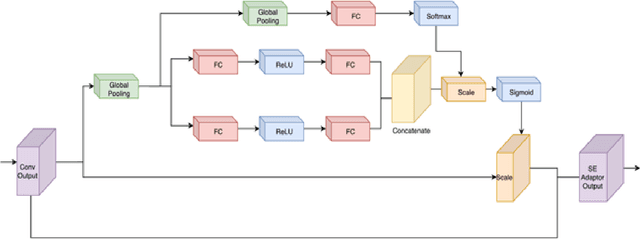
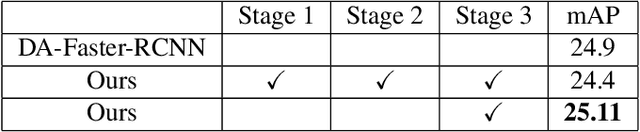
Despite growing interest in object detection, very few works address the extremely practical problem of cross-domain robustness especially for automative applications. In order to prevent drops in performance due to domain shift, we introduce an unsupervised domain adaptation method built on the foundation of faster-RCNN with two domain adaptation components addressing the shift at the instance and image levels respectively and apply a consistency regularization between them. We also introduce a family of adaptation layers that leverage the squeeze excitation mechanism called SE Adaptors to improve domain attention and thus improves performance without any prior requirement of knowledge of the new target domain. Finally, we incorporate a center loss in the instance and image level representations to improve the intra-class variance. We report all results with Cityscapes as our source domain and Foggy Cityscapes as the target domain outperforming previous baselines.
Structure Aware and Class Balanced 3D Object Detection on nuScenes Dataset
May 25, 20223-D object detection is pivotal for autonomous driving. Point cloud based methods have become increasingly popular for 3-D object detection, owing to their accurate depth information. NuTonomy's nuScenes dataset greatly extends commonly used datasets such as KITTI in size, sensor modalities, categories, and annotation numbers. However, it suffers from severe class imbalance. The Class-balanced Grouping and Sampling paper addresses this issue and suggests augmentation and sampling strategy. However, the localization precision of this model is affected by the loss of spatial information in the downscaled feature maps. We propose to enhance the performance of the CBGS model by designing an auxiliary network, that makes full use of the structure information of the 3D point cloud, in order to improve the localization accuracy. The detachable auxiliary network is jointly optimized by two point-level supervisions, namely foreground segmentation and center estimation. The auxiliary network does not introduce any extra computation during inference, since it can be detached at test time.