 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces
Nov 10, 2025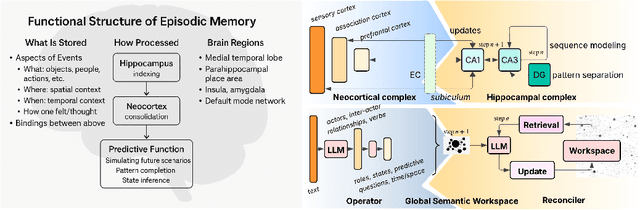
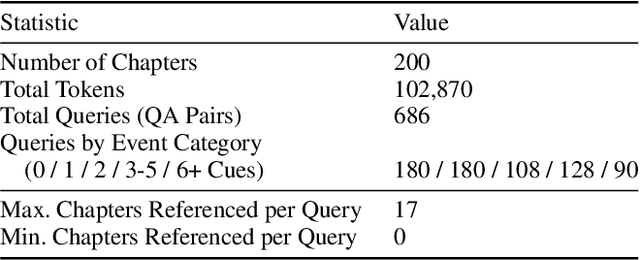
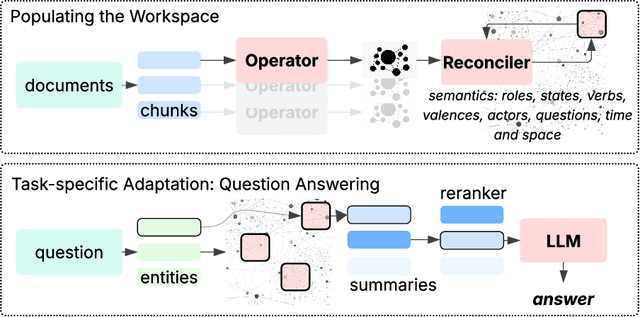
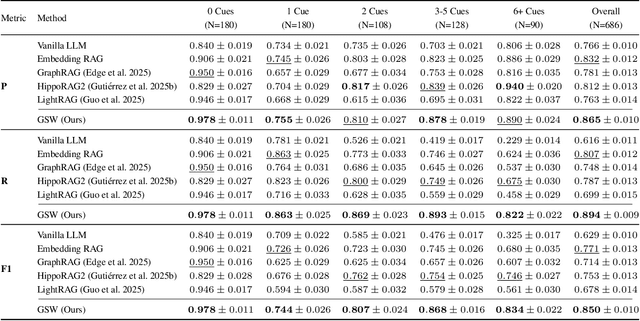
Large Language Models (LLMs) face fundamental challenges in long-context reasoning: many documents exceed their finite context windows, while performance on texts that do fit degrades with sequence length, necessitating their augmentation with external memory frameworks. Current solutions, which have evolved from retrieval using semantic embeddings to more sophisticated structured knowledge graphs representations for improved sense-making and associativity, are tailored for fact-based retrieval and fail to build the space-time-anchored narrative representations required for tracking entities through episodic events. To bridge this gap, we propose the \textbf{Generative Semantic Workspace} (GSW), a neuro-inspired generative memory framework that builds structured, interpretable representations of evolving situations, enabling LLMs to reason over evolving roles, actions, and spatiotemporal contexts. Our framework comprises an \textit{Operator}, which maps incoming observations to intermediate semantic structures, and a \textit{Reconciler}, which integrates these into a persistent workspace that enforces temporal, spatial, and logical coherence. On the Episodic Memory Benchmark (EpBench) \cite{huet_episodic_2025} comprising corpora ranging from 100k to 1M tokens in length, GSW outperforms existing RAG based baselines by up to \textbf{20\%}. Furthermore, GSW is highly efficient, reducing query-time context tokens by \textbf{51\%} compared to the next most token-efficient baseline, reducing inference time costs considerably. More broadly, GSW offers a concrete blueprint for endowing LLMs with human-like episodic memory, paving the way for more capable agents that can reason over long horizons.
Explainable deep learning improves human mental models of self-driving cars
Nov 27, 2024Self-driving cars increasingly rely on deep neural networks to achieve human-like driving. However, the opacity of such black-box motion planners makes it challenging for the human behind the wheel to accurately anticipate when they will fail, with potentially catastrophic consequences. Here, we introduce concept-wrapper network (i.e., CW-Net), a method for explaining the behavior of black-box motion planners by grounding their reasoning in human-interpretable concepts. We deploy CW-Net on a real self-driving car and show that the resulting explanations refine the human driver's mental model of the car, allowing them to better predict its behavior and adjust their own behavior accordingly. Unlike previous work using toy domains or simulations, our study presents the first real-world demonstration of how to build authentic autonomous vehicles (AVs) that give interpretable, causally faithful explanations for their decisions, without sacrificing performance. We anticipate our method could be applied to other safety-critical systems with a human in the loop, such as autonomous drones and robotic surgeons. Overall, our study suggests a pathway to explainability for autonomous agents as a whole, which can help make them more transparent, their deployment safer, and their usage more ethical.
Creating an AI Observer: Generative Semantic Workspaces
Jun 07, 2024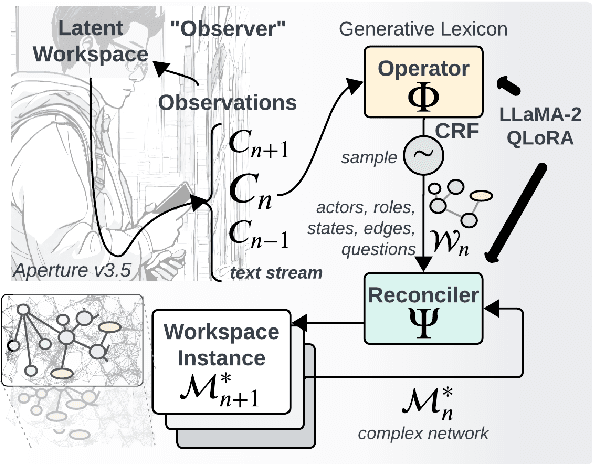
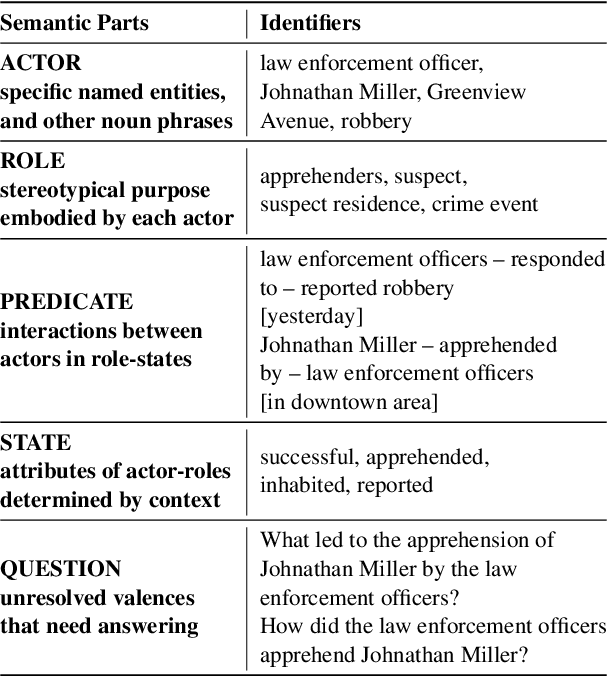
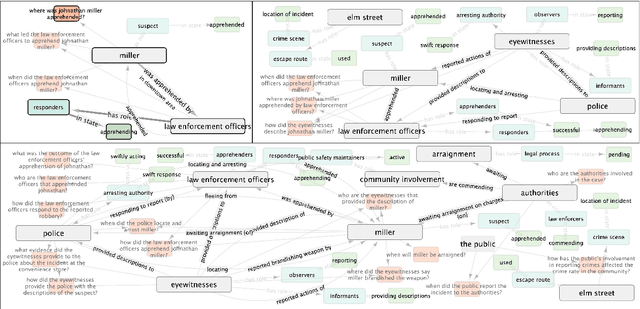
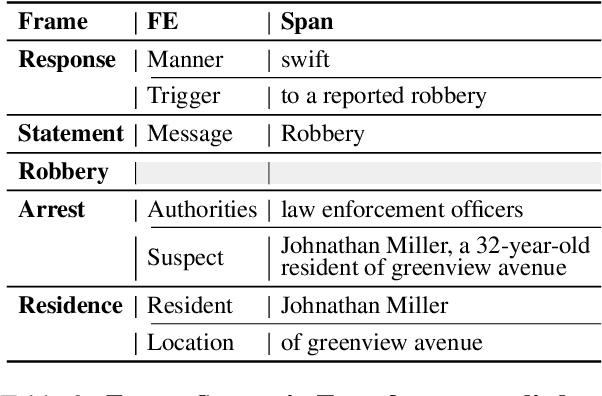
An experienced human Observer reading a document -- such as a crime report -- creates a succinct plot-like $\textit{``Working Memory''}$ comprising different actors, their prototypical roles and states at any point, their evolution over time based on their interactions, and even a map of missing Semantic parts anticipating them in the future. $\textit{An equivalent AI Observer currently does not exist}$. We introduce the $\textbf{[G]}$enerative $\textbf{[S]}$emantic $\textbf{[W]}$orkspace (GSW) -- comprising an $\textit{``Operator''}$ and a $\textit{``Reconciler''}$ -- that leverages advancements in LLMs to create a generative-style Semantic framework, as opposed to a traditionally predefined set of lexicon labels. Given a text segment $C_n$ that describes an ongoing situation, the $\textit{Operator}$ instantiates actor-centric Semantic maps (termed ``Workspace instance'' $\mathcal{W}_n$). The $\textit{Reconciler}$ resolves differences between $\mathcal{W}_n$ and a ``Working memory'' $\mathcal{M}_n^*$ to generate the updated $\mathcal{M}_{n+1}^*$. GSW outperforms well-known baselines on several tasks ($\sim 94\%$ vs. FST, GLEN, BertSRL - multi-sentence Semantics extraction, $\sim 15\%$ vs. NLI-BERT, $\sim 35\%$ vs. QA). By mirroring the real Observer, GSW provides the first step towards Spatial Computing assistants capable of understanding individual intentions and predicting future behavior.
Domain Adaptation for Object Detection using SE Adaptors and Center Loss
May 25, 2022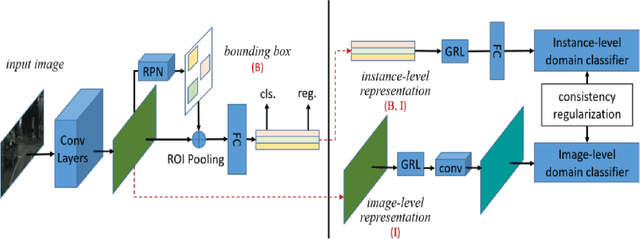
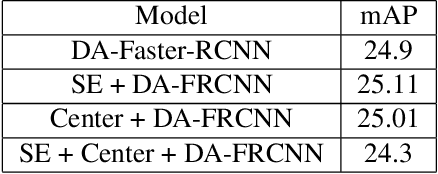
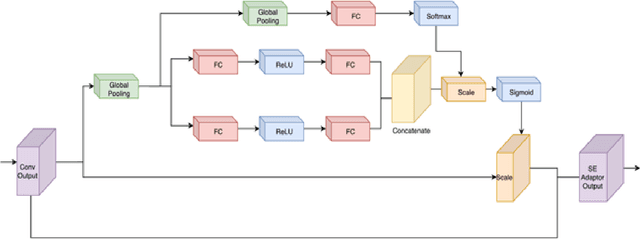
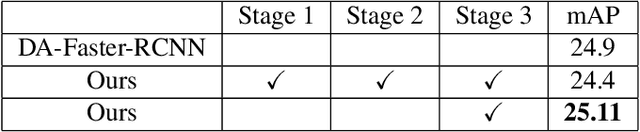
Despite growing interest in object detection, very few works address the extremely practical problem of cross-domain robustness especially for automative applications. In order to prevent drops in performance due to domain shift, we introduce an unsupervised domain adaptation method built on the foundation of faster-RCNN with two domain adaptation components addressing the shift at the instance and image levels respectively and apply a consistency regularization between them. We also introduce a family of adaptation layers that leverage the squeeze excitation mechanism called SE Adaptors to improve domain attention and thus improves performance without any prior requirement of knowledge of the new target domain. Finally, we incorporate a center loss in the instance and image level representations to improve the intra-class variance. We report all results with Cityscapes as our source domain and Foggy Cityscapes as the target domain outperforming previous baselines.