 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeizure-Semiology-Suite (S3): A Clinically Multimodal Dataset, Benchmark, and Models for Seizure Semiology Understanding
May 21, 2026While Multimodal Large Language Models (MLLMs) have demonstrated remarkable proficiency in general video understanding, their capacity to interpret involuntary, and spatio-temporally evolving pathologic motor behaviors such as seizure semiology remains largely untested. To address this gap, we introduce Seizure-Semiology-Suite, a clinically grounded dataset and benchmark for fine-grained, structured seizure semiology understanding. The dataset includes 438 seizure videos annotated with over 35,000 dense labels covering 20 ILAE-defined semiological features. Building on this dataset, we propose a seven-task hierarchical benchmark that systematically evaluates MLLMs from low-level visual perception to temporal sequencing, narrative report generation, and seizure diagnosis. To enable clinically meaningful evaluation of generated reports, we further introduce the Report Quality Index for Seizure Semiology (Seizure-RQI). Extensive baselines across 11 open-weight MLLMs reveal systematic weaknesses in laterality reasoning, temporal localization, symptom sequencing, and clinically faithful reporting. We show that seizure-specific fine-tuning substantially improves performance across tasks, and that a two-stage neuro-symbolic framework achieves an F1 score of 0.96 on epileptic versus non-epileptic seizure classification. Seizure-Semiology-Suite establishes a rigorous benchmark for evaluating multimodal models in safety-critical medical video understanding and guides the development of clinically reliable, domain-adaptive multimodal intelligence.
An Exterior Method for Nonnegative Matrix Factorization
May 19, 2026Nonnegative matrix factorization (NMF) seeks a low-rank approximation $X \approx UV^T$ with nonnegative factors and is commonly solved using interior methods that enforce feasibility throughout optimization. We show that such constraint-driven approaches can impede progress in the nonconvex landscape, leading to slow convergence or convergence to suboptimal stationary points. We propose an exterior framework for NMF (eNMF) that separates low-rank approximation from nonnegativity enforcement. Our method initializes from the optimal unconstrained factorization and introduces a rotation procedure that maps unconstrained factors to an exterior point closest to the nonnegative orthant. This viewpoint yields an algorithmic framework in which simple iterative updates converge to KKT-satisfying stationary points on the boundary of the positive orthant. The exterior formulation also enables a geometric interpretation of NMF solutions, clarifying equivalence classes of factorizations under permutation and orthogonal transformations. An intriguing numerical result, involving 400 NMF experiments across both real and synthetic datasets, show that in 99% of the cases, different algorithms tend to converge towards equivalent factor matrices. We benchmark eNMF against 9 state-of-the-art NMF algorithms with 9 initialization schemes across 3 real-world and 2 synthetic datasets. eNMF consistently outperforms all 81 competitors, achieving up to 30% lower reconstruction error under equal-time settings and up to 150% speedup under equal-error settings. The downstream experiments further demonstrate substantial performance gains in audio processing and recommendation tasks, corroborating the practical benefits of the proposed exterior optimization framework. Code is available at https://github.com/roychowdhuryresearch/eNMF
Phase transition on a context-sensitive random language model with short range interactions
Apr 01, 2026Since the random language model was proposed by E. DeGiuli [Phys. Rev. Lett. 122, 128301], language models have been investigated intensively from the viewpoint of statistical mechanics. Recently, the existence of a Berezinskii--Kosterlitz--Thouless transition was numerically demonstrated in models with long-range interactions between symbols. In statistical mechanics, it has long been known that long-range interactions can induce phase transitions. Therefore, it has remained unclear whether phase transitions observed in language models originate from genuinely linguistic properties that are absent in conventional spin models. In this study, we construct a random language model with short-range interactions and numerically investigate its statistical properties. Our model belongs to the class of context-sensitive grammars in the Chomsky hierarchy and allows explicit reference to contexts. We find that a phase transition occurs even when the model refers only to contexts whose length remains constant with respect to the sentence length. This result indicates that finite-temperature phase transitions in language models are genuinely induced by the intrinsic nature of language, rather than by long-range interactions.
Omni-iEEG: A Large-Scale, Comprehensive iEEG Dataset and Benchmark for Epilepsy Research
Feb 19, 2026Epilepsy affects over 50 million people worldwide, and one-third of patients suffer drug-resistant seizures where surgery offers the best chance of seizure freedom. Accurate localization of the epileptogenic zone (EZ) relies on intracranial EEG (iEEG). Clinical workflows, however, remain constrained by labor-intensive manual review. At the same time, existing data-driven approaches are typically developed on single-center datasets that are inconsistent in format and metadata, lack standardized benchmarks, and rarely release pathological event annotations, creating barriers to reproducibility, cross-center validation, and clinical relevance. With extensive efforts to reconcile heterogeneous iEEG formats, metadata, and recordings across publicly available sources, we present $\textbf{Omni-iEEG}$, a large-scale, pre-surgical iEEG resource comprising $\textbf{302 patients}$ and $\textbf{178 hours}$ of high-resolution recordings. The dataset includes harmonized clinical metadata such as seizure onset zones, resections, and surgical outcomes, all validated by board-certified epileptologists. In addition, Omni-iEEG provides over 36K expert-validated annotations of pathological events, enabling robust biomarker studies. Omni-iEEG serves as a bridge between machine learning and epilepsy research. It defines clinically meaningful tasks with unified evaluation metrics grounded in clinical priors, enabling systematic evaluation of models in clinically relevant settings. Beyond benchmarking, we demonstrate the potential of end-to-end modeling on long iEEG segments and highlight the transferability of representations pretrained on non-neurophysiological domains. Together, these contributions establish Omni-iEEG as a foundation for reproducible, generalizable, and clinically translatable epilepsy research. The project page with dataset and code links is available at omni-ieeg.github.io/omni-ieeg.
Panini: Continual Learning in Token Space via Structured Memory
Feb 16, 2026Language models are increasingly used to reason over content they were not trained on, such as new documents, evolving knowledge, and user-specific data. A common approach is retrieval-augmented generation (RAG), which stores verbatim documents externally (as chunks) and retrieves only a relevant subset at inference time for an LLM to reason over. However, this results in inefficient usage of test-time compute (LLM repeatedly reasons over the same documents); moreover, chunk retrieval can inject irrelevant context that increases unsupported generation. We propose a human-like non-parametric continual learning framework, where the base model remains fixed, and learning occurs by integrating each new experience into an external semantic memory state that accumulates and consolidates itself continually. We present Panini, which realizes this by representing documents as Generative Semantic Workspaces (GSW) -- an entity- and event-aware network of question-answer (QA) pairs, sufficient for an LLM to reconstruct the experienced situations and mine latent knowledge via reasoning-grounded inference chains on the network. Given a query, Panini only traverses the continually-updated GSW (not the verbatim documents or chunks), and retrieves the most likely inference chains. Across six QA benchmarks, Panini achieves the highest average performance, 5%-7% higher than other competitive baselines, while using 2-30x fewer answer-context tokens, supports fully open-source pipelines, and reduces unsupported answers on curated unanswerable queries. The results show that efficient and accurate structuring of experiences at write time -- as achieved by the GSW framework -- yields both efficiency and reliability gains at read time. Code is available at https://github.com/roychowdhuryresearch/gsw-memory.
Beyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces
Nov 10, 2025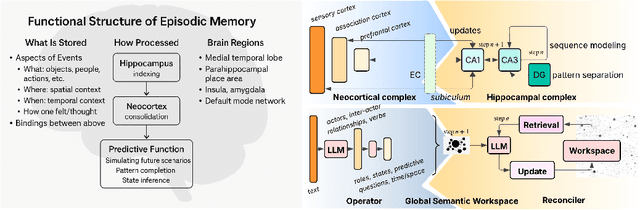
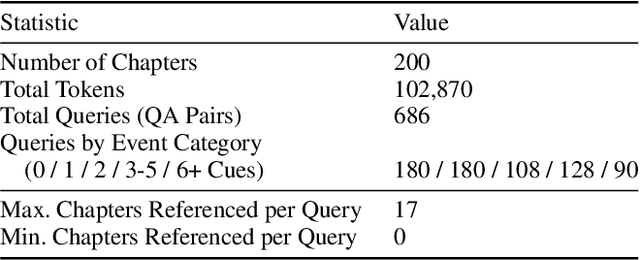
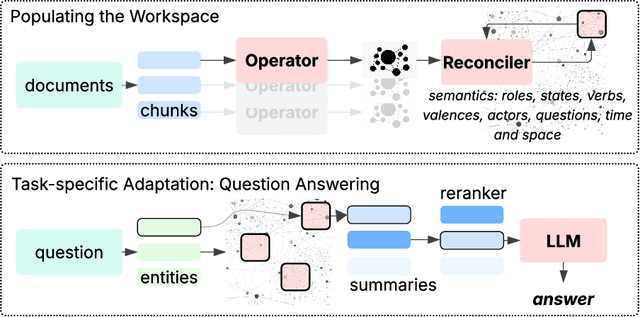
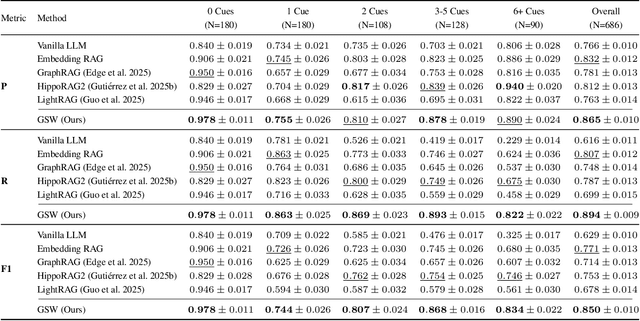
Large Language Models (LLMs) face fundamental challenges in long-context reasoning: many documents exceed their finite context windows, while performance on texts that do fit degrades with sequence length, necessitating their augmentation with external memory frameworks. Current solutions, which have evolved from retrieval using semantic embeddings to more sophisticated structured knowledge graphs representations for improved sense-making and associativity, are tailored for fact-based retrieval and fail to build the space-time-anchored narrative representations required for tracking entities through episodic events. To bridge this gap, we propose the \textbf{Generative Semantic Workspace} (GSW), a neuro-inspired generative memory framework that builds structured, interpretable representations of evolving situations, enabling LLMs to reason over evolving roles, actions, and spatiotemporal contexts. Our framework comprises an \textit{Operator}, which maps incoming observations to intermediate semantic structures, and a \textit{Reconciler}, which integrates these into a persistent workspace that enforces temporal, spatial, and logical coherence. On the Episodic Memory Benchmark (EpBench) \cite{huet_episodic_2025} comprising corpora ranging from 100k to 1M tokens in length, GSW outperforms existing RAG based baselines by up to \textbf{20\%}. Furthermore, GSW is highly efficient, reducing query-time context tokens by \textbf{51\%} compared to the next most token-efficient baseline, reducing inference time costs considerably. More broadly, GSW offers a concrete blueprint for endowing LLMs with human-like episodic memory, paving the way for more capable agents that can reason over long horizons.
First numerical observation of the Berezinskii-Kosterlitz-Thouless transition in language models
Dec 02, 2024



Several power-law critical properties involving different statistics in natural languages -- reminiscent of scaling properties of physical systems at or near phase transitions -- have been documented for decades. The recent rise of large language models (LLMs) has added further evidence and excitement by providing intriguing similarities with notions in physics such as scaling laws and emergent abilities. However, specific instances of classes of generative language models that exhibit phase transitions, as understood by the statistical physics community, are lacking. In this work, inspired by the one-dimensional Potts model in statistical physics we construct a simple probabilistic language model that falls under the class of context sensitive grammars (CSG), and numerically demonstrate an unambiguous phase transition in the framework of a natural language model. We explicitly show that a precisely defined order parameter -- that captures symbol frequency biases in the sentences generated by the language model -- changes from strictly 0 to a strictly nonzero value (in the infinite-length limit of sentences), implying a mathematical singularity arising when tuning the parameter of the stochastic language model we consider. Furthermore, we identify the phase transition as a variant of the Berezinskii-Kosterlitz-Thouless (BKT) transition, which is known to exhibit critical properties not only at the transition point but also in the entire phase. This finding leads to the possibility that critical properties in natural languages may not require careful fine-tuning nor self-organized criticality, but is generically explained by the underlying connection between language structures and the BKT phases.
Creating an AI Observer: Generative Semantic Workspaces
Jun 07, 2024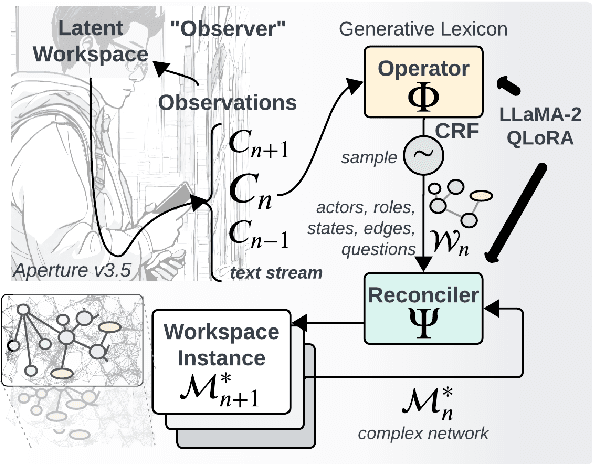
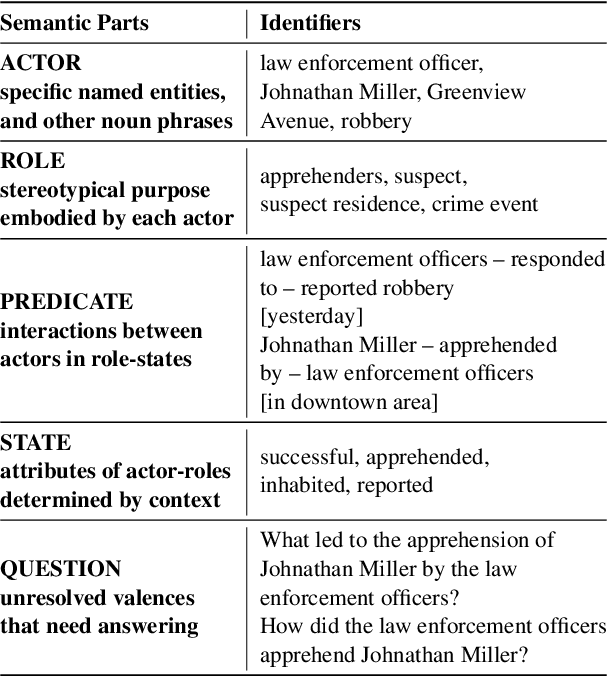
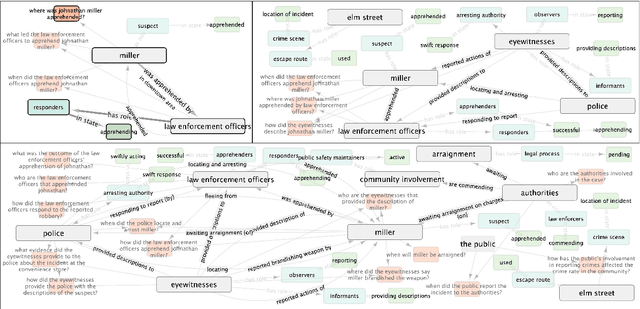
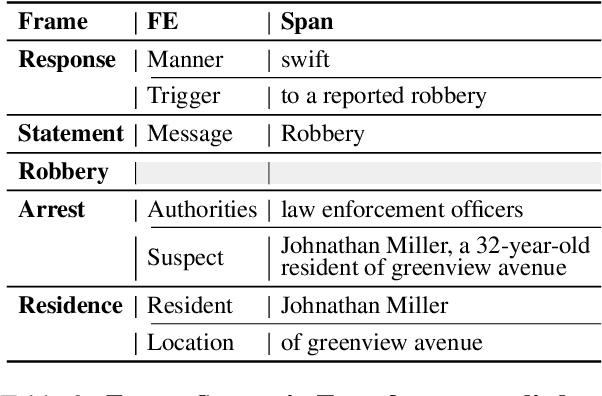
An experienced human Observer reading a document -- such as a crime report -- creates a succinct plot-like $\textit{``Working Memory''}$ comprising different actors, their prototypical roles and states at any point, their evolution over time based on their interactions, and even a map of missing Semantic parts anticipating them in the future. $\textit{An equivalent AI Observer currently does not exist}$. We introduce the $\textbf{[G]}$enerative $\textbf{[S]}$emantic $\textbf{[W]}$orkspace (GSW) -- comprising an $\textit{``Operator''}$ and a $\textit{``Reconciler''}$ -- that leverages advancements in LLMs to create a generative-style Semantic framework, as opposed to a traditionally predefined set of lexicon labels. Given a text segment $C_n$ that describes an ongoing situation, the $\textit{Operator}$ instantiates actor-centric Semantic maps (termed ``Workspace instance'' $\mathcal{W}_n$). The $\textit{Reconciler}$ resolves differences between $\mathcal{W}_n$ and a ``Working memory'' $\mathcal{M}_n^*$ to generate the updated $\mathcal{M}_{n+1}^*$. GSW outperforms well-known baselines on several tasks ($\sim 94\%$ vs. FST, GLEN, BertSRL - multi-sentence Semantics extraction, $\sim 15\%$ vs. NLI-BERT, $\sim 35\%$ vs. QA). By mirroring the real Observer, GSW provides the first step towards Spatial Computing assistants capable of understanding individual intentions and predicting future behavior.
Embed-Search-Align: DNA Sequence Alignment using Transformer Models
Sep 20, 2023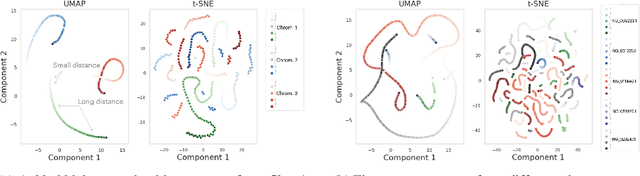
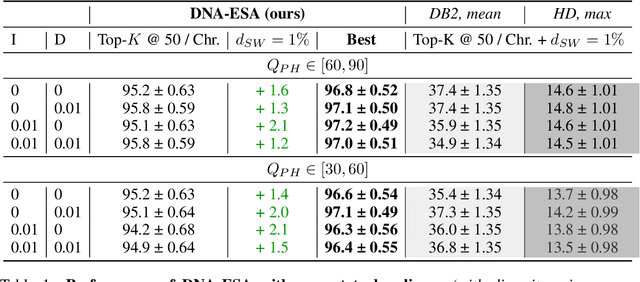
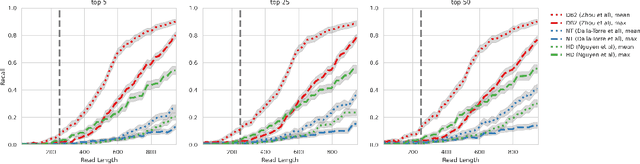

DNA sequence alignment involves assigning short DNA reads to the most probable locations on an extensive reference genome. This process is crucial for various genomic analyses, including variant calling, transcriptomics, and epigenomics. Conventional methods, refined over decades, tackle this challenge in two steps: genome indexing followed by efficient search to locate likely positions for given reads. Building on the success of Large Language Models (LLM) in encoding text into embeddings, where the distance metric captures semantic similarity, recent efforts have explored whether the same Transformer architecture can produce numerical representations for DNA sequences. Such models have shown early promise in tasks involving classification of short DNA sequences, such as the detection of coding vs non-coding regions, as well as the identification of enhancer and promoter sequences. Performance at sequence classification tasks does not, however, translate to sequence alignment, where it is necessary to conduct a genome-wide search to successfully align every read. We address this open problem by framing it as an Embed-Search-Align task. In this framework, a novel encoder model DNA-ESA generates representations of reads and fragments of the reference, which are projected into a shared vector space where the read-fragment distance is used as surrogate for alignment. In particular, DNA-ESA introduces: (1) Contrastive loss for self-supervised training of DNA sequence representations, facilitating rich sequence-level embeddings, and (2) a DNA vector store to enable search across fragments on a global scale. DNA-ESA is >97% accurate when aligning 250-length reads onto a human reference genome of 3 gigabases (single-haploid), far exceeds the performance of 6 recent DNA-Transformer model baselines and shows task transfer across chromosomes and species.
Rapid design of fully soft deployable structures via kirigami cuts and active learning
Mar 04, 2023Soft deployable structures - unlike conventional piecewise rigid deployables based on hinges and springs - can assume intricate 3-D shapes, thereby enabling transformative technologies in soft robotics, shape-morphing architecture, and pop-up manufacturing. Their virtually infinite degrees of freedom allow precise control over the final shape. The same enabling high dimensionality, however, poses a challenge for solving the inverse design problem involving this class of structures: to achieve desired 3D structures it typically requires manufacturing technologies with extensive local actuation and control during fabrication, and a trial and error search over a large design space. We address both of these shortcomings by first developing a simplified planar fabrication approach that combines two ingredients: strain mismatch between two layers of a composite shell and kirigami cuts that relieves localized stress. In principle, it is possible to generate targeted 3-D shapes by designing the appropriate kirigami cuts and selecting the right amount of prestretch, thereby eliminating the need for local control. Second, we formulate a data-driven physics-guided framework that reduces the dimensionality of the inverse design problem using autoencoders and efficiently searches through the ``latent" parameter space in an active learning approach. We demonstrate the effectiveness of the rapid design procedure via a range of target shapes, such as peanuts, pringles, flowers, and pyramids. Tabletop experiments are conducted to fabricate the target shapes. Experimental results and numerical predictions from our framework are found to be in good agreement.