 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbed-Search-Align: DNA Sequence Alignment using Transformer Models
Sep 20, 2023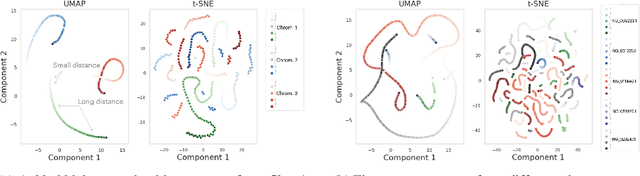
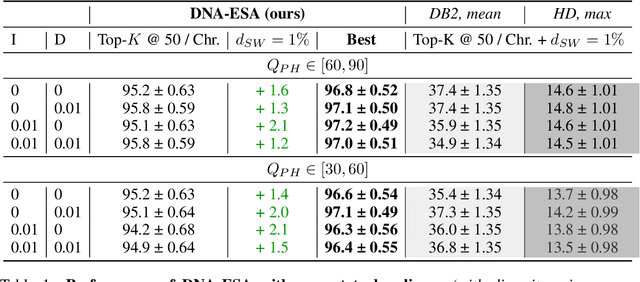
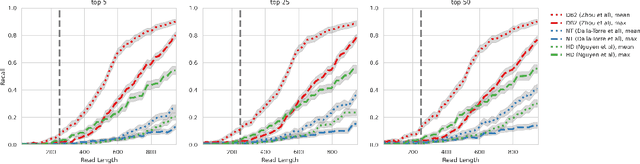

DNA sequence alignment involves assigning short DNA reads to the most probable locations on an extensive reference genome. This process is crucial for various genomic analyses, including variant calling, transcriptomics, and epigenomics. Conventional methods, refined over decades, tackle this challenge in two steps: genome indexing followed by efficient search to locate likely positions for given reads. Building on the success of Large Language Models (LLM) in encoding text into embeddings, where the distance metric captures semantic similarity, recent efforts have explored whether the same Transformer architecture can produce numerical representations for DNA sequences. Such models have shown early promise in tasks involving classification of short DNA sequences, such as the detection of coding vs non-coding regions, as well as the identification of enhancer and promoter sequences. Performance at sequence classification tasks does not, however, translate to sequence alignment, where it is necessary to conduct a genome-wide search to successfully align every read. We address this open problem by framing it as an Embed-Search-Align task. In this framework, a novel encoder model DNA-ESA generates representations of reads and fragments of the reference, which are projected into a shared vector space where the read-fragment distance is used as surrogate for alignment. In particular, DNA-ESA introduces: (1) Contrastive loss for self-supervised training of DNA sequence representations, facilitating rich sequence-level embeddings, and (2) a DNA vector store to enable search across fragments on a global scale. DNA-ESA is >97% accurate when aligning 250-length reads onto a human reference genome of 3 gigabases (single-haploid), far exceeds the performance of 6 recent DNA-Transformer model baselines and shows task transfer across chromosomes and species.
Information geometric bound on general chemical reaction networks
Sep 19, 2023



We investigate the dynamics of chemical reaction networks (CRNs) with the goal of deriving an upper bound on their reaction rates. This task is challenging due to the nonlinear nature and discrete structure inherent in CRNs. To address this, we employ an information geometric approach, using the natural gradient, to develop a nonlinear system that yields an upper bound for CRN dynamics. We validate our approach through numerical simulations, demonstrating faster convergence in a specific class of CRNs. This class is characterized by the number of chemicals, the maximum value of stoichiometric coefficients of the chemical reactions, and the number of reactions. We also compare our method to a conventional approach, showing that the latter cannot provide an upper bound on reaction rates of CRNs. While our study focuses on CRNs, the ubiquity of hypergraphs in fields from natural sciences to engineering suggests that our method may find broader applications, including in information science.
Quantum Approximation of Normalized Schatten Norms and Applications to Learning
Jun 23, 2022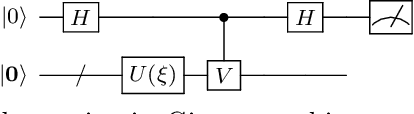



Efficient measures to determine similarity of quantum states, such as the fidelity metric, have been widely studied. In this paper, we address the problem of defining a similarity measure for quantum operations that can be \textit{efficiently estimated}. Given two quantum operations, $U_1$ and $U_2$, represented in their circuit forms, we first develop a quantum sampling circuit to estimate the normalized Schatten 2-norm of their difference ($\| U_1-U_2 \|_{S_2}$) with precision $\epsilon$, using only one clean qubit and one classical random variable. We prove a Poly$(\frac{1}{\epsilon})$ upper bound on the sample complexity, which is independent of the size of the quantum system. We then show that such a similarity metric is directly related to a functional definition of similarity of unitary operations using the conventional fidelity metric of quantum states ($F$): If $\| U_1-U_2 \|_{S_2}$ is sufficiently small (e.g. $ \leq \frac{\epsilon}{1+\sqrt{2(1/\delta - 1)}}$) then the fidelity of states obtained by processing the same randomly and uniformly picked pure state, $|\psi \rangle$, is as high as needed ($F({U}_1 |\psi \rangle, {U}_2 |\psi \rangle)\geq 1-\epsilon$) with probability exceeding $1-\delta$. We provide example applications of this efficient similarity metric estimation framework to quantum circuit learning tasks, such as finding the square root of a given unitary operation.
Scalable End-to-End RF Classification: A Case Study on Undersized Dataset Regularization by Convolutional-MST
May 13, 2021



Unlike areas such as computer vision and speech recognition where convolutional and recurrent neural networks-based approaches have proven effective to the nature of the respective areas of application, deep learning (DL) still lacks a general approach suitable for the unique nature and challenges of RF systems such as radar, signals intelligence, electronic warfare, and communications. Existing approaches face problems in robustness, consistency, efficiency, repeatability and scalability. One of the main challenges in RF sensing such as radar target identification is the difficulty and cost of obtaining data. Hundreds to thousands of samples per class are typically used when training for classifying signals into 2 to 12 classes with reported accuracy ranging from 87% to 99%, where accuracy generally decreases with more classes added. In this paper, we present a new DL approach based on multistage training and demonstrate it on RF sensing signal classification. We consistently achieve over 99% accuracy for up to 17 diverse classes using only 11 samples per class for training, yielding up to 35% improvement in accuracy over standard DL approaches.
Machine Learning Approach to RF Transmitter Identification
Nov 07, 2017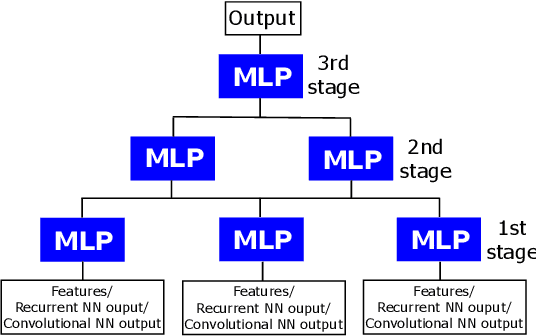
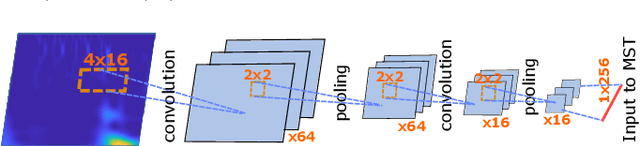
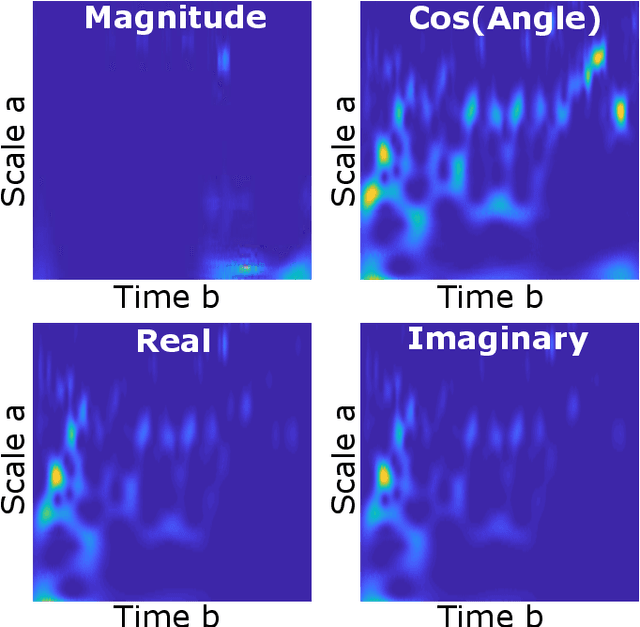

With the development and widespread use of wireless devices in recent years (mobile phones, Internet of Things, Wi-Fi), the electromagnetic spectrum has become extremely crowded. In order to counter security threats posed by rogue or unknown transmitters, it is important to identify RF transmitters not by the data content of the transmissions but based on the intrinsic physical characteristics of the transmitters. RF waveforms represent a particular challenge because of the extremely high data rates involved and the potentially large number of transmitters present in a given location. These factors outline the need for rapid fingerprinting and identification methods that go beyond the traditional hand-engineered approaches. In this study, we investigate the use of machine learning (ML) strategies to the classification and identification problems, and the use of wavelets to reduce the amount of data required. Four different ML strategies are evaluated: deep neural nets (DNN), convolutional neural nets (CNN), support vector machines (SVM), and multi-stage training (MST) using accelerated Levenberg-Marquardt (A-LM) updates. The A-LM MST method preconditioned by wavelets was by far the most accurate, achieving 100% classification accuracy of transmitters, as tested using data originating from 12 different transmitters. We discuss strategies for extension of MST to a much larger number of transmitters.