 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasetEquity: Are All Samples Created Equal? In The Quest For Equity Within Datasets
Paper and Code
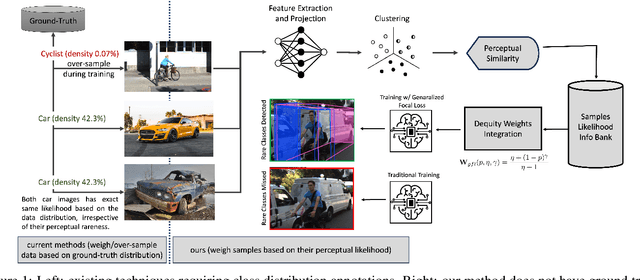

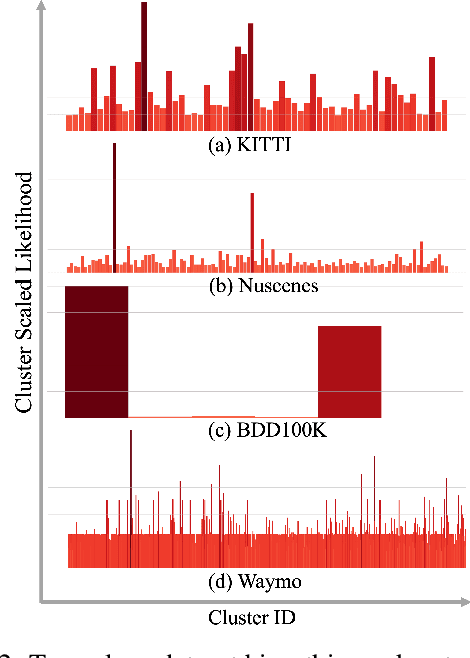
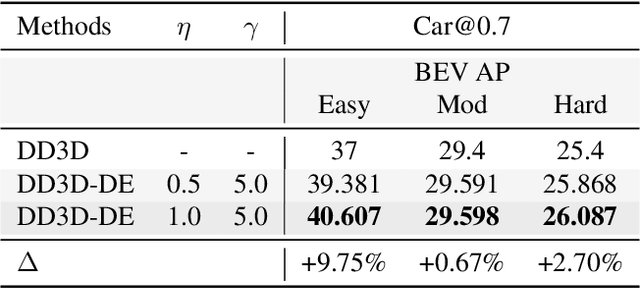
Data imbalance is a well-known issue in the field of machine learning, attributable to the cost of data collection, the difficulty of labeling, and the geographical distribution of the data. In computer vision, bias in data distribution caused by image appearance remains highly unexplored. Compared to categorical distributions using class labels, image appearance reveals complex relationships between objects beyond what class labels provide. Clustering deep perceptual features extracted from raw pixels gives a richer representation of the data. This paper presents a novel method for addressing data imbalance in machine learning. The method computes sample likelihoods based on image appearance using deep perceptual embeddings and clustering. It then uses these likelihoods to weigh samples differently during training with a proposed $\textbf{Generalized Focal Loss}$ function. This loss can be easily integrated with deep learning algorithms. Experiments validate the method's effectiveness across autonomous driving vision datasets including KITTI and nuScenes. The loss function improves state-of-the-art 3D object detection methods, achieving over $200\%$ AP gains on under-represented classes (Cyclist) in the KITTI dataset. The results demonstrate the method is generalizable, complements existing techniques, and is particularly beneficial for smaller datasets and rare classes. Code is available at: https://github.com/towardsautonomy/DatasetEquity