 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning High-Performing Networks for Multi-Scale Computer Vision
Feb 19, 2024Since the emergence of deep learning, the computer vision field has flourished with models improving at a rapid pace on more and more complex tasks. We distinguish three main ways to improve a computer vision model: (1) improving the data aspect by for example training on a large, more diverse dataset, (2) improving the training aspect by for example designing a better optimizer, and (3) improving the network architecture (or network for short). In this thesis, we chose to improve the latter, i.e. improving the network designs of computer vision models. More specifically, we investigate new network designs for multi-scale computer vision tasks, which are tasks requiring to make predictions about concepts at different scales. The goal of these new network designs is to outperform existing baseline designs from the literature. Specific care is taken to make sure the comparisons are fair, by guaranteeing that the different network designs were trained and evaluated with the same settings. Code is publicly available at https://github.com/CedricPicron/DetSeg.
EffSeg: Efficient Fine-Grained Instance Segmentation using Structure-Preserving Sparsity
Jul 04, 2023



Many two-stage instance segmentation heads predict a coarse 28x28 mask per instance, which is insufficient to capture the fine-grained details of many objects. To address this issue, PointRend and RefineMask predict a 112x112 segmentation mask resulting in higher quality segmentations. Both methods however have limitations by either not having access to neighboring features (PointRend) or by performing computation at all spatial locations instead of sparsely (RefineMask). In this work, we propose EffSeg performing fine-grained instance segmentation in an efficient way by using our Structure-Preserving Sparsity (SPS) method based on separately storing the active features, the passive features and a dense 2D index map containing the feature indices. The goal of the index map is to preserve the 2D spatial configuration or structure between the features such that any 2D operation can still be performed. EffSeg achieves similar performance on COCO compared to RefineMask, while reducing the number of FLOPs by 71% and increasing the FPS by 29%. Code will be released.
FQDet: Fast-converging Query-based Detector
Oct 05, 2022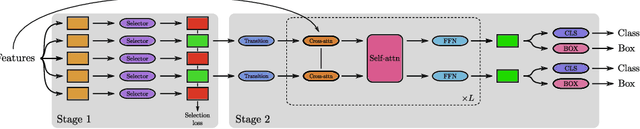
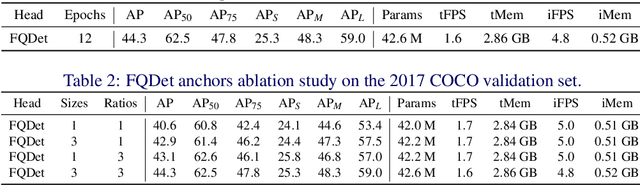
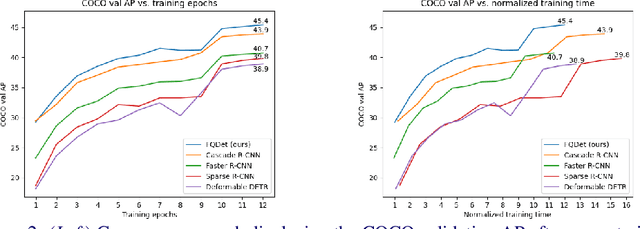

Recently, two-stage Deformable DETR introduced the query-based two-stage head, a new type of two-stage head different from the region-based two-stage heads of classical detectors as Faster R-CNN. In query-based two-stage heads, the second stage selects one feature per detection, called the query, as opposed to pooling a rectangular grid of features as in region-based detectors. In this work, we further improve the query-based head from Deformable DETR, significantly speeding up the convergence while increasing its performance. This is achieved by incorporating classical techniques such as anchor generation within the query-based paradigm. By combining the best of both the classical and the query-based worlds, our FQDet head peaks at 45.4 AP on the 2017 COCO validation set when using a ResNet-50+TPN backbone, only after training for 12 epochs using the 1x schedule. We outperform other high-performing two-stage heads such as e.g. Cascade R-CNN, while using the same backbone and while often being computationally cheaper. Additionally, when using the large ResNeXt-101-DCN+TPN backbone and multi-scale testing, our FQDet head achieves 52.9 AP on the 2017 COCO test-dev set after only 12 epochs of training. Code will be released.
Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation
Aug 16, 2022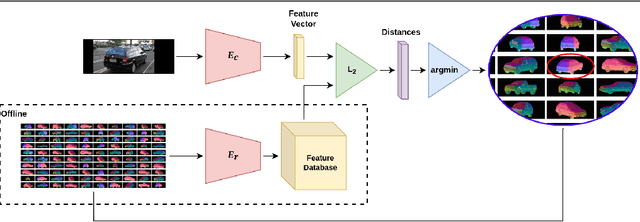
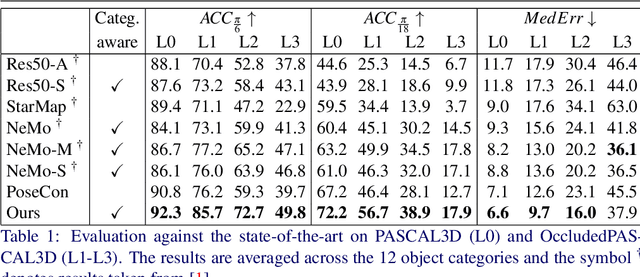
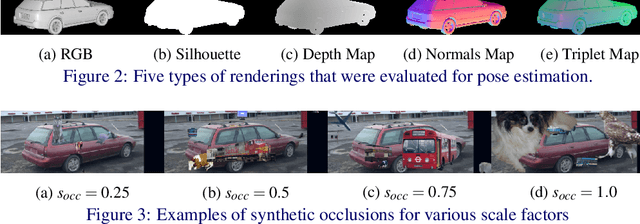
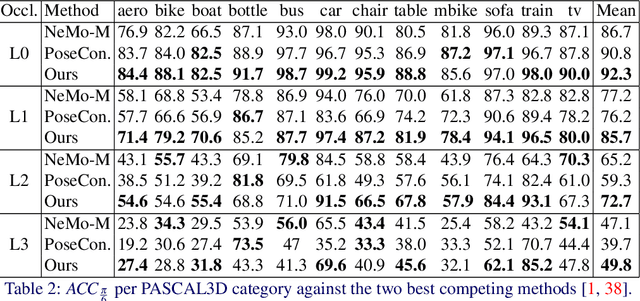
Pose estimation is usually tackled as either a bin classification problem or as a regression problem. In both cases, the idea is to directly predict the pose of an object. This is a non-trivial task because of appearance variations of similar poses and similarities between different poses. Instead, we follow the key idea that it is easier to compare two poses than to estimate them. Render-and-compare approaches have been employed to that end, however, they tend to be unstable, computationally expensive, and slow for real-time applications. We propose doing category-level pose estimation by learning an alignment metric using a contrastive loss with a dynamic margin and a continuous pose-label space. For efficient inference, we use a simple real-time image retrieval scheme with a reference set of renderings projected to an embedding space. To achieve robustness to real-world conditions, we employ synthetic occlusions, bounding box perturbations, and appearance augmentations. Our approach achieves state-of-the-art performance on PASCAL3D and OccludedPASCAL3D, as well as high-quality results on KITTI3D.
Trident Pyramid Networks: The importance of processing at the feature pyramid level for better object detection
Oct 08, 2021


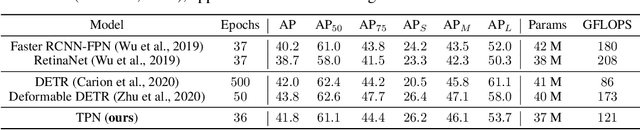
Feature pyramids have become ubiquitous in multi-scale computer vision tasks such as object detection. Based on their importance, we divide a computer vision network into three parts: a backbone (generating a feature pyramid), a core (refining the feature pyramid) and a head (generating the final output). Most existing networks operating on feature pyramids, named cores, are shallow and mostly focus on communication-based processing in the form of top-down and bottom-up operations. We present a new core architecture called Trident Pyramid Network (TPN), that allows for a deeper design and for a better balance between communication-based processing and self-processing. We show consistent improvements when using our TPN core on the COCO object detection benchmark, outperforming the popular BiFPN baseline by 1.5 AP. Additionally, we empirically show that it is more beneficial to put additional computation into the TPN core, rather than into the backbone, by outperforming a ResNet-101+FPN baseline with our ResNet-50+TPN network by 1.7 AP, while operating under similar computation budgets. This emphasizes the importance of performing computation at the feature pyramid level in modern-day object detection systems. Code will be released.
What My Motion tells me about Your Pose: Self-Supervised Fine-Tuning of Observed Vehicle Orientation Angle
Jul 29, 2020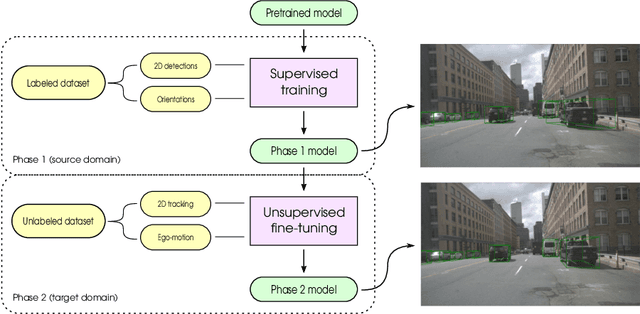
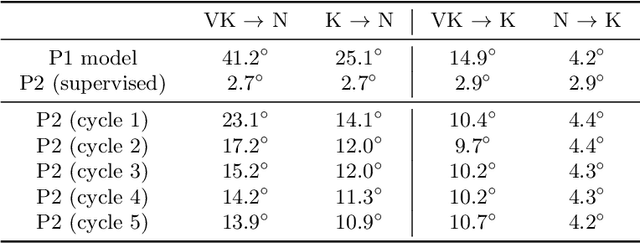
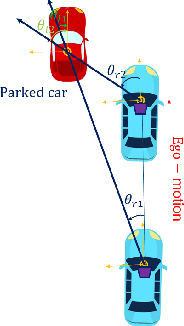

The determination of the relative 6 Degree of Freedom (DoF) pose of vehicles around the ego-vehicle from monocular cameras is an important aspect of the perception problem for Autonomous Vehicles (AVs) and Driver Assist Technology (DAT). Current deep learning techniques used for tackling this problem are data hungry, driving the need for unsupervised or self-supervised methods. In this paper, we consider the domain adaptation task of fine-tuning a vehicle orientation estimator on a new domain without labels. By leveraging the ego-motion consistencies obtained from a monocular SLAM method, we show that our self-supervised fine-tuning scheme consistently improves the accuracy of the resulting network. More specifically, when transitioning from Virtual Kitti to nuScenes, up to 70% of the performance is recovered compared to the 100% of a supervised method. Our self-supervised method hence allows us to safely transfer vehicle orientation estimators to new domains without requiring expensive new labels.