 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat My Motion tells me about Your Pose: Self-Supervised Fine-Tuning of Observed Vehicle Orientation Angle
Jul 29, 2020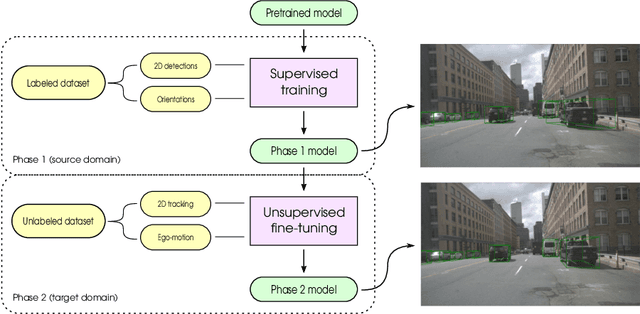
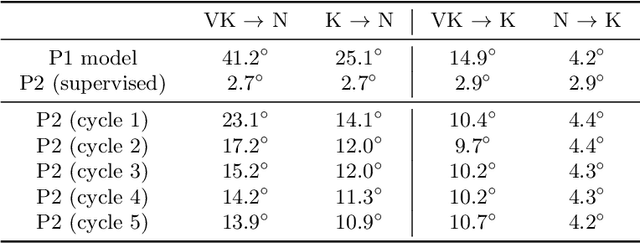
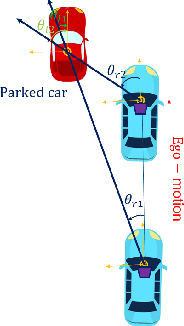

The determination of the relative 6 Degree of Freedom (DoF) pose of vehicles around the ego-vehicle from monocular cameras is an important aspect of the perception problem for Autonomous Vehicles (AVs) and Driver Assist Technology (DAT). Current deep learning techniques used for tackling this problem are data hungry, driving the need for unsupervised or self-supervised methods. In this paper, we consider the domain adaptation task of fine-tuning a vehicle orientation estimator on a new domain without labels. By leveraging the ego-motion consistencies obtained from a monocular SLAM method, we show that our self-supervised fine-tuning scheme consistently improves the accuracy of the resulting network. More specifically, when transitioning from Virtual Kitti to nuScenes, up to 70% of the performance is recovered compared to the 100% of a supervised method. Our self-supervised method hence allows us to safely transfer vehicle orientation estimators to new domains without requiring expensive new labels.
Deep-Geometric 6 DoF Localization from a Single Image in Topo-metric Maps
Feb 04, 2020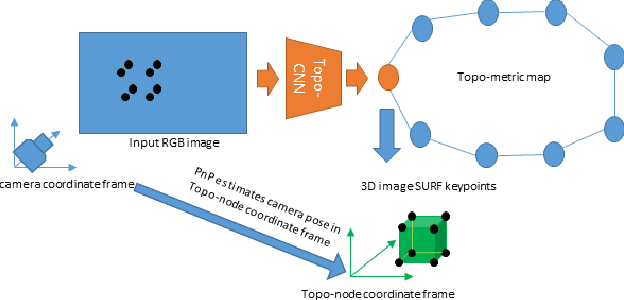
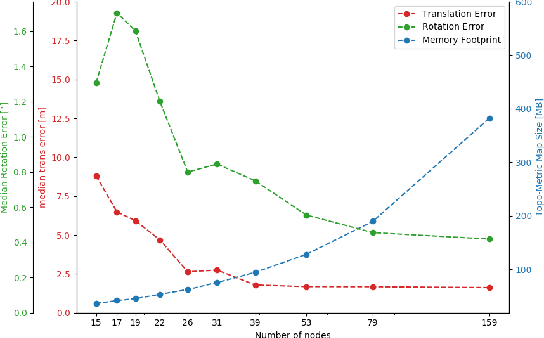
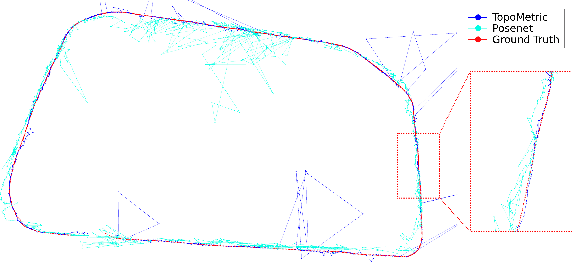

We describe a Deep-Geometric Localizer that is able to estimate the full 6 Degree of Freedom (DoF) global pose of the camera from a single image in a previously mapped environment. Our map is a topo-metric one, with discrete topological nodes whose 6 DoF poses are known. Each topo-node in our map also comprises of a set of points, whose 2D features and 3D locations are stored as part of the mapping process. For the mapping phase, we utilise a stereo camera and a regular stereo visual SLAM pipeline. During the localization phase, we take a single camera image, localize it to a topological node using Deep Learning, and use a geometric algorithm (PnP) on the matched 2D features (and their 3D positions in the topo map) to determine the full 6 DoF globally consistent pose of the camera. Our method divorces the mapping and the localization algorithms and sensors (stereo and mono), and allows accurate 6 DoF pose estimation in a previously mapped environment using a single camera. With potential VR/AR and localization applications in single camera devices such as mobile phones and drones, our hybrid algorithm compares favourably with the fully Deep-Learning based Pose-Net that regresses pose from a single image in simulated as well as real environments.
GEN-SLAM: Generative Modeling for Monocular Simultaneous Localization and Mapping
Feb 06, 2019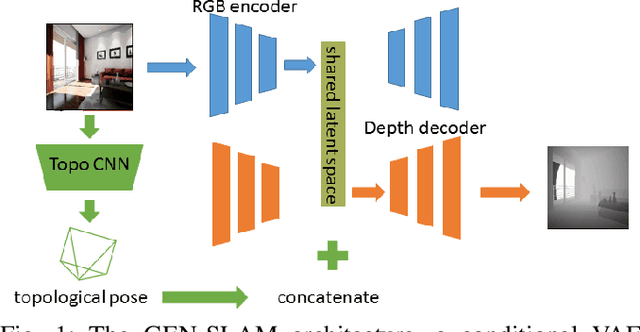
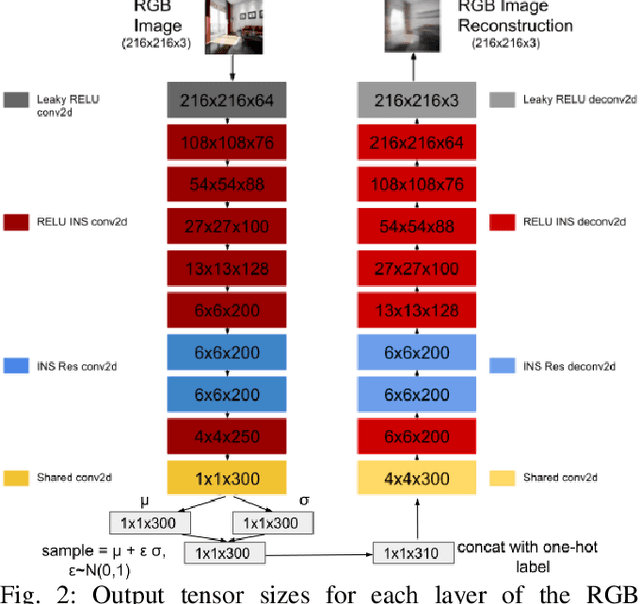

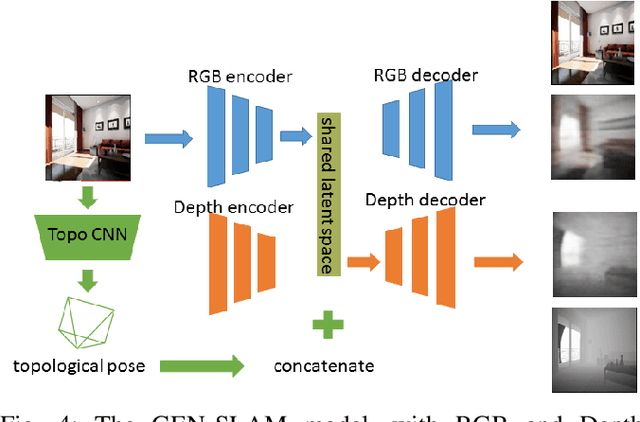
We present a Deep Learning based system for the twin tasks of localization and obstacle avoidance essential to any mobile robot. Our system learns from conventional geometric SLAM, and outputs, using a single camera, the topological pose of the camera in an environment, and the depth map of obstacles around it. We use a CNN to localize in a topological map, and a conditional VAE to output depth for a camera image, conditional on this topological location estimation. We demonstrate the effectiveness of our monocular localization and depth estimation system on simulated and real datasets.