Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEN-SLAM: Generative Modeling for Monocular Simultaneous Localization and Mapping
Paper and Code
Feb 06, 2019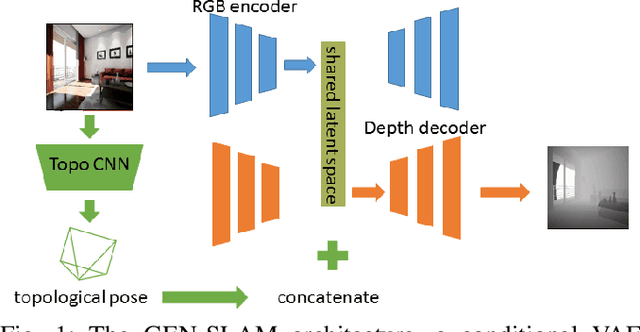
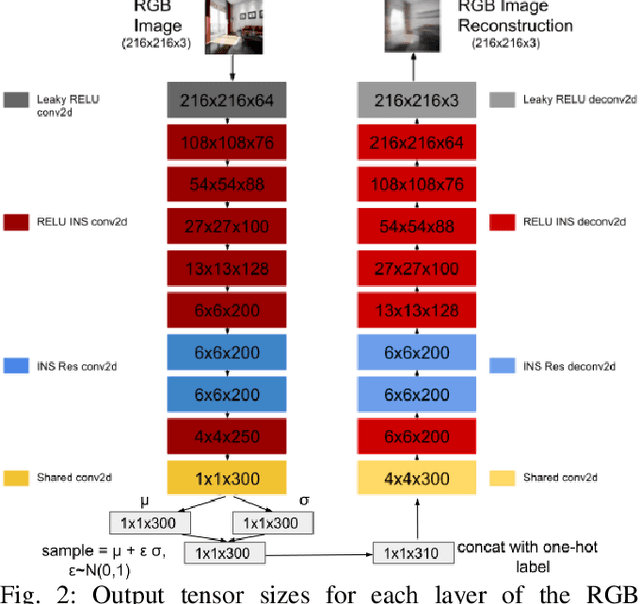

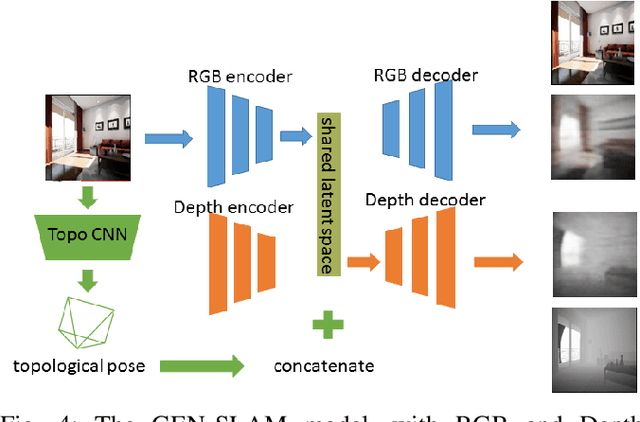
We present a Deep Learning based system for the twin tasks of localization and obstacle avoidance essential to any mobile robot. Our system learns from conventional geometric SLAM, and outputs, using a single camera, the topological pose of the camera in an environment, and the depth map of obstacles around it. We use a CNN to localize in a topological map, and a conditional VAE to output depth for a camera image, conditional on this topological location estimation. We demonstrate the effectiveness of our monocular localization and depth estimation system on simulated and real datasets.
* Accepted for ICRA 2019
View paper on