 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate and Robust Classification in Continuously Transitioning Industrial Sprays with Mixup
Jul 20, 2022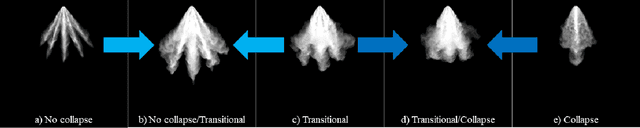
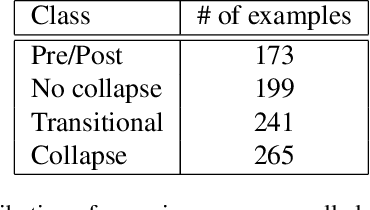
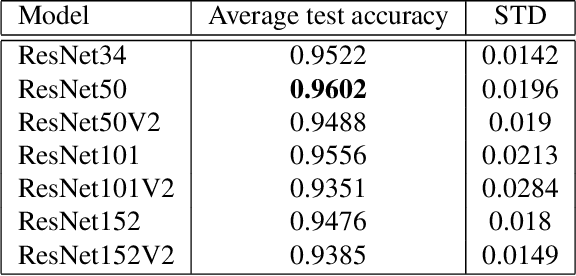
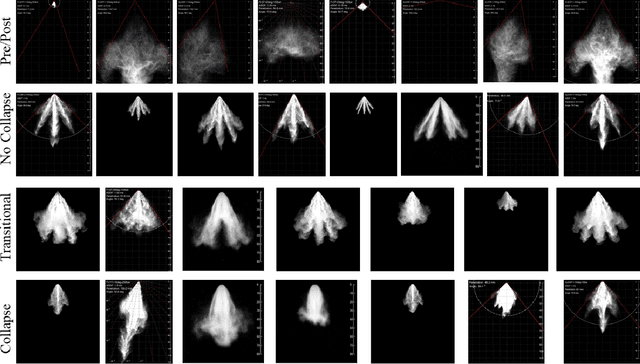
Image classification with deep neural networks has seen a surge of technological breakthroughs with promising applications in areas such as face recognition, medical imaging, and autonomous driving. In engineering problems, however, such as high-speed imaging of engine fuel injector sprays or body paint sprays, deep neural networks face a fundamental challenge related to the availability of adequate and diverse data. Typically, only thousands or sometimes even hundreds of samples are available for training. In addition, the transition between different spray classes is a continuum and requires a high level of domain expertise to label the images accurately. In this work, we used Mixup as an approach to systematically deal with the data scarcity and ambiguous class boundaries found in industrial spray applications. We show that data augmentation can mitigate the over-fitting problem of large neural networks on small data sets, to a certain level, but cannot fundamentally resolve the issue. We discuss how a convex linear interpolation of different classes naturally aligns with the continuous transition between different classes in our application. Our experiments demonstrate Mixup as a simple yet effective method to train an accurate and robust deep neural network classifier with only a few hundred samples.
Full-Velocity Radar Returns by Radar-Camera Fusion
Aug 24, 2021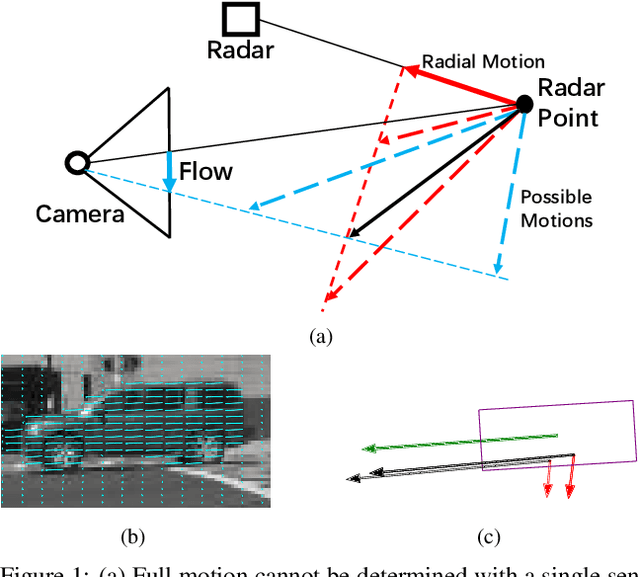
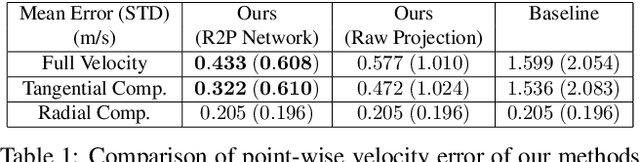

A distinctive feature of Doppler radar is the measurement of velocity in the radial direction for radar points. However, the missing tangential velocity component hampers object velocity estimation as well as temporal integration of radar sweeps in dynamic scenes. Recognizing that fusing camera with radar provides complementary information to radar, in this paper we present a closed-form solution for the point-wise, full-velocity estimate of Doppler returns using the corresponding optical flow from camera images. Additionally, we address the association problem between radar returns and camera images with a neural network that is trained to estimate radar-camera correspondences. Experimental results on the nuScenes dataset verify the validity of the method and show significant improvements over the state-of-the-art in velocity estimation and accumulation of radar points.
Radar-Camera Pixel Depth Association for Depth Completion
Jun 05, 2021



While radar and video data can be readily fused at the detection level, fusing them at the pixel level is potentially more beneficial. This is also more challenging in part due to the sparsity of radar, but also because automotive radar beams are much wider than a typical pixel combined with a large baseline between camera and radar, which results in poor association between radar pixels and color pixel. A consequence is that depth completion methods designed for LiDAR and video fare poorly for radar and video. Here we propose a radar-to-pixel association stage which learns a mapping from radar returns to pixels. This mapping also serves to densify radar returns. Using this as a first stage, followed by a more traditional depth completion method, we are able to achieve image-guided depth completion with radar and video. We demonstrate performance superior to camera and radar alone on the nuScenes dataset. Our source code is available at https://github.com/longyunf/rc-pda.
On the Role of Receptive Field in Unsupervised Sim-to-Real Image Translation
Jan 25, 2020
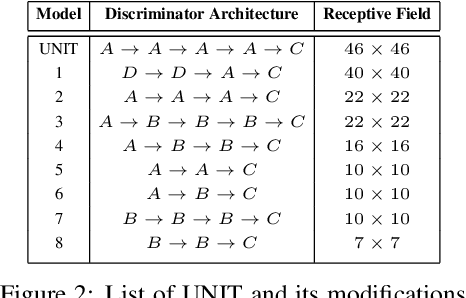
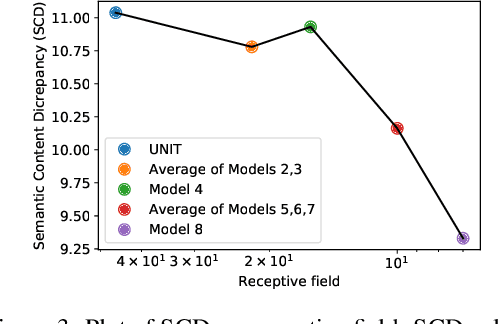

Generative Adversarial Networks (GANs) are now widely used for photo-realistic image synthesis. In applications where a simulated image needs to be translated into a realistic image (sim-to-real), GANs trained on unpaired data from the two domains are susceptible to failure in semantic content retention as the image is translated from one domain to the other. This failure mode is more pronounced in cases where the real data lacks content diversity, resulting in a content \emph{mismatch} between the two domains - a situation often encountered in real-world deployment. In this paper, we investigate the role of the discriminator's receptive field in GANs for unsupervised image-to-image translation with mismatched data, and study its effect on semantic content retention. Experiments with the discriminator architecture of a state-of-the-art coupled Variational Auto-Encoder (VAE) - GAN model on diverse, mismatched datasets show that the discriminator receptive field is directly correlated with semantic content discrepancy of the generated image.
Hierarchical Sequence to Sequence Voice Conversion with Limited Data
Jul 15, 2019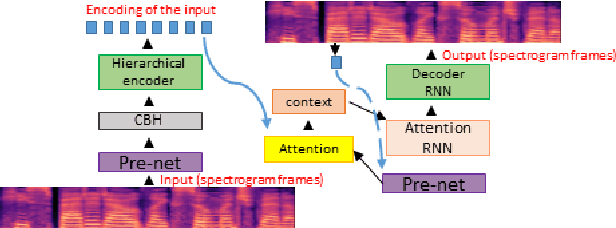

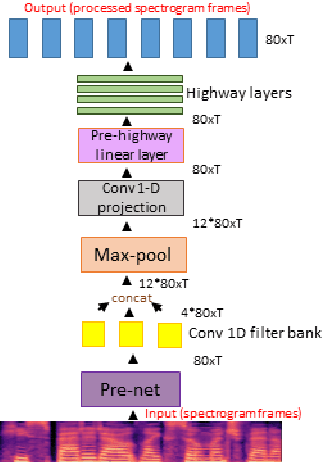
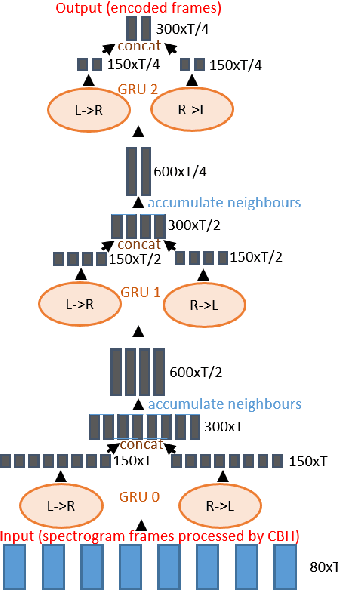
We present a voice conversion solution using recurrent sequence to sequence modeling for DNNs. Our solution takes advantage of recent advances in attention based modeling in the fields of Neural Machine Translation (NMT), Text-to-Speech (TTS) and Automatic Speech Recognition (ASR). The problem consists of converting between voices in a parallel setting when {\it $<$source,target$>$} audio pairs are available. Our seq2seq architecture makes use of a hierarchical encoder to summarize input audio frames. On the decoder side, we use an attention based architecture used in recent TTS works. Since there is a dearth of large multispeaker voice conversion databases needed for training DNNs, we resort to training the network with a large single speaker dataset as an autoencoder. This is then adapted for the smaller multispeaker voice conversion datasets available for voice conversion. In contrast with other voice conversion works that use $F_0$, duration and linguistic features, our system uses mel spectrograms as the audio representation. Output mel frames are converted back to audio using a wavenet vocoder.
GEN-SLAM: Generative Modeling for Monocular Simultaneous Localization and Mapping
Feb 06, 2019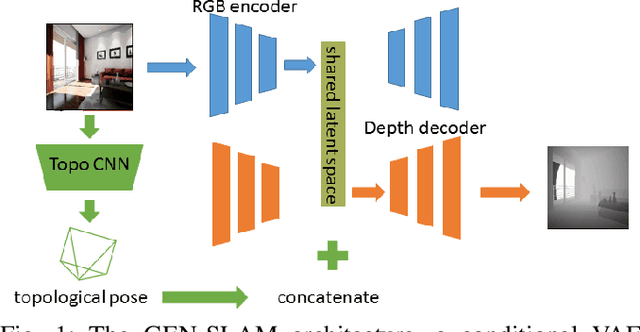
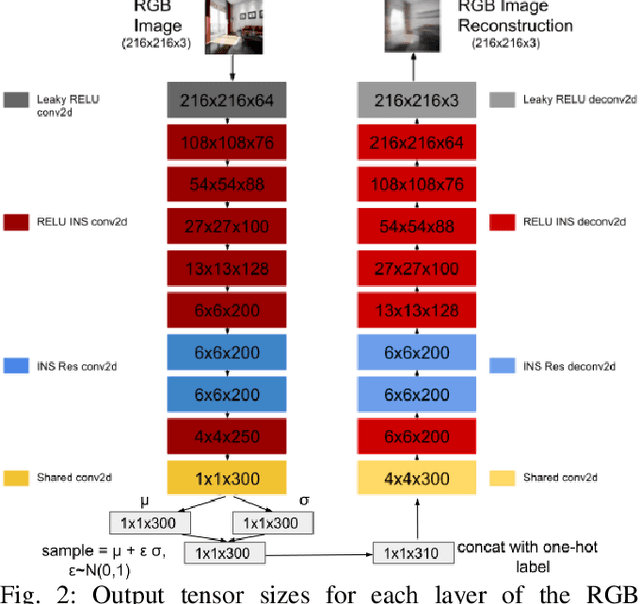

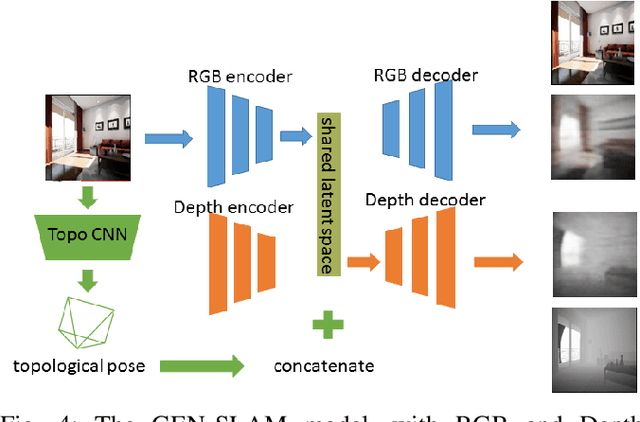
We present a Deep Learning based system for the twin tasks of localization and obstacle avoidance essential to any mobile robot. Our system learns from conventional geometric SLAM, and outputs, using a single camera, the topological pose of the camera in an environment, and the depth map of obstacles around it. We use a CNN to localize in a topological map, and a conditional VAE to output depth for a camera image, conditional on this topological location estimation. We demonstrate the effectiveness of our monocular localization and depth estimation system on simulated and real datasets.