 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeflating Dataset Bias Using Synthetic Data Augmentation
Apr 28, 2020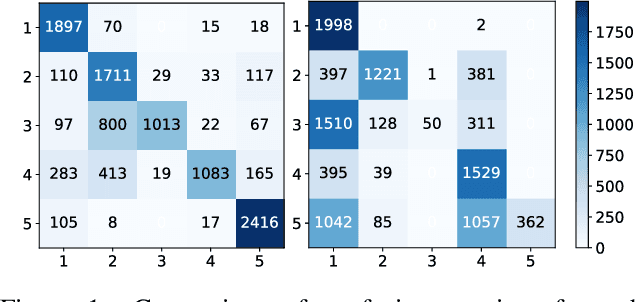
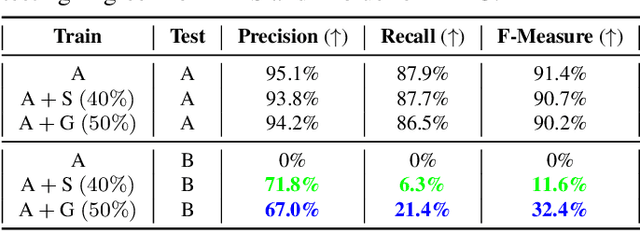

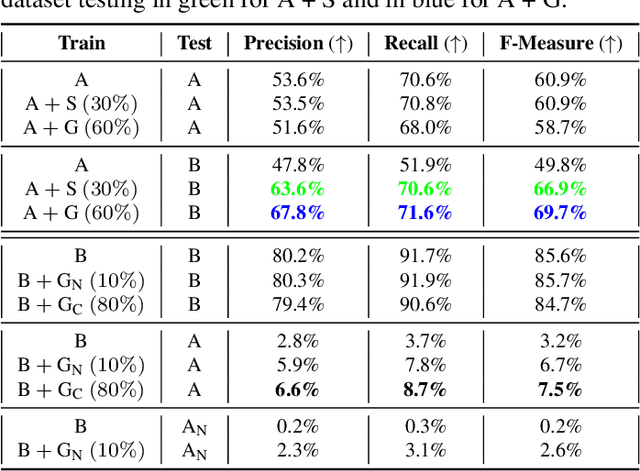
Deep Learning has seen an unprecedented increase in vision applications since the publication of large-scale object recognition datasets and introduction of scalable compute hardware. State-of-the-art methods for most vision tasks for Autonomous Vehicles (AVs) rely on supervised learning and often fail to generalize to domain shifts and/or outliers. Dataset diversity is thus key to successful real-world deployment. No matter how big the size of the dataset, capturing long tails of the distribution pertaining to task-specific environmental factors is impractical. The goal of this paper is to investigate the use of targeted synthetic data augmentation - combining the benefits of gaming engine simulations and sim2real style transfer techniques - for filling gaps in real datasets for vision tasks. Empirical studies on three different computer vision tasks of practical use to AVs - parking slot detection, lane detection and monocular depth estimation - consistently show that having synthetic data in the training mix provides a significant boost in cross-dataset generalization performance as compared to training on real data only, for the same size of the training set.
On the Role of Receptive Field in Unsupervised Sim-to-Real Image Translation
Jan 25, 2020
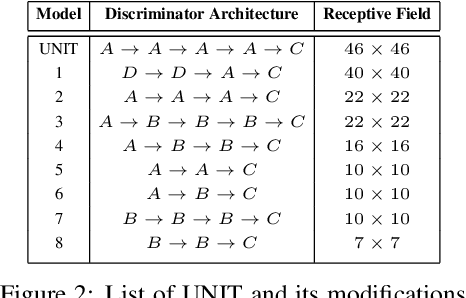
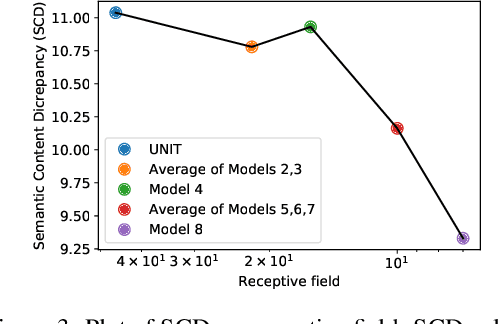

Generative Adversarial Networks (GANs) are now widely used for photo-realistic image synthesis. In applications where a simulated image needs to be translated into a realistic image (sim-to-real), GANs trained on unpaired data from the two domains are susceptible to failure in semantic content retention as the image is translated from one domain to the other. This failure mode is more pronounced in cases where the real data lacks content diversity, resulting in a content \emph{mismatch} between the two domains - a situation often encountered in real-world deployment. In this paper, we investigate the role of the discriminator's receptive field in GANs for unsupervised image-to-image translation with mismatched data, and study its effect on semantic content retention. Experiments with the discriminator architecture of a state-of-the-art coupled Variational Auto-Encoder (VAE) - GAN model on diverse, mismatched datasets show that the discriminator receptive field is directly correlated with semantic content discrepancy of the generated image.
A Mobile Robotic Personal Nightstand with Integrated Perceptual Processes
Oct 13, 2013
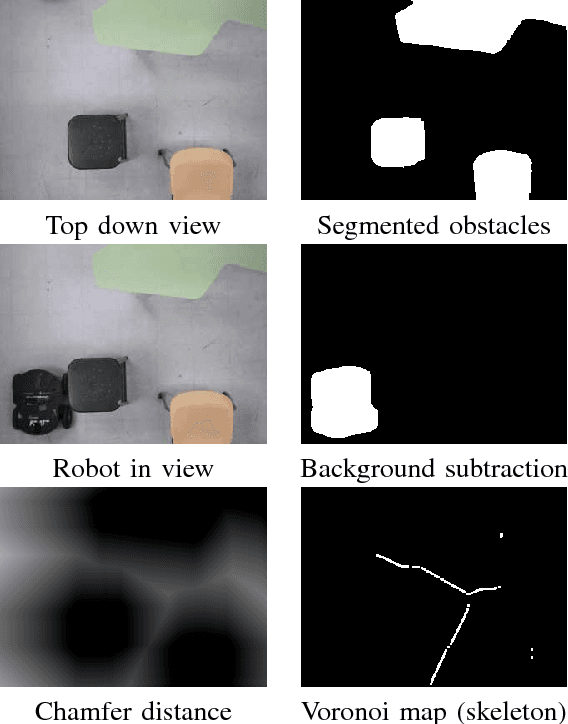
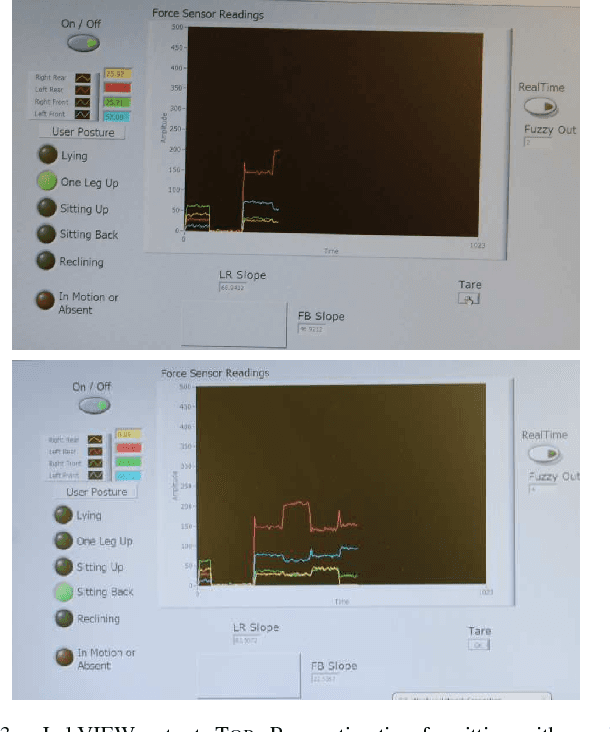
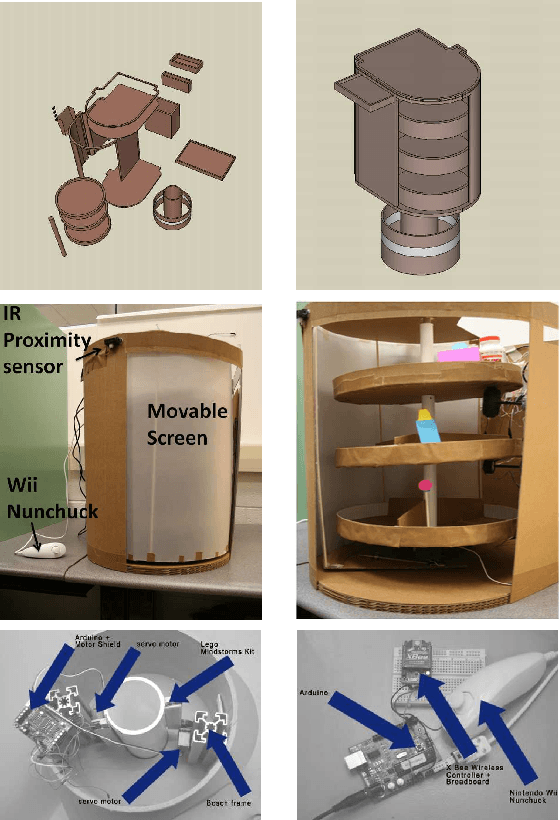
We present an intelligent interactive nightstand mounted on a mobile robot, to aid the elderly in their homes using physical, tactile and visual percepts. We show the integration of three different sensing modalities for controlling the navigation of a robot mounted nightstand within the constrained environment of a general purpose living room housing a single aging individual in need of assistance and monitoring. A camera mounted on the ceiling of the room, gives a top-down view of the obstacles, the person and the nightstand. Pressure sensors mounted beneath the bed-stand of the individual provide physical perception of the person's state. A proximity IR sensor on the nightstand acts as a tactile interface along with a Wii Nunchuck (Nintendo) to control mundane operations on the nightstand. Intelligence from these three modalities are combined to enable path planning for the nightstand to approach the individual. With growing emphasis on assistive technology for the aging individuals who are increasingly electing to stay in their homes, we show how ubiquitous intelligence can be brought inside homes to help monitor and provide care to an individual. Our approach goes one step towards achieving pervasive intelligence by seamlessly integrating different sensors embedded in the fabric of the environment.