 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjECTive-QA: Measuring Subjectivity in Earnings Call Transcripts' QA Through Six-Dimensional Feature Analysis
Oct 28, 2024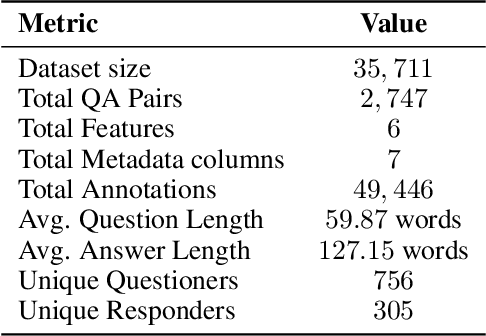

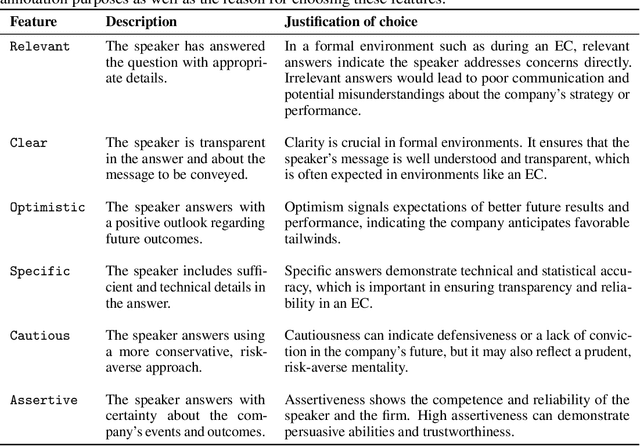
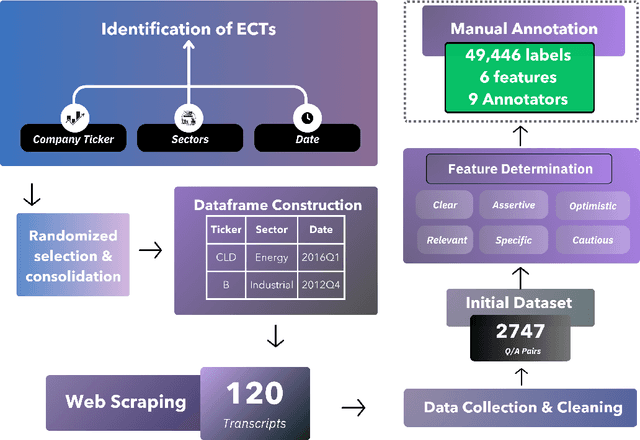
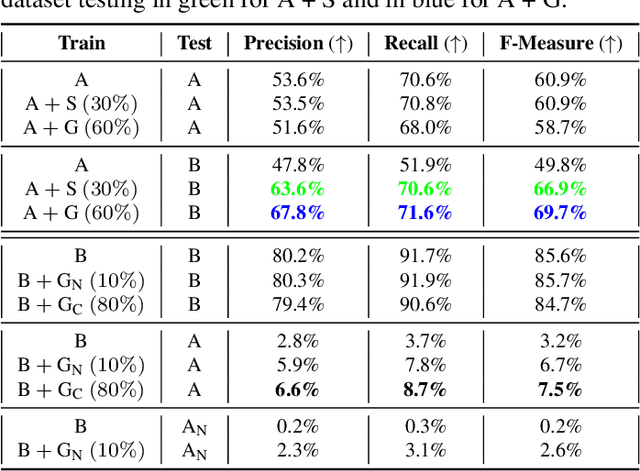
Fact-checking is extensively studied in the context of misinformation and disinformation, addressing objective inaccuracies. However, a softer form of misinformation involves responses that are factually correct but lack certain features such as clarity and relevance. This challenge is prevalent in formal Question-Answer (QA) settings such as press conferences in finance, politics, sports, and other domains, where subjective answers can obscure transparency. Despite this, there is a lack of manually annotated datasets for subjective features across multiple dimensions. To address this gap, we introduce SubjECTive-QA, a human annotated dataset on Earnings Call Transcripts' (ECTs) QA sessions as the answers given by company representatives are often open to subjective interpretations and scrutiny. The dataset includes 49,446 annotations for long-form QA pairs across six features: Assertive, Cautious, Optimistic, Specific, Clear, and Relevant. These features are carefully selected to encompass the key attributes that reflect the tone of the answers provided during QA sessions across different domain. Our findings are that the best-performing Pre-trained Language Model (PLM), RoBERTa-base, has similar weighted F1 scores to Llama-3-70b-Chat on features with lower subjectivity, such as Relevant and Clear, with a mean difference of 2.17% in their weighted F1 scores. The models perform significantly better on features with higher subjectivity, such as Specific and Assertive, with a mean difference of 10.01% in their weighted F1 scores. Furthermore, testing SubjECTive-QA's generalizability using QAs from White House Press Briefings and Gaggles yields an average weighted F1 score of 65.97% using our best models for each feature, demonstrating broader applicability beyond the financial domain. SubjECTive-QA is publicly available under the CC BY 4.0 license
SIMBAR: Single Image-Based Scene Relighting For Effective Data Augmentation For Automated Driving Vision Tasks
Apr 01, 2022
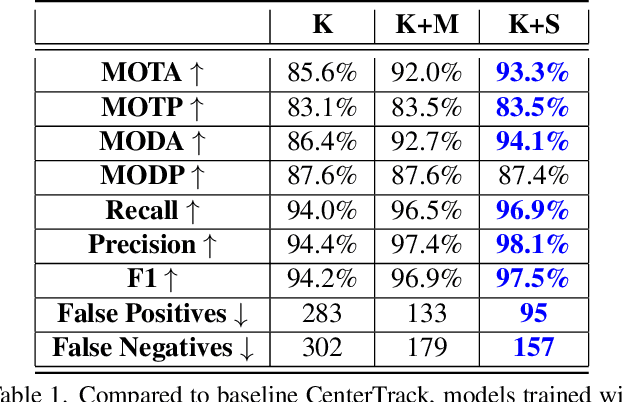
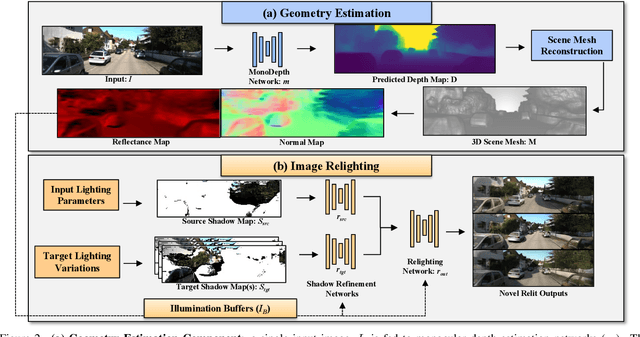
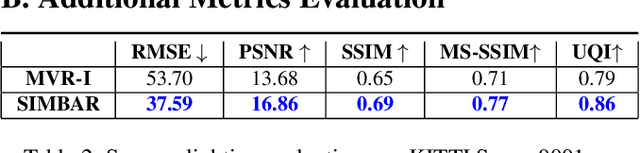
Real-world autonomous driving datasets comprise of images aggregated from different drives on the road. The ability to relight captured scenes to unseen lighting conditions, in a controllable manner, presents an opportunity to augment datasets with a richer variety of lighting conditions, similar to what would be encountered in the real-world. This paper presents a novel image-based relighting pipeline, SIMBAR, that can work with a single image as input. To the best of our knowledge, there is no prior work on scene relighting leveraging explicit geometric representations from a single image. We present qualitative comparisons with prior multi-view scene relighting baselines. To further validate and effectively quantify the benefit of leveraging SIMBAR for data augmentation for automated driving vision tasks, object detection and tracking experiments are conducted with a state-of-the-art method, a Multiple Object Tracking Accuracy (MOTA) of 93.3% is achieved with CenterTrack on SIMBAR-augmented KITTI - an impressive 9.0% relative improvement over the baseline MOTA of 85.6% with CenterTrack on original KITTI, both models trained from scratch and tested on Virtual KITTI. For more details and SIMBAR relit datasets, please visit our project website (https://simbarv1.github.io/).
Deflating Dataset Bias Using Synthetic Data Augmentation
Apr 28, 2020

Deep Learning has seen an unprecedented increase in vision applications since the publication of large-scale object recognition datasets and introduction of scalable compute hardware. State-of-the-art methods for most vision tasks for Autonomous Vehicles (AVs) rely on supervised learning and often fail to generalize to domain shifts and/or outliers. Dataset diversity is thus key to successful real-world deployment. No matter how big the size of the dataset, capturing long tails of the distribution pertaining to task-specific environmental factors is impractical. The goal of this paper is to investigate the use of targeted synthetic data augmentation - combining the benefits of gaming engine simulations and sim2real style transfer techniques - for filling gaps in real datasets for vision tasks. Empirical studies on three different computer vision tasks of practical use to AVs - parking slot detection, lane detection and monocular depth estimation - consistently show that having synthetic data in the training mix provides a significant boost in cross-dataset generalization performance as compared to training on real data only, for the same size of the training set.