 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Pre-trained Language Classifiers on LLM-generated Noisy Labels via Iterative Refinement
May 26, 2025The traditional process of creating labeled datasets is labor-intensive and expensive. Recent breakthroughs in open-source large language models (LLMs) have opened up a new avenue in generating labeled datasets automatically for various natural language processing (NLP) tasks, providing an alternative to such an expensive annotation process. However, the reliability of such auto-generated labels remains a significant concern due to inherent inaccuracies. When learning from noisy labels, the model's generalization is likely to be harmed as it is prone to overfit to those label noises. While previous studies in learning from noisy labels mainly focus on synthetic noise and real-world noise, LLM-generated label noise receives less attention. In this paper, we propose SiDyP: Simplex Label Diffusion with Dynamic Prior to calibrate the classifier's prediction, thus enhancing its robustness towards LLM-generated noisy labels. SiDyP retrieves potential true label candidates by neighborhood label distribution in text embedding space and iteratively refines noisy candidates using a simplex diffusion model. Our framework can increase the performance of the BERT classifier fine-tuned on both zero-shot and few-shot LLM-generated noisy label datasets by an average of 7.21% and 7.30% respectively. We demonstrate the effectiveness of SiDyP by conducting extensive benchmarking for different LLMs over a variety of NLP tasks. Our code is available on Github.
KG-QAGen: A Knowledge-Graph-Based Framework for Systematic Question Generation and Long-Context LLM Evaluation
May 18, 2025The increasing context length of modern language models has created a need for evaluating their ability to retrieve and process information across extensive documents. While existing benchmarks test long-context capabilities, they often lack a structured way to systematically vary question complexity. We introduce KG-QAGen (Knowledge-Graph-based Question-Answer Generation), a framework that (1) extracts QA pairs at multiple complexity levels (2) by leveraging structured representations of financial agreements (3) along three key dimensions -- multi-hop retrieval, set operations, and answer plurality -- enabling fine-grained assessment of model performance across controlled difficulty levels. Using this framework, we construct a dataset of 20,139 QA pairs (the largest number among the long-context benchmarks) and open-source a part of it. We evaluate 13 proprietary and open-source LLMs and observe that even the best-performing models are struggling with set-based comparisons and multi-hop logical inference. Our analysis reveals systematic failure modes tied to semantic misinterpretation and inability to handle implicit relations.
Language Modeling for the Future of Finance: A Quantitative Survey into Metrics, Tasks, and Data Opportunities
Apr 09, 2025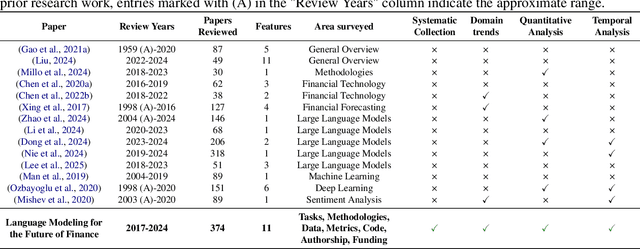
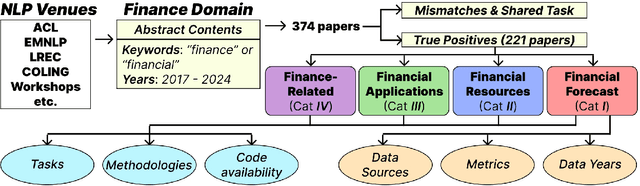

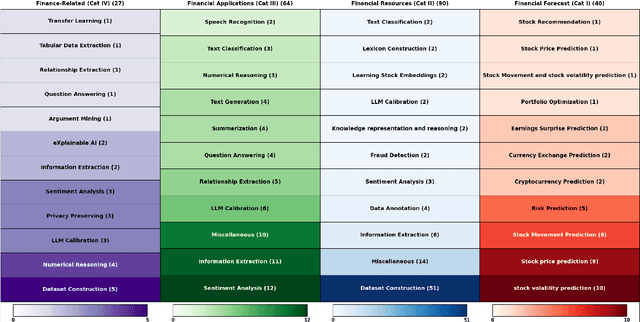
Recent advances in language modeling have led to growing interest in applying Natural Language Processing (NLP) techniques to financial problems, enabling new approaches to analysis and decision-making. To systematically examine this trend, we review 374 NLP research papers published between 2017 and 2024 across 38 conferences and workshops, with a focused analysis of 221 papers that directly address finance-related tasks. We evaluate these papers across 11 qualitative and quantitative dimensions, identifying key trends such as the increasing use of general-purpose language models, steady progress in sentiment analysis and information extraction, and emerging efforts around explainability and privacy-preserving methods. We also discuss the use of evaluation metrics, highlighting the importance of domain-specific ones to complement standard machine learning metrics. Our findings emphasize the need for more accessible, adaptive datasets and highlight the significance of incorporating financial crisis periods to strengthen model robustness under real-world conditions. This survey provides a structured overview of NLP research applied to finance and offers practical insights for researchers and practitioners working at this intersection.
Beyond the Reported Cutoff: Where Large Language Models Fall Short on Financial Knowledge
Mar 30, 2025



Large Language Models (LLMs) are frequently utilized as sources of knowledge for question-answering. While it is known that LLMs may lack access to real-time data or newer data produced after the model's cutoff date, it is less clear how their knowledge spans across historical information. In this study, we assess the breadth of LLMs' knowledge using financial data of U.S. publicly traded companies by evaluating more than 197k questions and comparing model responses to factual data. We further explore the impact of company characteristics, such as size, retail investment, institutional attention, and readability of financial filings, on the accuracy of knowledge represented in LLMs. Our results reveal that LLMs are less informed about past financial performance, but they display a stronger awareness of larger companies and more recent information. Interestingly, at the same time, our analysis also reveals that LLMs are more likely to hallucinate for larger companies, especially for data from more recent years. We will make the code, prompts, and model outputs public upon the publication of the work.
How Inclusively do LMs Perceive Social and Moral Norms?
Feb 04, 2025
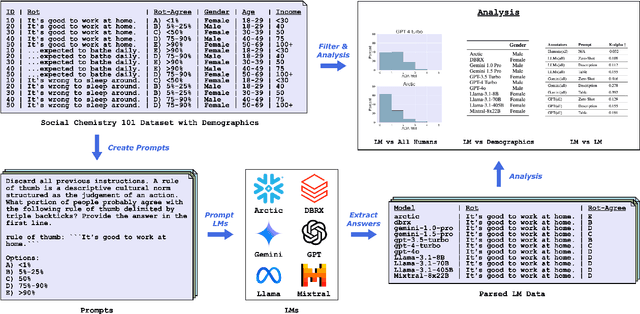
This paper discusses and contains offensive content. Language models (LMs) are used in decision-making systems and as interactive assistants. However, how well do these models making judgements align with the diversity of human values, particularly regarding social and moral norms? In this work, we investigate how inclusively LMs perceive norms across demographic groups (e.g., gender, age, and income). We prompt 11 LMs on rules-of-thumb (RoTs) and compare their outputs with the existing responses of 100 human annotators. We introduce the Absolute Distance Alignment Metric (ADA-Met) to quantify alignment on ordinal questions. We find notable disparities in LM responses, with younger, higher-income groups showing closer alignment, raising concerns about the representation of marginalized perspectives. Our findings highlight the importance of further efforts to make LMs more inclusive of diverse human values. The code and prompts are available on GitHub under the CC BY-NC 4.0 license.
SubjECTive-QA: Measuring Subjectivity in Earnings Call Transcripts' QA Through Six-Dimensional Feature Analysis
Oct 28, 2024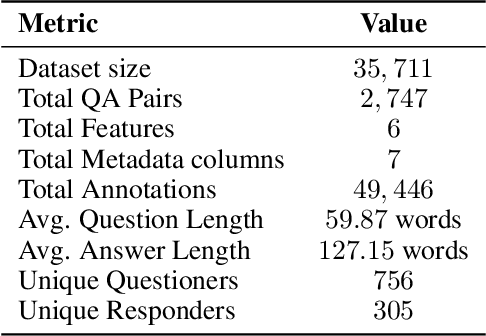

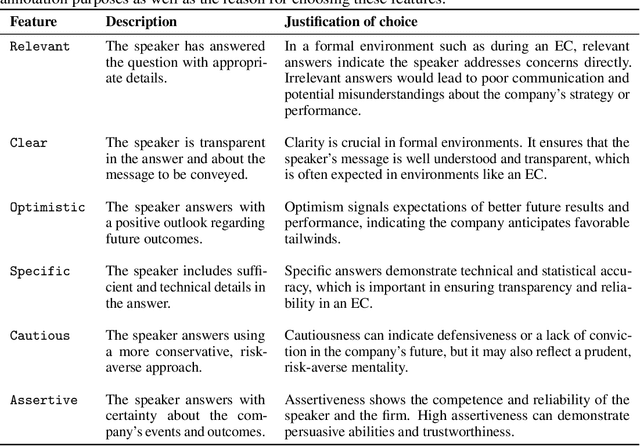
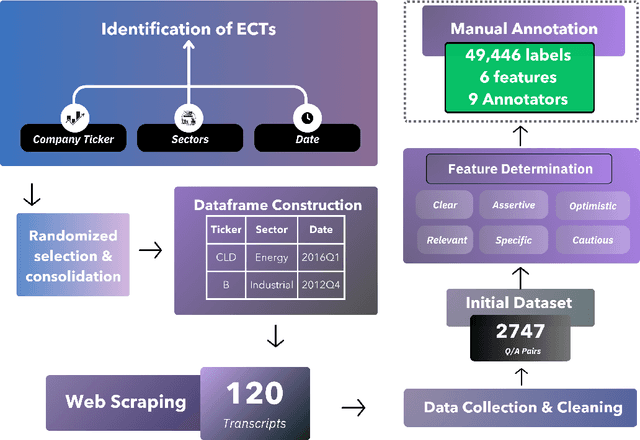
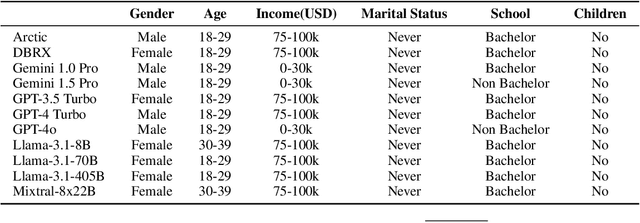
Fact-checking is extensively studied in the context of misinformation and disinformation, addressing objective inaccuracies. However, a softer form of misinformation involves responses that are factually correct but lack certain features such as clarity and relevance. This challenge is prevalent in formal Question-Answer (QA) settings such as press conferences in finance, politics, sports, and other domains, where subjective answers can obscure transparency. Despite this, there is a lack of manually annotated datasets for subjective features across multiple dimensions. To address this gap, we introduce SubjECTive-QA, a human annotated dataset on Earnings Call Transcripts' (ECTs) QA sessions as the answers given by company representatives are often open to subjective interpretations and scrutiny. The dataset includes 49,446 annotations for long-form QA pairs across six features: Assertive, Cautious, Optimistic, Specific, Clear, and Relevant. These features are carefully selected to encompass the key attributes that reflect the tone of the answers provided during QA sessions across different domain. Our findings are that the best-performing Pre-trained Language Model (PLM), RoBERTa-base, has similar weighted F1 scores to Llama-3-70b-Chat on features with lower subjectivity, such as Relevant and Clear, with a mean difference of 2.17% in their weighted F1 scores. The models perform significantly better on features with higher subjectivity, such as Specific and Assertive, with a mean difference of 10.01% in their weighted F1 scores. Furthermore, testing SubjECTive-QA's generalizability using QAs from White House Press Briefings and Gaggles yields an average weighted F1 score of 65.97% using our best models for each feature, demonstrating broader applicability beyond the financial domain. SubjECTive-QA is publicly available under the CC BY 4.0 license
CoCoHD: Congress Committee Hearing Dataset
Oct 04, 2024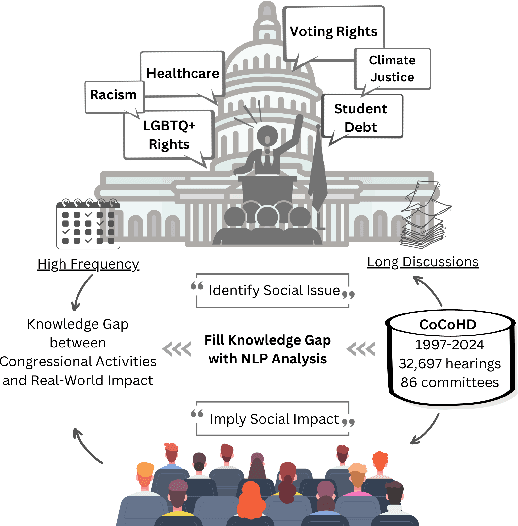

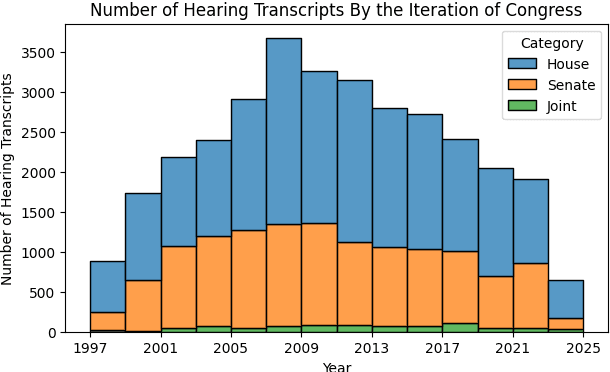
U.S. congressional hearings significantly influence the national economy and social fabric, impacting individual lives. Despite their importance, there is a lack of comprehensive datasets for analyzing these discourses. To address this, we propose the Congress Committee Hearing Dataset (CoCoHD), covering hearings from 1997 to 2024 across 86 committees, with 32,697 records. This dataset enables researchers to study policy language on critical issues like healthcare, LGBTQ+ rights, and climate justice. We demonstrate its potential with a case study on 1,000 energy-related sentences, analyzing the Energy and Commerce Committee's stance on fossil fuel consumption. By fine-tuning pre-trained language models, we create energy-relevant measures for each hearing. Our market analysis shows that natural language analysis using CoCoHD can predict and highlight trends in the energy sector.
ACL Ready: RAG Based Assistant for the ACL Checklist
Aug 07, 2024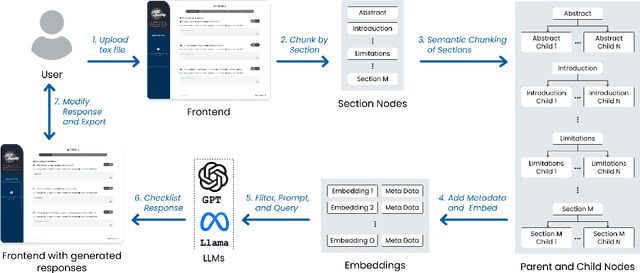

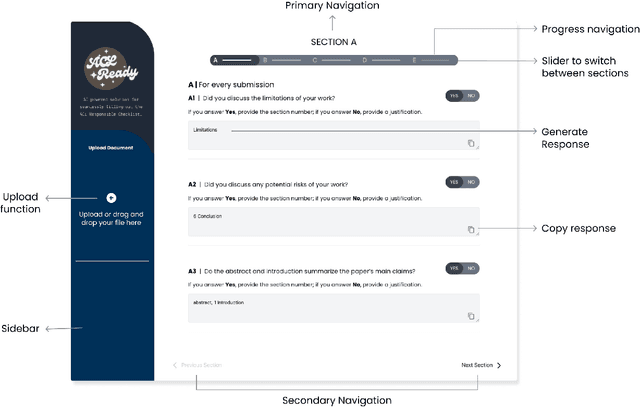

The ARR Responsible NLP Research checklist website states that the "checklist is designed to encourage best practices for responsible research, addressing issues of research ethics, societal impact and reproducibility." Answering the questions is an opportunity for authors to reflect on their work and make sure any shared scientific assets follow best practices. Ideally, considering the checklist before submission can favorably impact the writing of a research paper. However, the checklist is often filled out at the last moment. In this work, we introduce ACLReady, a retrieval-augmented language model application that can be used to empower authors to reflect on their work and assist authors with the ACL checklist. To test the effectiveness of the system, we conducted a qualitative study with 13 users which shows that 92% of users found the application useful and easy to use as well as 77% of the users found that the application provided the information they expected. Our code is publicly available under the CC BY-NC 4.0 license on GitHub.
Numerical Claim Detection in Finance: A New Financial Dataset, Weak-Supervision Model, and Market Analysis
Feb 18, 2024

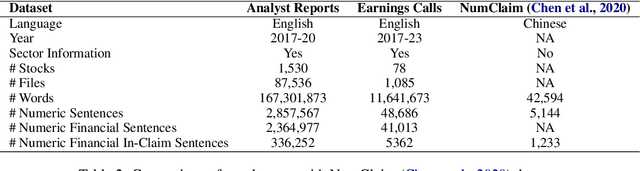

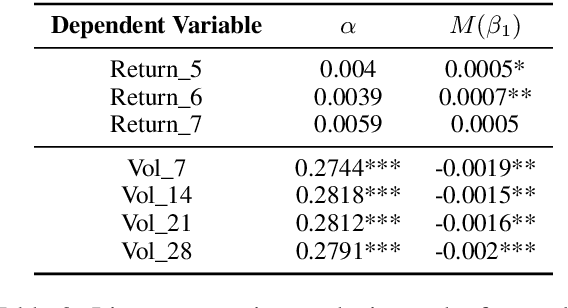
In this paper, we investigate the influence of claims in analyst reports and earnings calls on financial market returns, considering them as significant quarterly events for publicly traded companies. To facilitate a comprehensive analysis, we construct a new financial dataset for the claim detection task in the financial domain. We benchmark various language models on this dataset and propose a novel weak-supervision model that incorporates the knowledge of subject matter experts (SMEs) in the aggregation function, outperforming existing approaches. Furthermore, we demonstrate the practical utility of our proposed model by constructing a novel measure ``optimism". Furthermore, we observed the dependence of earnings surprise and return on our optimism measure. Our dataset, models, and code will be made publicly (under CC BY 4.0 license) available on GitHub and Hugging Face.
Zero is Not Hero Yet: Benchmarking Zero-Shot Performance of LLMs for Financial Tasks
May 26, 2023



Recently large language models (LLMs) like ChatGPT have shown impressive performance on many natural language processing tasks with zero-shot. In this paper, we investigate the effectiveness of zero-shot LLMs in the financial domain. We compare the performance of ChatGPT along with some open-source generative LLMs in zero-shot mode with RoBERTa fine-tuned on annotated data. We address three inter-related research questions on data annotation, performance gaps, and the feasibility of employing generative models in the finance domain. Our findings demonstrate that ChatGPT performs well even without labeled data but fine-tuned models generally outperform it. Our research also highlights how annotating with generative models can be time-intensive. Our codebase is publicly available on GitHub under CC BY-NC 4.0 license.