 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Modeling for the Future of Finance: A Quantitative Survey into Metrics, Tasks, and Data Opportunities
Apr 09, 2025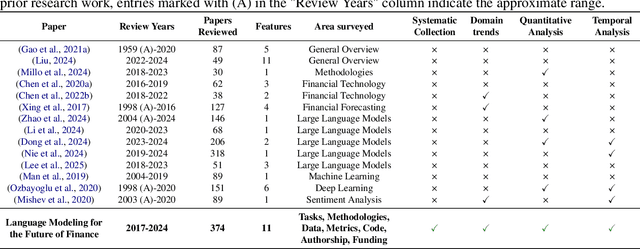
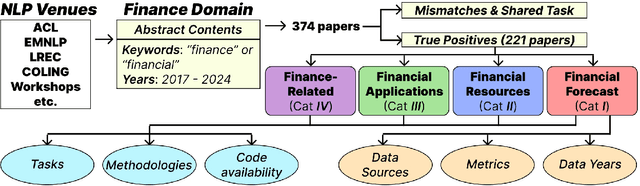

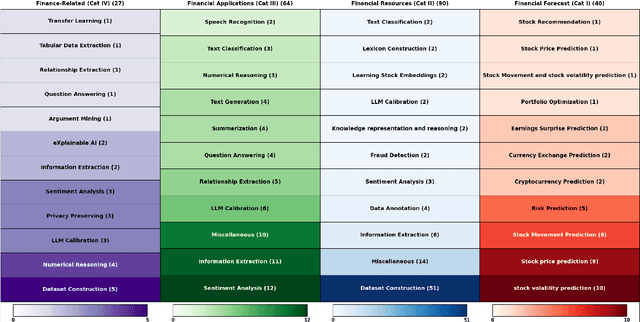
Recent advances in language modeling have led to growing interest in applying Natural Language Processing (NLP) techniques to financial problems, enabling new approaches to analysis and decision-making. To systematically examine this trend, we review 374 NLP research papers published between 2017 and 2024 across 38 conferences and workshops, with a focused analysis of 221 papers that directly address finance-related tasks. We evaluate these papers across 11 qualitative and quantitative dimensions, identifying key trends such as the increasing use of general-purpose language models, steady progress in sentiment analysis and information extraction, and emerging efforts around explainability and privacy-preserving methods. We also discuss the use of evaluation metrics, highlighting the importance of domain-specific ones to complement standard machine learning metrics. Our findings emphasize the need for more accessible, adaptive datasets and highlight the significance of incorporating financial crisis periods to strengthen model robustness under real-world conditions. This survey provides a structured overview of NLP research applied to finance and offers practical insights for researchers and practitioners working at this intersection.
SubjECTive-QA: Measuring Subjectivity in Earnings Call Transcripts' QA Through Six-Dimensional Feature Analysis
Oct 28, 2024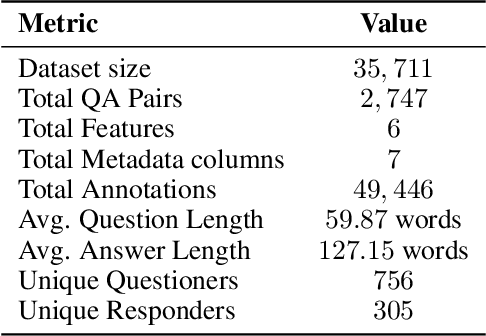

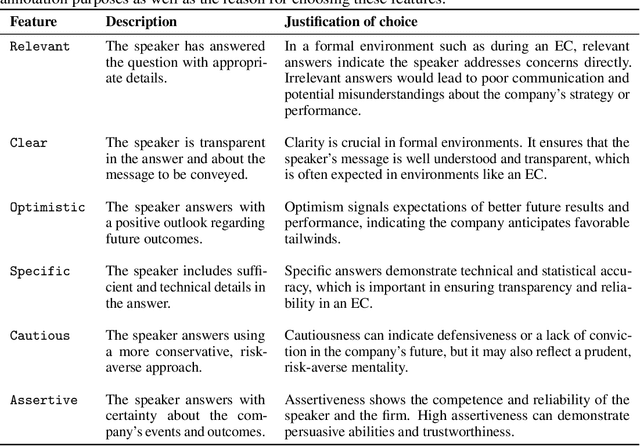
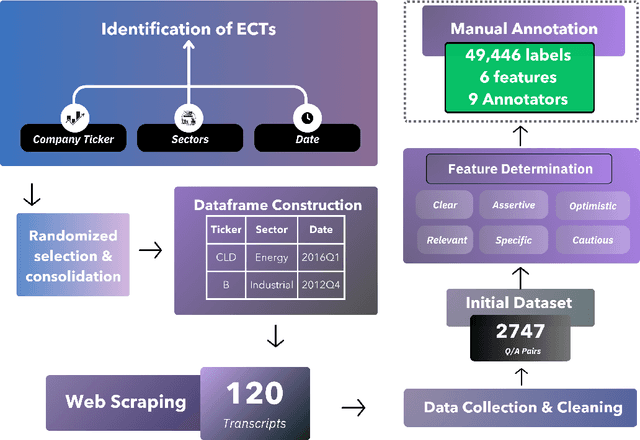
Fact-checking is extensively studied in the context of misinformation and disinformation, addressing objective inaccuracies. However, a softer form of misinformation involves responses that are factually correct but lack certain features such as clarity and relevance. This challenge is prevalent in formal Question-Answer (QA) settings such as press conferences in finance, politics, sports, and other domains, where subjective answers can obscure transparency. Despite this, there is a lack of manually annotated datasets for subjective features across multiple dimensions. To address this gap, we introduce SubjECTive-QA, a human annotated dataset on Earnings Call Transcripts' (ECTs) QA sessions as the answers given by company representatives are often open to subjective interpretations and scrutiny. The dataset includes 49,446 annotations for long-form QA pairs across six features: Assertive, Cautious, Optimistic, Specific, Clear, and Relevant. These features are carefully selected to encompass the key attributes that reflect the tone of the answers provided during QA sessions across different domain. Our findings are that the best-performing Pre-trained Language Model (PLM), RoBERTa-base, has similar weighted F1 scores to Llama-3-70b-Chat on features with lower subjectivity, such as Relevant and Clear, with a mean difference of 2.17% in their weighted F1 scores. The models perform significantly better on features with higher subjectivity, such as Specific and Assertive, with a mean difference of 10.01% in their weighted F1 scores. Furthermore, testing SubjECTive-QA's generalizability using QAs from White House Press Briefings and Gaggles yields an average weighted F1 score of 65.97% using our best models for each feature, demonstrating broader applicability beyond the financial domain. SubjECTive-QA is publicly available under the CC BY 4.0 license