 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Spherical Flow Policy for Reinforcement Learning with Combinatorial Actions
Jan 29, 2026Reinforcement learning (RL) with combinatorial action spaces remains challenging because feasible action sets are exponentially large and governed by complex feasibility constraints, making direct policy parameterization impractical. Existing approaches embed task-specific value functions into constrained optimization programs or learn deterministic structured policies, sacrificing generality and policy expressiveness. We propose a solver-induced \emph{latent spherical flow policy} that brings the expressiveness of modern generative policies to combinatorial RL while guaranteeing feasibility by design. Our method, LSFlow, learns a \emph{stochastic} policy in a compact continuous latent space via spherical flow matching, and delegates feasibility to a combinatorial optimization solver that maps each latent sample to a valid structured action. To improve efficiency, we train the value network directly in the latent space, avoiding repeated solver calls during policy optimization. To address the piecewise-constant and discontinuous value landscape induced by solver-based action selection, we introduce a smoothed Bellman operator that yields stable, well-defined learning targets. Empirically, our approach outperforms state-of-the-art baselines by an average of 20.6\% across a range of challenging combinatorial RL tasks.
LLM Review: Enhancing Creative Writing via Blind Peer Review Feedback
Jan 12, 2026Large Language Models (LLMs) often struggle with creative generation, and multi-agent frameworks that improve reasoning through interaction can paradoxically hinder creativity by inducing content homogenization. We introduce LLM Review, a peer-review-inspired framework implementing Blind Peer Review: agents exchange targeted feedback while revising independently, preserving divergent creative trajectories. To enable rigorous evaluation, we propose SciFi-100, a science fiction writing dataset with a unified framework combining LLM-as-a-judge scoring, human annotation, and rule-based novelty metrics. Experiments demonstrate that LLM Review consistently outperforms multi-agent baselines, and smaller models with our framework can surpass larger single-agent models, suggesting interaction structure may substitute for model scale.
CoCoHD: Congress Committee Hearing Dataset
Oct 04, 2024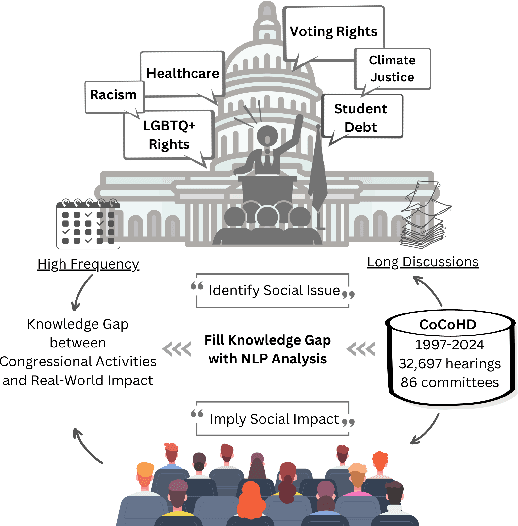

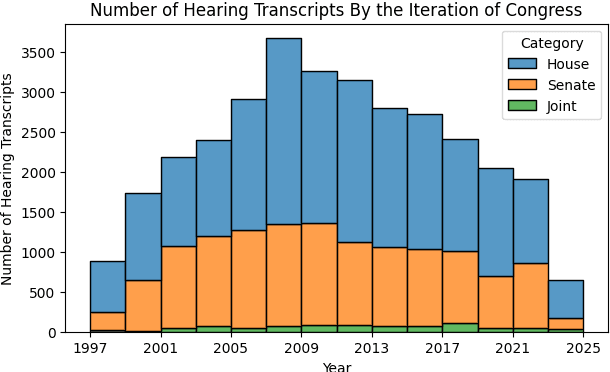
U.S. congressional hearings significantly influence the national economy and social fabric, impacting individual lives. Despite their importance, there is a lack of comprehensive datasets for analyzing these discourses. To address this, we propose the Congress Committee Hearing Dataset (CoCoHD), covering hearings from 1997 to 2024 across 86 committees, with 32,697 records. This dataset enables researchers to study policy language on critical issues like healthcare, LGBTQ+ rights, and climate justice. We demonstrate its potential with a case study on 1,000 energy-related sentences, analyzing the Energy and Commerce Committee's stance on fossil fuel consumption. By fine-tuning pre-trained language models, we create energy-relevant measures for each hearing. Our market analysis shows that natural language analysis using CoCoHD can predict and highlight trends in the energy sector.