 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Review: Enhancing Creative Writing via Blind Peer Review Feedback
Jan 12, 2026Large Language Models (LLMs) often struggle with creative generation, and multi-agent frameworks that improve reasoning through interaction can paradoxically hinder creativity by inducing content homogenization. We introduce LLM Review, a peer-review-inspired framework implementing Blind Peer Review: agents exchange targeted feedback while revising independently, preserving divergent creative trajectories. To enable rigorous evaluation, we propose SciFi-100, a science fiction writing dataset with a unified framework combining LLM-as-a-judge scoring, human annotation, and rule-based novelty metrics. Experiments demonstrate that LLM Review consistently outperforms multi-agent baselines, and smaller models with our framework can surpass larger single-agent models, suggesting interaction structure may substitute for model scale.
Grading Scale Impact on LLM-as-a-Judge: Human-LLM Alignment Is Highest on 0-5 Grading Scale
Jan 06, 2026Large language models (LLMs) are increasingly used as automated evaluators, yet prior works demonstrate that these LLM judges often lack consistency in scoring when the prompt is altered. However, the effect of the grading scale itself remains underexplored. We study the LLM-as-a-judge problem by comparing two kinds of raters: humans and LLMs. We collect ratings from both groups on three scales and across six benchmarks that include objective, open-ended subjective, and mixed tasks. Using intraclass correlation coefficients (ICC) to measure absolute agreement, we find that LLM judgments are not perfectly consistent across scales on subjective benchmarks, and that the choice of scale substantially shifts human-LLM agreement, even when within-group panel reliability is high. Aggregated over tasks, the grading scale of 0-5 yields the strongest human-LLM alignment. We further demonstrate that pooled reliability can mask benchmark heterogeneity and reveal systematic subgroup differences in alignment across gender groups, strengthening the importance of scale design and sub-level diagnostics as essential components of LLM-as-a-judge protocols.
CONCUR: A Framework for Continual Constrained and Unconstrained Routing
Dec 10, 2025AI tasks differ in complexity and are best addressed with different computation strategies (e.g., combinations of models and decoding methods). Hence, an effective routing system that maps tasks to the appropriate strategies is crucial. Most prior methods build the routing framework by training a single model across all strategies, which demands full retraining whenever new strategies appear and leads to high overhead. Attempts at such continual routing, however, often face difficulties with generalization. Prior models also typically use a single input representation, limiting their ability to capture the full complexity of the routing problem and leading to sub-optimal routing decisions. To address these gaps, we propose CONCUR, a continual routing framework that supports both constrained and unconstrained routing (i.e., routing with or without a budget). Our modular design trains a separate predictor model for each strategy, enabling seamless incorporation of new strategies with low additional training cost. Our predictors also leverage multiple representations of both tasks and computation strategies to better capture overall problem complexity. Experiments on both in-distribution and out-of-distribution, knowledge- and reasoning-intensive tasks show that our method outperforms the best single strategy and strong existing routing techniques with higher end-to-end accuracy and lower inference cost in both continual and non-continual settings, while also reducing training cost in the continual setting.
BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions
Aug 19, 2023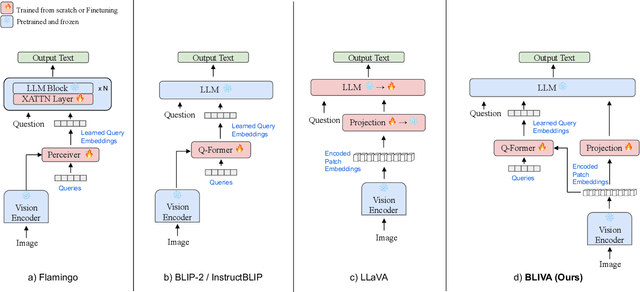



Vision Language Models (VLMs), which extend Large Language Models (LLM) by incorporating visual understanding capability, have demonstrated significant advancements in addressing open-ended visual question-answering (VQA) tasks. However, these models cannot accurately interpret images infused with text, a common occurrence in real-world scenarios. Standard procedures for extracting information from images often involve learning a fixed set of query embeddings. These embeddings are designed to encapsulate image contexts and are later used as soft prompt inputs in LLMs. Yet, this process is limited to the token count, potentially curtailing the recognition of scenes with text-rich context. To improve upon them, the present study introduces BLIVA: an augmented version of InstructBLIP with Visual Assistant. BLIVA incorporates the query embeddings from InstructBLIP and also directly projects encoded patch embeddings into the LLM, a technique inspired by LLaVA. This approach assists the model to capture intricate details potentially missed during the query decoding process. Empirical evidence demonstrates that our model, BLIVA, significantly enhances performance in processing text-rich VQA benchmarks (up to 17.76\% in OCR-VQA benchmark) and in undertaking typical VQA benchmarks (up to 7.9\% in Visual Spatial Reasoning benchmark), comparing to our baseline InstructBLIP. BLIVA demonstrates significant capability in decoding real-world images, irrespective of text presence. To demonstrate the broad industry applications enabled by BLIVA, we evaluate the model using a new dataset comprising YouTube thumbnails paired with question-answer sets across 13 diverse categories. For researchers interested in further exploration, our code and models are freely accessible at https://github.com/mlpc-ucsd/BLIVA.git