 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrading Scale Impact on LLM-as-a-Judge: Human-LLM Alignment Is Highest on 0-5 Grading Scale
Jan 06, 2026Large language models (LLMs) are increasingly used as automated evaluators, yet prior works demonstrate that these LLM judges often lack consistency in scoring when the prompt is altered. However, the effect of the grading scale itself remains underexplored. We study the LLM-as-a-judge problem by comparing two kinds of raters: humans and LLMs. We collect ratings from both groups on three scales and across six benchmarks that include objective, open-ended subjective, and mixed tasks. Using intraclass correlation coefficients (ICC) to measure absolute agreement, we find that LLM judgments are not perfectly consistent across scales on subjective benchmarks, and that the choice of scale substantially shifts human-LLM agreement, even when within-group panel reliability is high. Aggregated over tasks, the grading scale of 0-5 yields the strongest human-LLM alignment. We further demonstrate that pooled reliability can mask benchmark heterogeneity and reveal systematic subgroup differences in alignment across gender groups, strengthening the importance of scale design and sub-level diagnostics as essential components of LLM-as-a-judge protocols.
EvidenceBench: A Benchmark for Extracting Evidence from Biomedical Papers
Apr 25, 2025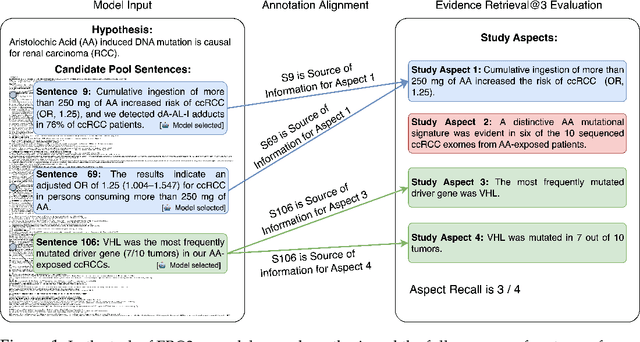



We study the task of automatically finding evidence relevant to hypotheses in biomedical papers. Finding relevant evidence is an important step when researchers investigate scientific hypotheses. We introduce EvidenceBench to measure models performance on this task, which is created by a novel pipeline that consists of hypothesis generation and sentence-by-sentence annotation of biomedical papers for relevant evidence, completely guided by and faithfully following existing human experts judgment. We demonstrate the pipeline's validity and accuracy with multiple sets of human-expert annotations. We evaluated a diverse set of language models and retrieval systems on the benchmark and found that model performances still fall significantly short of the expert level on this task. To show the scalability of our proposed pipeline, we create a larger EvidenceBench-100k with 107,461 fully annotated papers with hypotheses to facilitate model training and development. Both datasets are available at https://github.com/EvidenceBench/EvidenceBench
Measuring Risk of Bias in Biomedical Reports: The RoBBR Benchmark
Nov 28, 2024



Systems that answer questions by reviewing the scientific literature are becoming increasingly feasible. To draw reliable conclusions, these systems should take into account the quality of available evidence, placing more weight on studies that use a valid methodology. We present a benchmark for measuring the methodological strength of biomedical papers, drawing on the risk-of-bias framework used for systematic reviews. The four benchmark tasks, drawn from more than 500 papers, cover the analysis of research study methodology, followed by evaluation of risk of bias in these studies. The benchmark contains 2000 expert-generated bias annotations, and a human-validated pipeline for fine-grained alignment with research paper content. We evaluate a range of large language models on the benchmark, and find that these models fall significantly short of expert-level performance. By providing a standardized tool for measuring judgments of study quality, the benchmark can help to guide systems that perform large-scale aggregation of scientific data. The dataset is available at https://github.com/RoBBR-Benchmark/RoBBR.
IR2: Information Regularization for Information Retrieval
Feb 25, 2024



Effective information retrieval (IR) in settings with limited training data, particularly for complex queries, remains a challenging task. This paper introduces IR2, Information Regularization for Information Retrieval, a technique for reducing overfitting during synthetic data generation. This approach, representing a novel application of regularization techniques in synthetic data creation for IR, is tested on three recent IR tasks characterized by complex queries: DORIS-MAE, ArguAna, and WhatsThatBook. Experimental results indicate that our regularization techniques not only outperform previous synthetic query generation methods on the tasks considered but also reduce cost by up to 50%. Furthermore, this paper categorizes and explores three regularization methods at different stages of the query synthesis pipeline-input, prompt, and output-each offering varying degrees of performance improvement compared to models where no regularization is applied. This provides a systematic approach for optimizing synthetic data generation in data-limited, complex-query IR scenarios. All code, prompts and synthetic data are available at https://github.com/Info-Regularization/Information-Regularization.
BIRCO: A Benchmark of Information Retrieval Tasks with Complex Objectives
Feb 21, 2024We present the Benchmark of Information Retrieval (IR) tasks with Complex Objectives (BIRCO). BIRCO evaluates the ability of IR systems to retrieve documents given multi-faceted user objectives. The benchmark's complexity and compact size make it suitable for evaluating large language model (LLM)-based information retrieval systems. We present a modular framework for investigating factors that may influence LLM performance on retrieval tasks, and identify a simple baseline model which matches or outperforms existing approaches and more complex alternatives. No approach achieves satisfactory performance on all benchmark tasks, suggesting that stronger models and new retrieval protocols are necessary to address complex user needs.
IBADR: an Iterative Bias-Aware Dataset Refinement Framework for Debiasing NLU models
Nov 01, 2023



As commonly-used methods for debiasing natural language understanding (NLU) models, dataset refinement approaches heavily rely on manual data analysis, and thus maybe unable to cover all the potential biased features. In this paper, we propose IBADR, an Iterative Bias-Aware Dataset Refinement framework, which debiases NLU models without predefining biased features. We maintain an iteratively expanded sample pool. Specifically, at each iteration, we first train a shallow model to quantify the bias degree of samples in the pool. Then, we pair each sample with a bias indicator representing its bias degree, and use these extended samples to train a sample generator. In this way, this generator can effectively learn the correspondence relationship between bias indicators and samples. Furthermore, we employ the generator to produce pseudo samples with fewer biased features by feeding specific bias indicators. Finally, we incorporate the generated pseudo samples into the pool. Experimental results and in-depth analyses on two NLU tasks show that IBADR not only significantly outperforms existing dataset refinement approaches, achieving SOTA, but also is compatible with model-centric methods.
DORIS-MAE: Scientific Document Retrieval using Multi-level Aspect-based Queries
Oct 10, 2023In scientific research, the ability to effectively retrieve relevant documents based on complex, multifaceted queries is critical. Existing evaluation datasets for this task are limited, primarily due to the high cost and effort required to annotate resources that effectively represent complex queries. To address this, we propose a novel task, Scientific DOcument Retrieval using Multi-level Aspect-based quEries (DORIS-MAE), which is designed to handle the complex nature of user queries in scientific research. We developed a benchmark dataset within the field of computer science, consisting of 100 human-authored complex query cases. For each complex query, we assembled a collection of 100 relevant documents and produced annotated relevance scores for ranking them. Recognizing the significant labor of expert annotation, we also introduce Anno-GPT, a scalable framework for validating the performance of Large Language Models (LLMs) on expert-level dataset annotation tasks. LLM annotation of the DORIS-MAE dataset resulted in a 500x reduction in cost, without compromising quality. Furthermore, due to the multi-tiered structure of these complex queries, the DORIS-MAE dataset can be extended to over 4,000 sub-query test cases without requiring additional annotation. We evaluated 17 recent retrieval methods on DORIS-MAE, observing notable performance drops compared to traditional datasets. This highlights the need for better approaches to handle complex, multifaceted queries in scientific research. Our dataset and codebase are available at https://github.com/Real-Doris-Mae/Doris-Mae-Dataset.
A Simple yet Effective Self-Debiasing Framework for Transformer Models
Jun 02, 2023
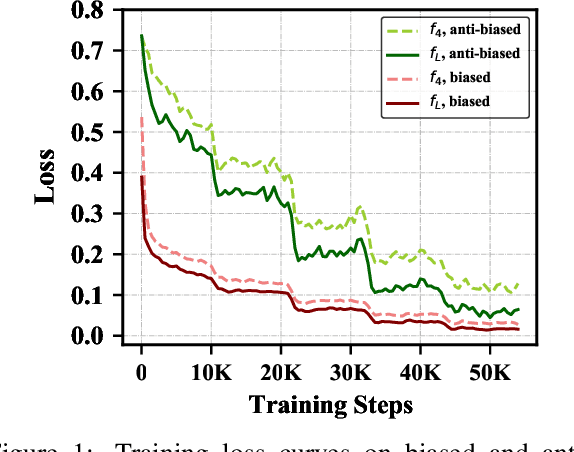
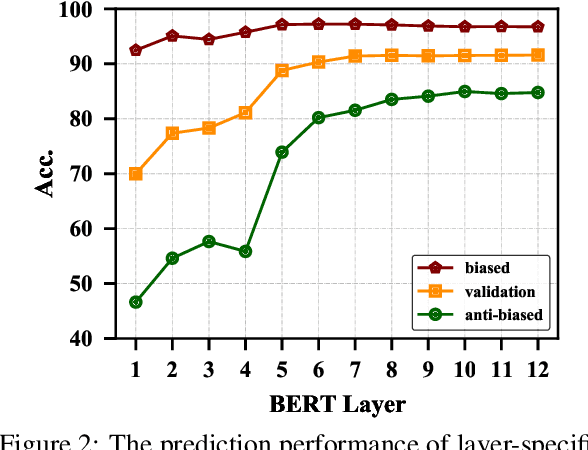

Current Transformer-based natural language understanding (NLU) models heavily rely on dataset biases, while failing to handle real-world out-of-distribution (OOD) instances. Many methods have been proposed to deal with this issue, but they ignore the fact that the features learned in different layers of Transformer-based NLU models are different. In this paper, we first conduct preliminary studies to obtain two conclusions: 1) both low- and high-layer sentence representations encode common biased features during training; 2) the low-layer sentence representations encode fewer unbiased features than the highlayer ones. Based on these conclusions, we propose a simple yet effective self-debiasing framework for Transformer-based NLU models. Concretely, we first stack a classifier on a selected low layer. Then, we introduce a residual connection that feeds the low-layer sentence representation to the top-layer classifier. In this way, the top-layer sentence representation will be trained to ignore the common biased features encoded by the low-layer sentence representation and focus on task-relevant unbiased features. During inference, we remove the residual connection and directly use the top-layer sentence representation to make predictions. Extensive experiments and indepth analyses on NLU tasks show that our framework performs better than several competitive baselines, achieving a new SOTA on all OOD test sets.
Getting the Most out of Simile Recognition
Nov 11, 2022
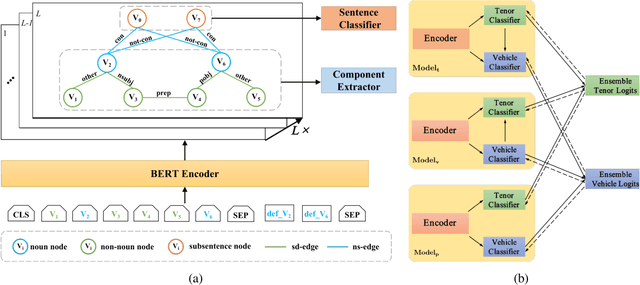
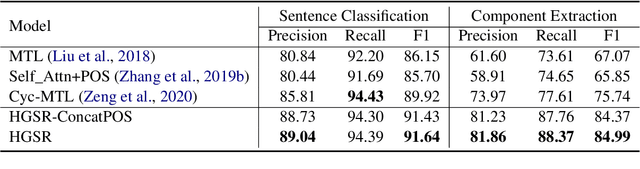
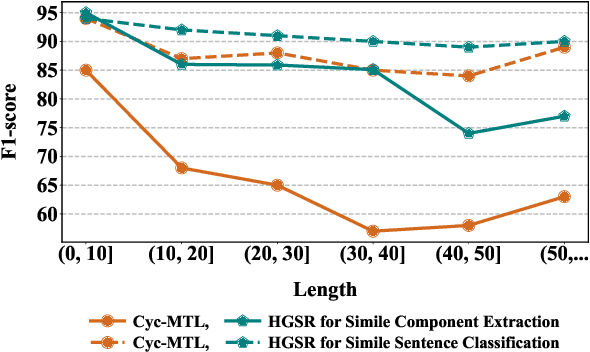
Simile recognition involves two subtasks: simile sentence classification that discriminates whether a sentence contains simile, and simile component extraction that locates the corresponding objects (i.e., tenors and vehicles). Recent work ignores features other than surface strings. In this paper, we explore expressive features for this task to achieve more effective data utilization. Particularly, we study two types of features: 1) input-side features that include POS tags, dependency trees and word definitions, and 2) decoding features that capture the interdependence among various decoding decisions. We further construct a model named HGSR, which merges the input-side features as a heterogeneous graph and leverages decoding features via distillation. Experiments show that HGSR significantly outperforms the current state-of-the-art systems and carefully designed baselines, verifying the effectiveness of introduced features. Our code is available at https://github.com/DeepLearnXMU/HGSR.
Experimental Comparison of Representation Methods and Distance Measures for Time Series Data
Dec 09, 2010
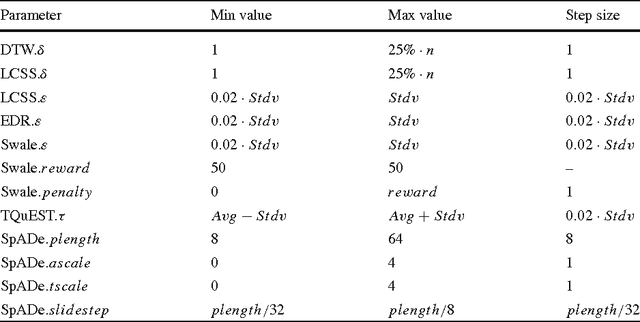

The previous decade has brought a remarkable increase of the interest in applications that deal with querying and mining of time series data. Many of the research efforts in this context have focused on introducing new representation methods for dimensionality reduction or novel similarity measures for the underlying data. In the vast majority of cases, each individual work introducing a particular method has made specific claims and, aside from the occasional theoretical justifications, provided quantitative experimental observations. However, for the most part, the comparative aspects of these experiments were too narrowly focused on demonstrating the benefits of the proposed methods over some of the previously introduced ones. In order to provide a comprehensive validation, we conducted an extensive experimental study re-implementing eight different time series representations and nine similarity measures and their variants, and testing their effectiveness on thirty-eight time series data sets from a wide variety of application domains. In this paper, we give an overview of these different techniques and present our comparative experimental findings regarding their effectiveness. In addition to providing a unified validation of some of the existing achievements, our experiments also indicate that, in some cases, certain claims in the literature may be unduly optimistic.